🔊 해당 포스팅은 밑바닥부터 시작하는 딥러닝 2권의 교재 내용의 마지막 챕터인 Transformer에 대해 간단히 소개하는 개념과 더불어 Transformer 논문인 "Attention Is All You Need"를 읽고 개인적으로 요약 및 정리한 글임을 알립니다.

본격 내용에 들어가기에 앞서 앞으로 Transformer(트랜스포머)에 대한 내용을 2개의 포스팅으로 나누어 게시하려고 한다. 첫 번째인 이번 포스팅에서는 트랜스포머 모델 논문에 기반하여 트랜스포머 모델이 나오게 된 이유를 알아보고 개괄적인 모델 구조를 그림으로 살펴보면서 어떤 기법이 들어가있는지에 대해 집중적으로 다룬다. 그리고 다음 포스팅에서는 트랜스포머 모델의 '진짜' 구조를 그야말로 밑바닥부터 파헤쳐보도록 하자.
1. 거추장스러운 RNN을 치워버리자!
그동안 여러 포스팅에 걸쳐서 다양하게 응용한, 그 중에서도 어텐션 기법까지 적용한 seq2seq 모델에 대해서도 알아보았다. 그런데 지금껏 소개한 seq2seq 모델들의 공통점이 있었는데, 그것은 바로 seq2seq 모델을 구성하는 Encoder, Decoder에는 모두 RNN 계열의 모델이 들어갔다는 것이다. 특히, RNN 계열 모델 중에서 LSTM, GRU와 같은 모델을 사용하면서 장기기억을 유지하고 모델의 높은 성능도 달성할 수 있었다. 그런데 이러한 RNN 계열 모델(논문에서는 RNN과 함께 Convolution을 사용하는 모델 계열도 언급한다)은 치명적인 단점이 있는데, 바로 병렬 처리 연산이 불가능하다는 점이다.
왜 RNN 계열 모델이 병렬 처리 연산이 불가능할까? RNN은 이전 시각에 계산한 결과를 이용하여 다음 시각의 인풋으로 사용하기 때문이다. 즉, RNN의 재귀적인 특성 때문이다. 다시 RNN을 그림을 보면 느낌이 올 것이다.

위와 같은 구조적인 특성 때문에 RNN 계열 모델을 활용한 seq2seq 모델에서는 병렬 처리 연산을 할 수가 없다. 그리고 또 한가지 문제점이 존재하는데, 입력과 출력 간의 대응되는 단어들 사이의 물리적인 거리가 멀수록 대응관계를 잘 학습하지 못하게 된다. 저번 포스팅에서 배운 어텐션을 적용한 seq2seq 모델에서는 입력(출발어) 시퀀스 내의 단어와 출력(도착어) 시퀀스 내의 단어 간의 대응관계를 학습한다고 했다.
그런데 여기서 입력 시퀀스 내의 A라는 단어와 출력 시퀀스 내의 B라는 단어가 대응관계가 있다고 해보자. 만약 이 A, B 단어 간의 물리적 거리가 멀다고 한다면 아무리 어텐션을 적용한다고 한다해도 대응 관계를 충분히 잘 학습하지 못할 수가 있다. 이는 예전 포스팅에서 알아본 seq2seq 모델을 개선하는 기법 중 하나로 입력 시퀀스를 뒤집어 넣는 이유와 연관이 되는 듯 하다.(그 때 당시 해당 기법을 소개하면서 입력 시퀀스를 뒤집음으로써 입력, 출력 간의 특정 단어 간의 거리는 가까워질 수 있지만 입력, 출력 간의 대응되는 단어들 전체 평균 거리는 변하지 않는다고 했었다)
그래서 이번에 소개하는 트랜스포머 모델은 Encoder, Decoder에서 RNN 계열 모델을 사용하지 않고 대신 어텐션 계층을 더 전적(?)으로 활용한다. 이렇게 어텐션 계층만을 온전히 사용함으로써 트랜스포머 모델은 결과적으로 병렬 연산 처리가 가능하게 되어 모델 학습 시간을 대폭으로 줄일 수 있었고 대응관계가 있는 입력, 출력 단어 간에 거리가 멀어도 대응 관계를 잘 학습(논문에서는 이를 Global Dependency 라고 함)하게 된다. 그러면 이제 트랜스포머 모델이 어떻게 어텐션 계층을 온전히 사용한 것인지에 대해 알아보자.
