이번 학기에 머신러닝이라는 전공수업을 듣게 됬다. 저번학기 부터 관심이 간 분야지만 사실 이전에는 공부하면서 등장하는 개념을 알긴 아는 것 같은데 남에게 확실히 뭐라고 설명할 수 있을 정도로 지식의 깊이가 깊지 않았다.
이번학기 수업을 기반으로 해서 시험공부 뿐만 아니라 머신러닝의 기초를 다잡기 위해서 블로그 포스팅을 이용해보려고 한다. 개인적인 공부습관이 시험공부를 하기 위해서는 따로 연습장에 나만의 필기를 무조건 하는 스타일이라서 중간 중간 애매모호한 개념을 직관적으로 이해하기 위해서 필기 그림을 이용하는 것은 이해해 주길...
요즘 코로나로 인해서 아쉽게도 사이버강의로 진행하지만 최대한 따라가기 위해서 갓 구글링의 도움을 빌려가며 같이 공부하고 있다. 오늘은 첫 포스팅으로 머신러닝의 종류와 용어개념에 대해서 알아보자. 아직 수업 초반부이기 때문에 뒤로 가면서 등장하는 개념의 설명 깊이가 그렇게 깊진 않을 수도 있다. 아마 강의가 진행되면서 개념에 대한 학습 깊이가 깊어질 예정이다. 목차는 다음과 같다.
- 머신러닝의 종류
- Feature란? Attribute 와 다른가?
- Model 개념
- Model 평가
- Model의 학습 알고리즘
- 데이터를 어떻게 샘플링할 것인가?
1. 머신러닝의 종류

