이번 포스팅에서는 간단한 개념정의를 하려고 한다. 그동안 배웠던 머신러닝 모델링에 관한 내용은 아니니 쉽게 접근하면 되겠다. 소개할 주제는 다음과 같다.
1. 머신러닝 모델시 Train / Test / Validation 데이터들의 각각의 개념
2. Online Learning이란?
3. Epoch와 Batch의 개념
<1. Train / Test / Validation 용 데이터들>

머신러닝을 모델링 하고 성능을 검증할 때 위 그림과 같이 Raw Data에서 2가지 또는 3가지로 나누어 준다. 학습률(Learning rate)과 Regularization Strength 상수값을 튜닝하기 위해서는 가장 밑의 3가지(훈련/검증/테스팅) 종류로 나눈 방법을 사용한다.
이렇게 3가지 종류로 나누어서 검증하는 이유는 쉽게 예를들면 이렇다. 중,고등학교 시절 우리는 중간고사를 볼 때면 중간고사 당일 몇 일전에 선생님께서 중간고사 대비 시험지를 나눠주시고 풀어보라고 하신다. 여기서 우리는 머신러닝을 그대로 대입해볼 수 있다.
즉, 중간고사 당일 시험(머신러닝 성능평가)을 대비해서 평소에 교과서(Train데이터)로 훈련을하고 중간 중간 자신의 실력을 검증하기 위해서 문제집(Validation)을 풀어본다. 그리고 중간고사 직전에 선생님께서 나눠 주신 모의고사 시험지(Test 데이터)를 통해서 실전 시험에 대비를 한다.
이 정도의 비유면 이해가 갔을.. 거라고 믿는다! 다시 머신러닝 이야기로 돌아와서, "그렇다면 Validation(검증)과 Testing 데이터의 차이는 뭔가요? " 라고 질문을 던질 수도 있을 것 같다. 차이점은 다음과 같다.
머신러닝을 모델링할 때 학습률이나 Regularization strength와 같은 사용자가 임의로 정의해야(튜닝해야) 하는 숫자들이 있다. 이러한 숫자들은 보통 한 번에 최적의 값을 찾기 어렵기 때문에 반복적인 시도를 통해서 결정해야 한다. 그렇다면 이 '시도'를 하기 위해서는 훈련 데이터와 동일하지 않은 특정한 몇 개의 낯선 데이터를 입력시켜야 하는데 이 때 사용하는 것이 Validation(검증) 데이터이다.
<2. Online Learning>
이 세상에 존재하는 모든 문제를 해결하기 위해 머신러닝을 모델링 하다 보면 데이터의 갯수가 엄청 많을 때가 있다. 이 때 1000만, 1억개의 데이터를 한번에 모델링하게 되면 모델에 과부하가 걸리기도 하며 별개로 1억개의 데이터를 학습시킨 후 추가로 10만개의 데이터를 추가로 훈련시켜야 할 때면 이전에 훈련시켰던 수 많은 데이터를 다시 입력시켜야 하는 거대한 번거로움이 발생한다.
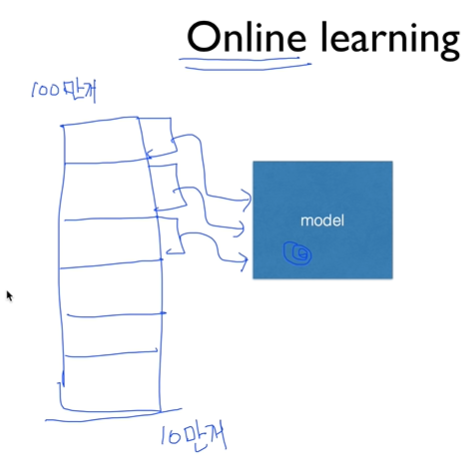
따라서 이러한 문제점들을 해결하기 위해서 Online Learning을 사용하게 되는데 개념은 다음과 같다. 예를 들어 그림과 같이 100만개의 데이터가 존재한다고 했을 때 100만개를 한 번에 다 훈련시키는 것이 아닌 10만개씩 나누어서 10번을 입력시키는 것이다. 그렇다면 모델이 한 번에 입력받는 과부하가 걸리지 않을 뿐더러 추가적으로 10만개의 데이터가 입력되야 한다면 이전에 훈련시켰던 데이터들을 다시 입력하는 번거로움을 맞닥뜨리지도 않을 것이다.
<3. Epoch 와 Batch>
이것에 대한 개념은 간단하게 소개하겠다. 예시를 가정하면, 전체 데이터의 갯수가 10000개라고 했을 때,
- Epoch : 전체 데이터 갯수 10000개를 모두 훈련시켰으면 Epoch = 1이 된다.
- Batch_size : 전체 데이터 10000개를 한 번에 훈련시키기에는 과부하가 걸릴 것을 감안해서 100개씩 끊어서 데이터를 입력시킨다고 가정하면 그 때 Batch size 값이 100이 된다.

'Data Science > Machine Learning' 카테고리의 다른 글
| [ML] 머신러닝의 종류와 용어개념 (0) | 2020.04.05 |
|---|---|
| [딥러닝] NN(Neural Network)의 등장과 개념 (0) | 2020.03.14 |
| [ML] Softmax Regression(다중분류모델) (0) | 2020.03.11 |
| [ML] Logistic Regression for Classification (0) | 2020.03.11 |
| [ML] Linear Regression(선형회귀분석) (0) | 2020.02.24 |