2. 그냥 어텐션이 아닌 Self-Attention!
트랜스포머 모델은 일반 어텐션이 아닌 셀프-어텐션(Self-Attention) 기법을 사용한다. 셀프-어텐션이란 무엇일까? 우선 아래 그림부터 살펴보자. 아래 그림은 기존 seq2seq 모델에서의 어텐션 기법과 트랜스포머의 셀프-어텐션 기법의 차이를 간략화하여 비교한 그림이다.

그림을 보고 알 수 있는 큰 차이점은 어텐션 기법이 입력-출력 간의 대응 관계를 확인하느냐 또는 입력 내에서 또는 출력 내에서 대응 관계를 확인하느냐이다. 기존 어텐션 기법은 입력-출력 간에 대응되는 단어 관계를 파악하는 게 핵심이었다. 하지만 셀프-어텐션 기법은 입력-출력 간이 아닌 입력, 출력 각 시퀀스 내부의 단어들 간의 대응 관계를 파악하는 것이다. 아래 그림처럼 말이다.
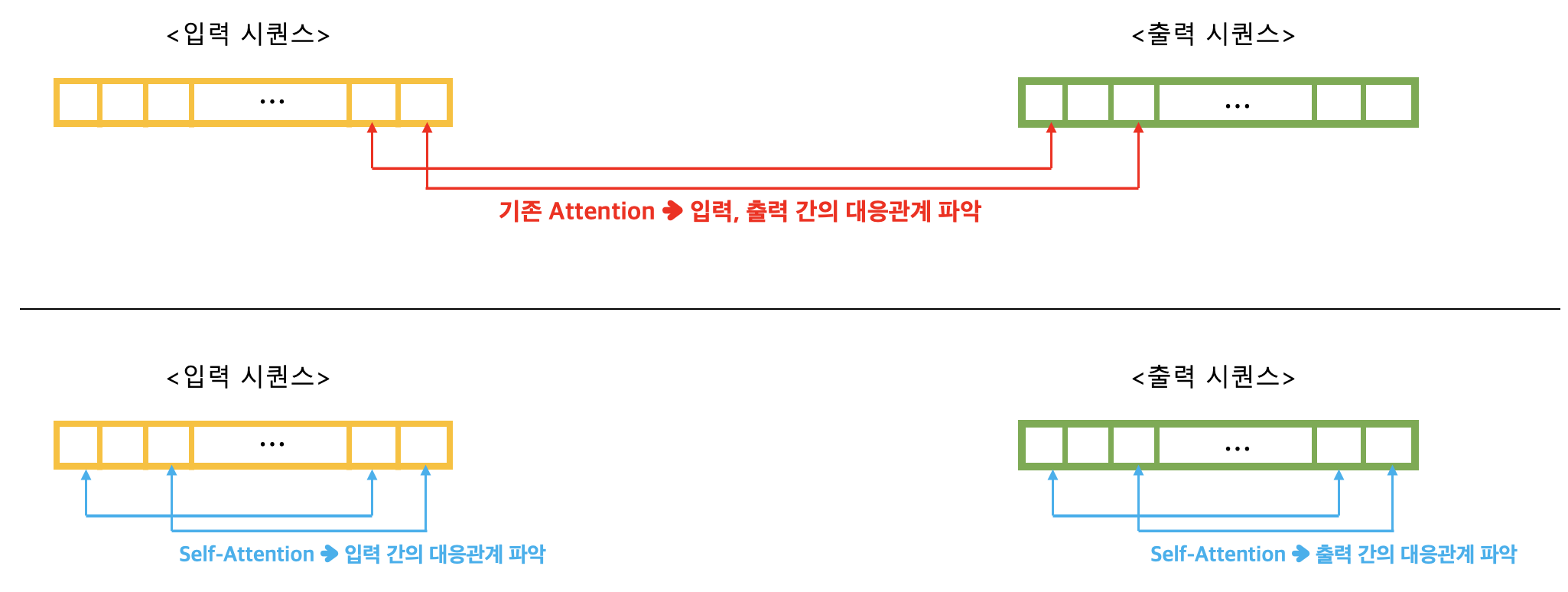
결국, 셀프-어텐션 기법은 입력 시퀀스 내에서의 대응관계를 학습하고 동시에 출력 시퀀스 내에서의 대응관계도 학습하는 방법이다. 그리고 이러한 셀프-어텐션 기법을 사용해 만든 계층을 재귀적으로 쌓아서 기존 seq2seq 모델의 RNN이 하던 (과거의 기억을 유지하는)메모리 네트워크 역할을 대체하기도 한다.