- 지도학습(Supervised Learning) : 정답이 주어진 데이터를 모델이 학습하는 것으로 주로 Classification(분류)에 사용된다. 예시 모델로는 Decision Tree, ANN(인공신경망), SVM(Support Vector Machine) 등이 있다.
- 비지도학습(Unsupervised Learning) : 정답을 알려주지 않고 같은 것 끼리 모델이 묶어서(Clustering) 학습을 한다. 모델학습에 정답이 필요가 없다. 단지 데이터만 있으면 학습이 가능하다. 예시 모델로는 Hierarchial Clustering(계층군집화), K-means Clustering 등이 있다. (단, 비지도학습도 최종적인 단계에서 모델 성능평가를 위해서는 정답이 있는 데이터가 필요하긴 하다.)
- 반지도학습(Semi-Supervised Learning) : 위 그림에는 없지만 반지도 학습이라는 것이 존재한다. 즉, 정답 데이터는 있지만 모델에는 정답을 알려주지 않고 기계가 직접 군집화 하도록 시키는 것이다. 이 학습방법은 "정답이 없는 데이터가 모델이 학습하는 데 도움이 될 거다" 라는 것을 가정한다.
- 강화학습(Reinforcement) : 모델(기계)가 행동을 하고 행동에 대한 보상 또는 패널티를 받음으로써 더 큰 보상을 얻는 방향으로 학습을 진행한다. 예시로는 2016년 가장 핫했다고 볼 수 있는 알파고
2. Feature란? Attribute 와 다른가?
결론적으로 Feature와 Attribute는 똑같은 개념이다. 사람들이 혼용해 부르기도 한다. Feature은 여러가지 데이터 타입(type)이 될 수 있다. 예를들어, Categorical(Nominal)이라 부르는 범주형 데이터, String(문자열), Number(숫자) 가 될 수 있다.
그렇다면 Feature의 갯수는 어느정도가 적당할까? 우선 분류문제에서는 label(class)갯수 < Feature 갯수 < Data 갯수
가 되는 것이 일반적이다. 그러면 Feature 갯수를 무작정 늘린다면 과연 어떻게 될까? 차원의 저주 에 걸리게 된다.
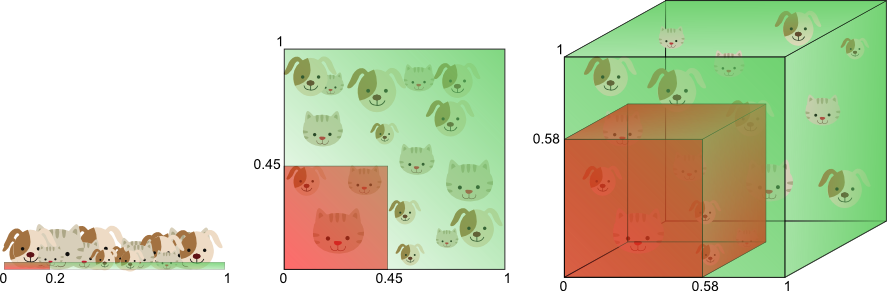
기본적으로 Feature의 갯수가 늘어나기 시작하면 그 만큼 차원이 증가한다. 하나의 차원이 증가할 때마다 데이터에 대한 조합의 갯수가 기하급수적(Exponential)으로 증가하게 된다. 그렇게 되면 학습을 위한 추가적인 데이터가 필요하게 된다.
그러면 차원에 비해 데이터 개수가 너무 적다면 어떻게 될까? 그 땐 바로 Overfitting(과적합)이라는 문제가 발생한다.
또한 Feature를 잘 정의하기 위해서는 머신러닝 모델을 적용하려고 하는 해당 분야의 지식 즉, 도메인 전문지식이 요구된다.
그런데 만약 도메인 전문지식을 얻기가 너무 힘들다면 어떻게 할까? 이 때 바로 딥러닝이라는 개념이 등장한다. 딥러닝은 머신러닝처럼 Feature을 굳이 정의하지 않아도 데이터들에 기반해 Feature을 스스로 찾아 스스로 학습하게 된다. 다시 말해, Feature를 정의하는 데 노력이 들지 않는다는 것이다. 그렇지만 세상에 공짜가 없듯이, 딥러닝을 하기 위해서는 대신 딥러닝 모델의 노드(Node)갯수나 여러가지 학습방법 중 어떤 방법을 사용할지에 대한 선별능력을 갖추기 위한 지식이 필요하다.
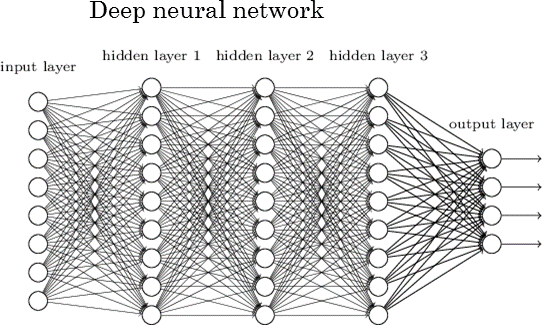
3. Model 개념
그렇다면 모델이란 무엇일까? 우리는 이것을 '가설(Hypothesis)'이라고도 부를 수 있으며 "데이터를 통해 배운다" 라고 할 수 있다. 모델을 선정하기 위해서는 우선 데이터를 시각화 하여 데이터들 간에 어떤 패턴과 규칙이 있는지 눈으로 직접 관찰해본다. 그리고 다양한 모델을 적용해보고 성능 비교를 통해 가장 적합한 모델을 선정한다.
우리는 모델 선정 시 두 가지 개념을 고려할 수 있는데 바로 Complexity(복잡성)과 Data(Sample Consistency)이다.
- Complexity : 데이터 수가 증가함에 따라 Computational Operation(컴퓨팅연산)이 얼마나 증가하는지 이다. 복잡성은 만약 두 개의 모델이 동일한 결과물을 낸다는 가정 하에 복잡성이 더 큰 모델이 좋지 않음을 의미한다.
- Data : 데이터 개수가 증가함에 따라 결과값의 품질(Quality)가 얼마나 좋은지를 의미한다. Data라는 특성이 클수록 좋은 것이다.
이번에는 모델 선정 시 고려할 또 다른 특성은 Parametric와 Non-parametric 개념이다. 보통 비지도학습 모델들은 Parametric와 Non-parametric으로 구분된다. 각 특성을 살펴보자.
- Parametric : 주어진 데이터가 어떤 분포(ex.포아송분포, 정규분포)로부터 생선된 건지를 가설로 세우고 파라미터(매개변수)를 통해 접근하는 것이다. 파라미터 개수는 변하지 않는다.
- Non-parametric : Feature가 너무 많거나 데이터 분포양상에 대해 가설을 세우지 못할 때 사용한다. 파라미터 개수가 변화하기도 한다. 예시 모델로 KNN, Decision Tree 등이 있다.
또 다른 개념으로 Generative와 Discriminative 가 있다.
- Generative : 연합확률(Joint)을 학습하고 분류 시에 Bayes 정리를 이용해 조건부 확률을 계산한다.
- Discriminative : 조건부 확률을 '직접' 학습한다.
4. Model 평가
모델의 성능을 검증하기 위한 방법으로는 사람이 직접 눈으로 결과를 보고 느끼는 정성평가와 '정답'과 비교하여 성능 수치를 비교하는 정량평가가 있다. 정량평가에 여러가지 개념이 등장하니 하나하나씩 살펴보자.
<Accuracy> = 1- error
Confusion Matrix를 살펴보면서 Accuracy에 대한 정의를 살펴보자. 기본적으로 Accuracy는 모델이 True라고 예측했을 때 실제값인 True인 경우 뿐만 아니라 False라고 예측했을 때 실제값이 False인 경우도 포함이 된다.

따라서 위 그림에 기반해서 Accuracy 공식을 세우면 다음과 같다.

<Precision>
Precision은 '모델의 입장' 에서 모델이 True라고 예측했을 때 실제값이 True인 비율을 뜻한다. Confusion Matrix 표에 의해 식을 만들면 다음과 같다.

<Recall>
Recall은 '실제정답의 입장' 에서 실제값이 True일 때 모델이 True라고 예측한 비율을 뜻한다. Sensitivity 또는 hit rate라고 부르기도하며 공식은 다음과 같다.

참고로 Precision 과 Recall은 서로 상호보완해야 제대로 평가가 가능하다. 두 지표가 모두 높을 수록 좋은 모델이라 할 수 있다.
<F1 Score>
F1 Score은 Precision 과 Recall의 조화평균을 의미한다. F1 Score은 데이터 Label이 불균형 구조일 때 모델 성능을 정확히 평가한다고 알려져 있다. 공식은 다음과 같다.

기하학적으로 표현해보면 다음과 같다.

즉, 단순 평균이라기보다는 작은 길이 쪽으로 치우치게 된, 그러면서 작은 쪽보다도 작은 평균이 도출된다. 이렇게 조화평균을 이용하면 산술평균을 이용하는 것보다, 큰 비중이 끼치는 bias가 줄어든다고 볼 수 있다.
<Fall-out>
Fall-out은 '실제 데이터의 입장' 에서 실제 데이터가 False일 때 모델이 True라고 예측한 비율이다. 공식은 다음과 같다.