3. Transformer 구조 Overview
트랜스포머가 자주 사용하는 셀프-어텐션 기법도 알아보았다. 그러면 이를 기반으로 해서 만드는 트랜스포머 모델의 개략적인 구조를 살펴보기로 하자. 트랜스포머 모델에는 셀프-어텐션, Point-wise Feed-Forward Network(논문 상에서 FFN이라고 함) 이 2개의 큰 구성요소로 구성되어 있고 부가적으로 Positional Encoding, Skip Connection 기법들도 추가되었다는 점을 머리에 두고 아래 그림을 살펴보자.
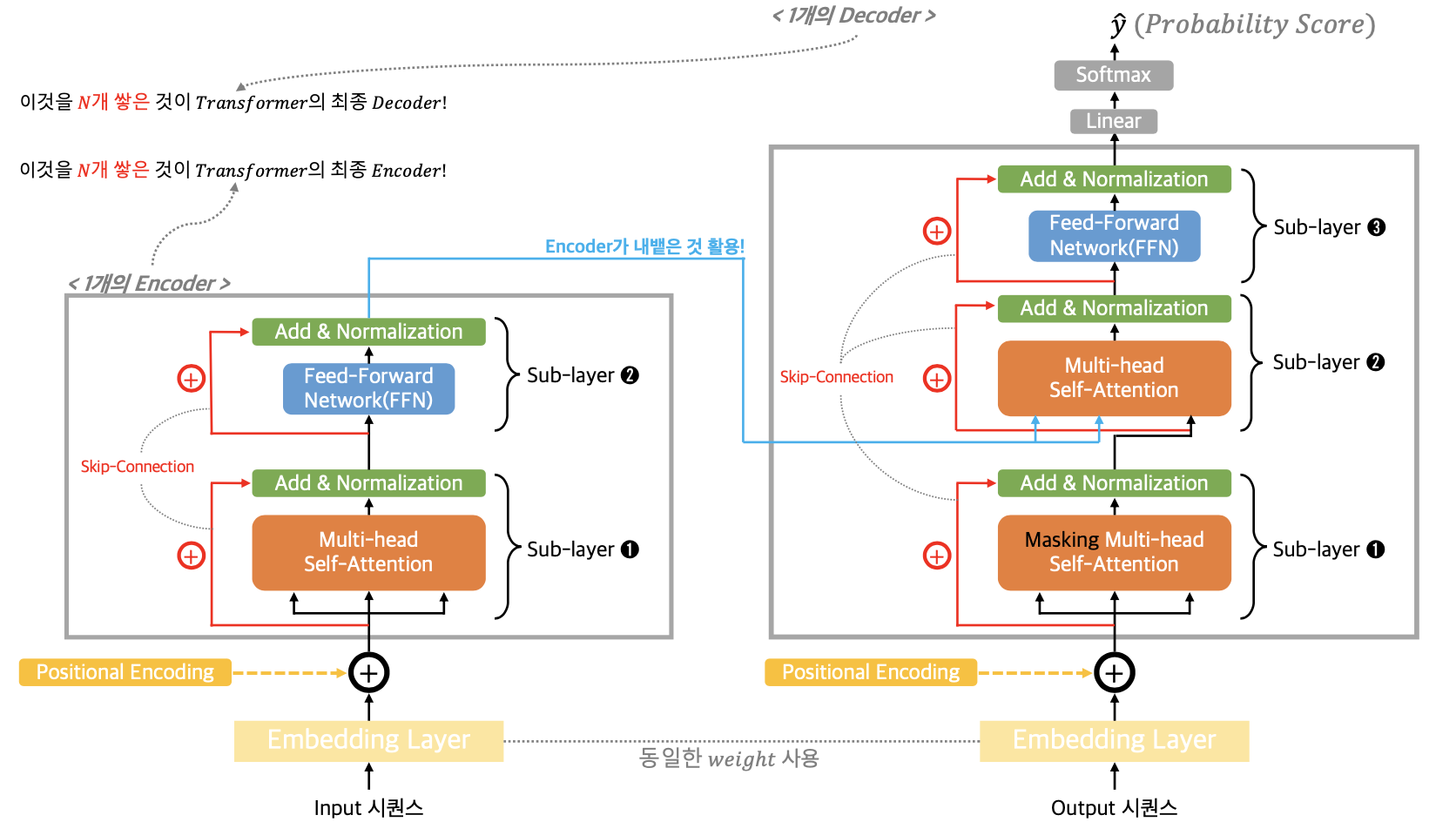
3-1. Multi-Head Self-Attention 계층 뜯어보기
위 그림을 기반으로 트랜스포머 모델의 구조를 하나씩 살펴보자. 가장 먼저 살펴볼 것은 트랜스포머에서 사용하는 Multi-head Self-Attention(멀티-헤드 셀프-어텐션) 계층 내부가 어떻게 동작하는지를 살펴보아야 한다. 멀티-헤드 어텐션 계층의 구조는 아래 논문의 그림을 차용해 살펴보도록 하자.