<ROC Curve>
여러 임계값들을 기준으로 Recall-Fallout의 변화를 시각화한 것이다. Fall-out은 실제 False인 data 중에서 모델이 True로 분류한, 그리고 Recall은 실제 True인 data 중에서 모델이 True로 분류한 비율을 나타낸 지표로써, 이 두 지표를 각각 x, y의 축으로 놓고 그려지는 그래프를 해석한다. 이에 대한 설명은 필자의 필기 그림으로 살펴보자. 자세한 설명도 써놓았다.
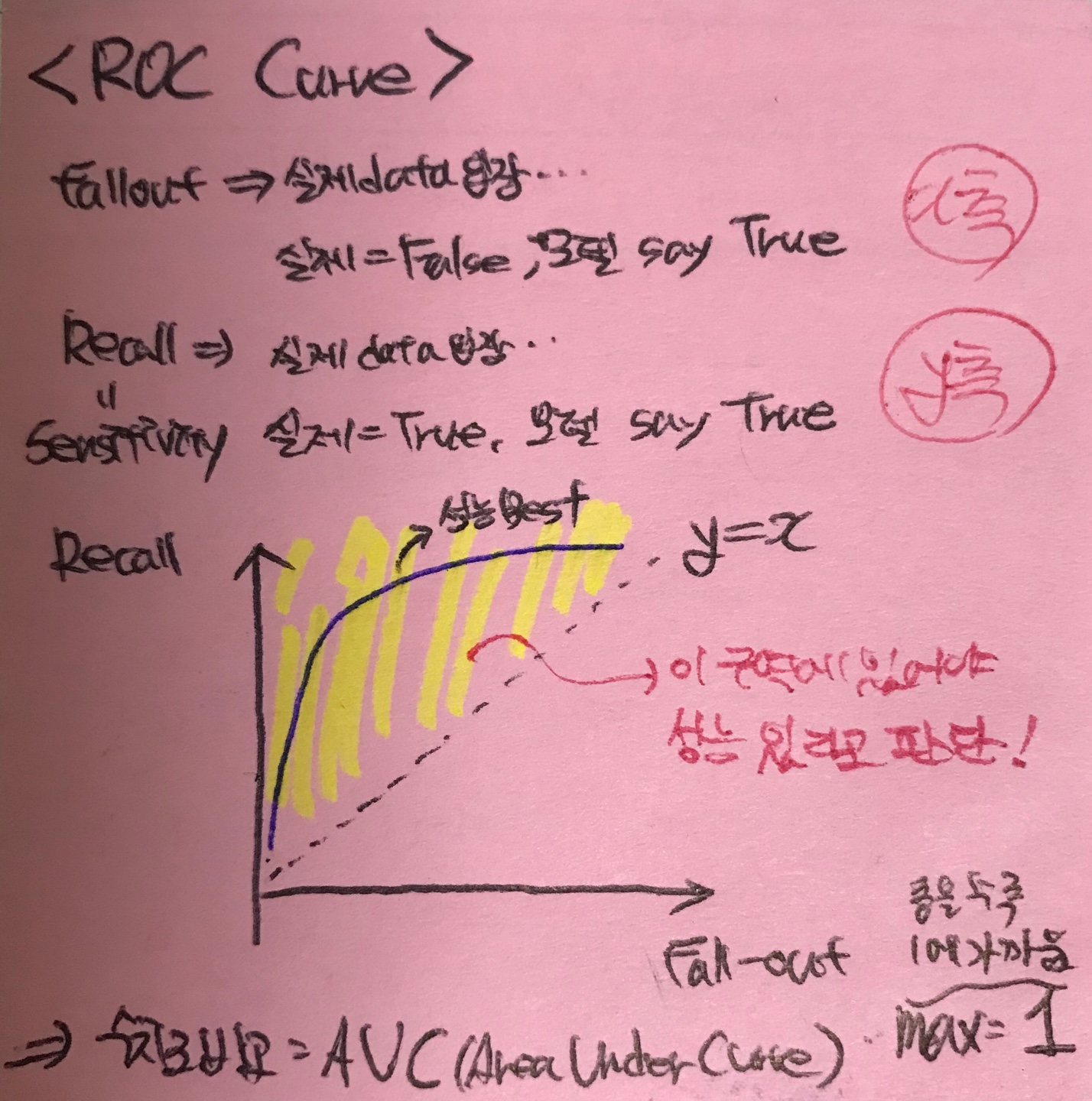
참고로 이러한 ROC Curve를 그래프가 아닌 수치로 비교한 것이 AUC(Area Under Curve)이며 클수록 1에 가까워 진다.
<BLEU Metric(Score)>
BLEU = Bilingual Evaluation Understudy 이며 우리가 흔히 알고 있는 번역 문장에 대한 평가방법으로서 사용된다.
밑의 예시 그림을 살펴보면서 이해해보자.

여기서 gram이라는 개념은 예를들어 1-gram이면 단어, 우리말로 하면 '어절' 단위로 한개씩 끊어서 동일한 단어가 나온것을 평가하는 것이고 2-gram이면 두 개의 단어 단위씩 앞뒤로 번갈아가며 평가하는 것이다.
이렇게 정량평가를 하는 데 있어서 개념과 방법을 살펴보았고 이번엔 평가를 위한 데이터 분배 방법과 모델 평가 기준에 대해서 알아보자.
<평가를 위한 데이터 분배>
- Train / Test 데이터로 구분 : 일반적인 경우일 수 있지만 현대적인 방법은 아니다.
- Train / Validation / Test 로 구분 : 첫번 째 방법과 동일하지만 Validation 데이터가 추가한 것이 포인트이다. Validation 데이터는 모델링 중간중간 Feature를 늘리거나 파라미터를 조정한 후 평가하기 위한 일종의 Test 데이터라고 볼 수 있겠다.
- K-fold Cross Validation : 객관적인 평가가 가능한 방법으로 Test fold를 바꾸어가며 모든 fold가 사용될 때까지 반복을 한다. 보통 K값은 5, 10과 같은 떨어지는 숫자로 지정한다.

<모델 평가 기준>
모델 평가할 때 어떤 기준으로 평가를 해야할까?
- Bias와 Variance를 고려한다. 각 값들이 높을 때 모델의 error가 어떤 그래프로 그려지는지 그림을 통해 살펴보자.

- Generalization : Test 데이터에서도 성능이 좋으면 "Generalization이 좋다" 라고 한다.
- Capacity : 가설 Space의 면적으로 그림 속 해당 부분이다.

- Overfitting : 과적합이라고 하기도 하며 모델의 Complexity가 높아져 Train 데이터는 잘 구분하지만 오히려 Test 데이터는 구분을 하지 못하는 문제를 말한다.
5. Model 학습 알고리즘
모델이 갖고 있는 파라미터를 최적화하는 알고리즘으로 최적화할 대상을 먼저 정의(Objective Function을 선정)하고 최적화할 파라미터값을 찾는 순서로 진행한다. 여기서는 간단하게 용어의 의미만 살펴보고 넘어가자.
- Loss Function : 하나의 데이터가 틀렸을 때 실제값과의 차이를 말한다.
- Cost Function : Loss Function의 일반화 버전으로서 모든 데이터와 실제 값들과의 차이의 종합이며 Loss의 합에 정규화 Term을 포함시키는 것이다.(정규화 Term에 대해서는 추후에 배울 예정이다.)
- Objective Function : 최적화 하려는 모든 종류의 함수를 말한다.
# 여기서 Loss, Cost Function은 값을 최소화하려는 함수에만 국한되지만 Objective Function은 최대화 최소화하는 함수 모두를 포함하는 포괄적인 개념이다.
6. 데이터를 어떻게 Sampling할 것인가?
데이터들은 분포(Bias)가 치우쳐져있으면 안된다. 따라서 다음과 같은 Sampling 방법들을 사용한다.
- Down-Sampling : 비율이 많은 데이터들 중 적게 일부를 선택해 사용
- Up-Sampling : 데이터 수가 적어서 비슷한 데이터들을 임의로 만들어 사용
- Distant-Supervision : 반지도학습 방식으로 어떠한 '가정'을 Label로 취급한다. 예를들어 "머리카락 길이가 30cm이상이다" -> "여자이겠구나!"
- Bagging(Bootstrap aggregating) : 데이터가 충분하지 않을 때 사용한다. 예를들어 총 데이터 갯수가 100개가 있다면 10개가 들어갈 수 있는 여러개의 가방들을 만들고 한 가방에 10개만 넣고 그 가방속의 10개 데이터들로만 모델을 학습시키는 방법
이렇게 머신러닝의 종류와 데이터를 관찰하고 모델링, 그리고 평가하는 전체적인 프로세스에 걸치면서 여러가지 개념을 알아보았다.
다음 포스팅에서는 본격적으로 머신러닝 모델의 종류에 대해서 공부해 볼 예정이다. 그 첫 번째는 Decision Tree일 것이다.
'Data Science > Machine Learning' 카테고리의 다른 글
| [ML] Bayesian Networks(베이즈 네트워크) (2) | 2020.04.13 |
|---|---|
| [ML] Decision Tree(의사결정나무) (0) | 2020.04.10 |
| [딥러닝] NN(Neural Network)의 등장과 개념 (0) | 2020.03.14 |
| [ML] 머신러닝 모델링 시 필요한 데이터 종류 그리고 Epoch란? (0) | 2020.03.12 |
| [ML] Softmax Regression(다중분류모델) (0) | 2020.03.11 |