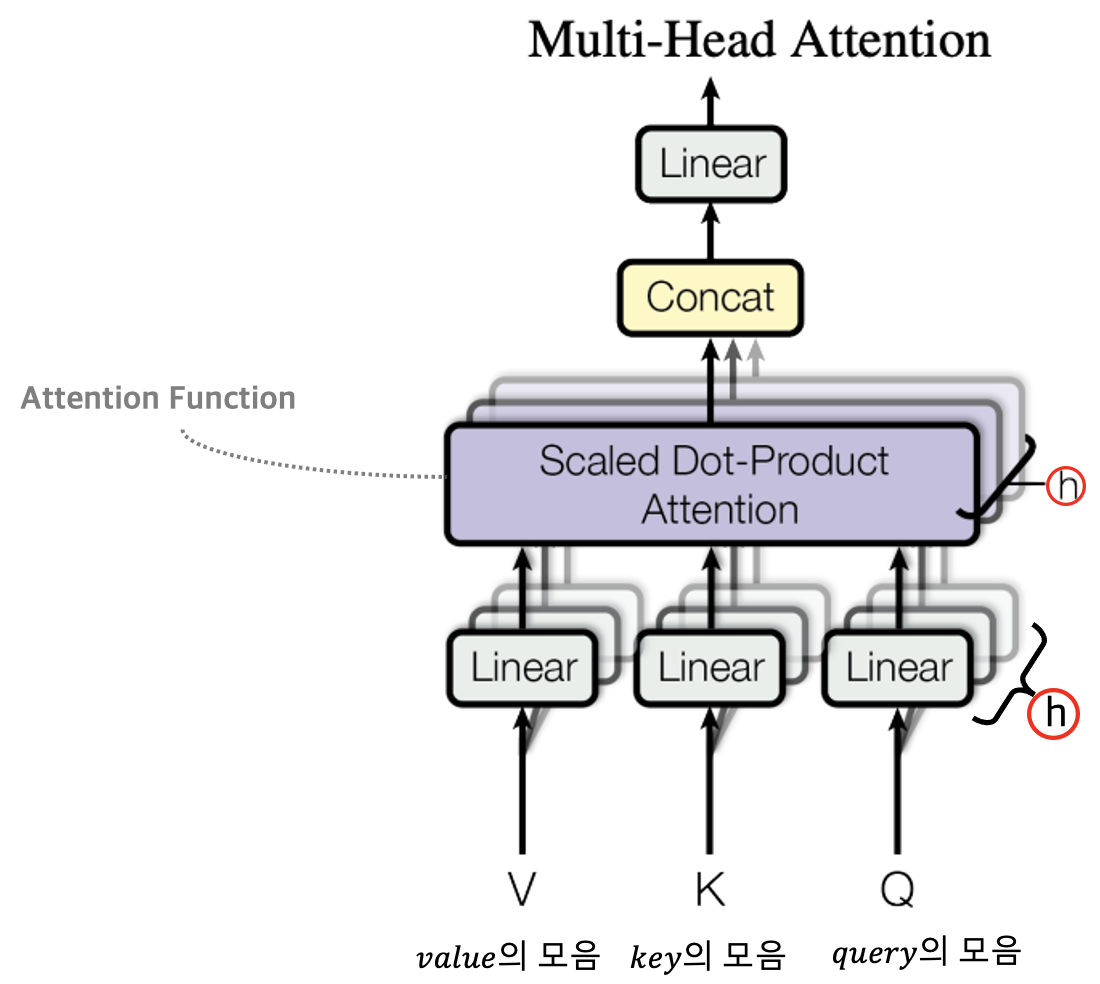
위 그림을 보면 멀티-헤드 어텐션 구조는 Scaled Dot-Product Attention 계층이 여러개로 구성되어 있는 것을 볼 수 있다. 즉, 'Scaled Dot-Product Attention' 이라는 어텐션 계층이 '여러개'로 구성되어 있다고 하여 '멀티-헤드'라는 용어를 사용한 것이다. 그리고 그 '여러개'는 하이퍼파라미터로서 사용자가 임의대로 설정할 수 있는 $h$ 값이다. 논문에서는 이를 8로 설정해 8개의 Scaled Dot-Product Attention으로 구성했다. 참고로 Scaled Dot-Product Attention은 논문 상에서 Attention Function이라고도 부른다.
3-1-1. 가중치를 계산하자, Scaled Dot-Product Attention!
Scaled Dot-Product Attention은 $V, K, Q$라는 것을 입력으로 받는다. 이 때, $V, K, Q$가 각각 $value, key, query$의 모음(집합)인데, 이는 입력 시퀀스 또는 출력 시퀀스 내의 토큰 개수 만큼의 $value, key, query$를 모아서 한번에 처리하기 때문이다. 이에 대해서는 아직 이해가 잘 안될 것이다. $V, K, Q$가 무엇을 의미하는지는 아마 다음 포스팅에서 자세히 알아볼 예정이니 여기에서는 단순히 '입력 또는 출력 시퀀스 내의 토큰들(자연어로 치자면 문장을 구성하는 단어 토큰들)' 이라고 생각하고 넘어가자.
그러면 이제 멀티-헤드 셀프-어텐션 구조를 구성하는 Scaled Dot-Product Attention 구조 내부를 살펴볼 필요가 있다. 그래야 멀티-헤드 셀프-어텐션 구조도 이해할 테니 말이다.
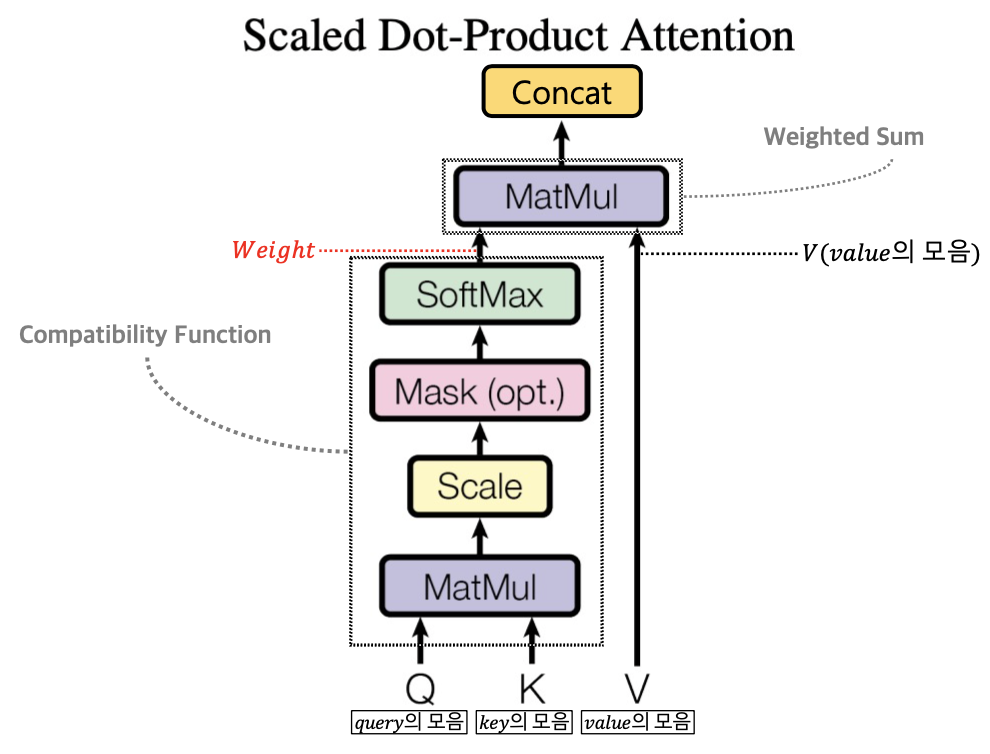
Scaled Dot-Product Attention 구조는 크게 2가지 단계로 진행된다. 첫 번째는 Compatibility Function이라는 부분과 Weighted Sum 이라는 부분이다. 하나씩 살펴보자.
Compatibility Function은 $value$의 모음을 의미하는 $V$에 부여할 가중치(Weight)를 계산하는 부분이다. 가중치를 계산하는 아이디어는 예전 포스팅에서 어텐션 기법을 적용한 seq2seq 모델을 처음 배울 때 알아본 '가중치 계산 계층'과 유사하다고 볼 수 있다. 어쨌거나 가중치를 계산하는 Compatibility Function은 $query$의 모음인 $Q$와 $key$의 모음인 $K$를 입력으로 받아서 위 그림과 같이 [Matmul ➜ Scale ➜ Mask(Optional) ➜ Softmax] 연산과정을 거친다. 참고로 옵셔널(선택 가능)한 Mask는 추후에 Decoder 부분에서 배울 Masking Multi-Head Self-Attention 계층에서 사용하는 방식이다. Encoder 부분에서는 Mask를 적용하지 않는다. Mask를 왜 하는지에 대해서는 밑에서 배우도록 하자.
따라서 Compatibiliy Function 연산과정을 수식으로 나타내면 아래와 같다. 아래의 수식은 논문에서 직접 등장한 것은 아니지만 필자가 약간 커스터마이징했다.
$${f_{compatibility}(Q, K)} = softmax({\frac{QK^T}{\sqrt{d_{k}}}})$$
수식을 하나씩 살펴보자. Matmul 하는 단계는 $Q$와 $K$ 간의 내적을 통해서 $Q$ 와 $K$라는 벡터 간의 유사도를 계산하는 셈이다.(내적을 하는 의미도 예전 포스팅의 [1-4]목차를 참고하면 좋다!)
그리고 Scale 단계에서의 $d_k$는 $Q$와, $K$를 만들어낸 (입력 또는 출력의) Embedding Layer 이후에 하나의 Layer를 거치고 난 후의 차원 수 의미한다. 논문에서는 그 차원 수를 64로 설정했다.(이 '하나의 Layer'이 무엇인지는 다음 포스팅에서 자세히 알게 된다)
마지막으로는 가중치를 의미하는 0과 1사이의 값으로 변환하기 위해 Softmax 함수를 씌워준다.
그런데 필자는 여기서 왜 Softmax 함수의 입력으로 들어가는 $QK^T$ 를 $\sqrt{d_{k}}$로 스케일링하는지 의문이 들었다. 한참 구글링을 하다가 여기에서 명쾌한 답변을 얻을 수 있었다. 답변 원본 링크를 들어가서 보면 알겠지만 Softmax 함수는 입력으로 들어가는 원본 인풋 값들에 1.0 보다 큰 값을 곱해준 후(1.0 보다 큰 값을 곱해준다는 것은 인풋 값을 키우는 셈) Softmax 함수를 적용하면 원본 인풋 값들을 Softmax 함수에 넣었을 때의 출력값 보다 0과 1에 각각 더 가까워지는 것을 볼 수 있다. 즉, 출력값들이 이전보다 0과 1에 더 수렴하는 결과가 나오게 된다. 그런데 제대로 학습이 되지 않은 상황에서 출력값이 대부분 0과 1에 수렴하게 되면 역전파를 수행할 때 기울기 소실 문제를 유발하게 된다.(물론 나중에 최종적으로 제대로 학습이 되게 되면 Softmax 출력값이 0과 1에 각각 수렴해야 하지만 여기서는 학습이 제대로 되지 않는 상황일 때 발생하는 문제를 가정한 것)
이와 관련해서 예전 포스팅에서 신경망 가중치를 초기화하는 적절한 방법을 찾기 위한 방법으로 은닉층 출력값들의 분포를 살펴보았었던 적이 있다. 출력값이 왜 극단의 값으로 수렴하게 되면 문제가 발생하는지 궁금하다면 예전 포스팅을 참조해보자. 간단히 말해서 출력값($y$)들의 분포가 0 또는 1로 치우칠 때 Softmax 그래프의 기울기 그림을 보면 0이 되고 이는 곧 기울기 소실을 의미한다.
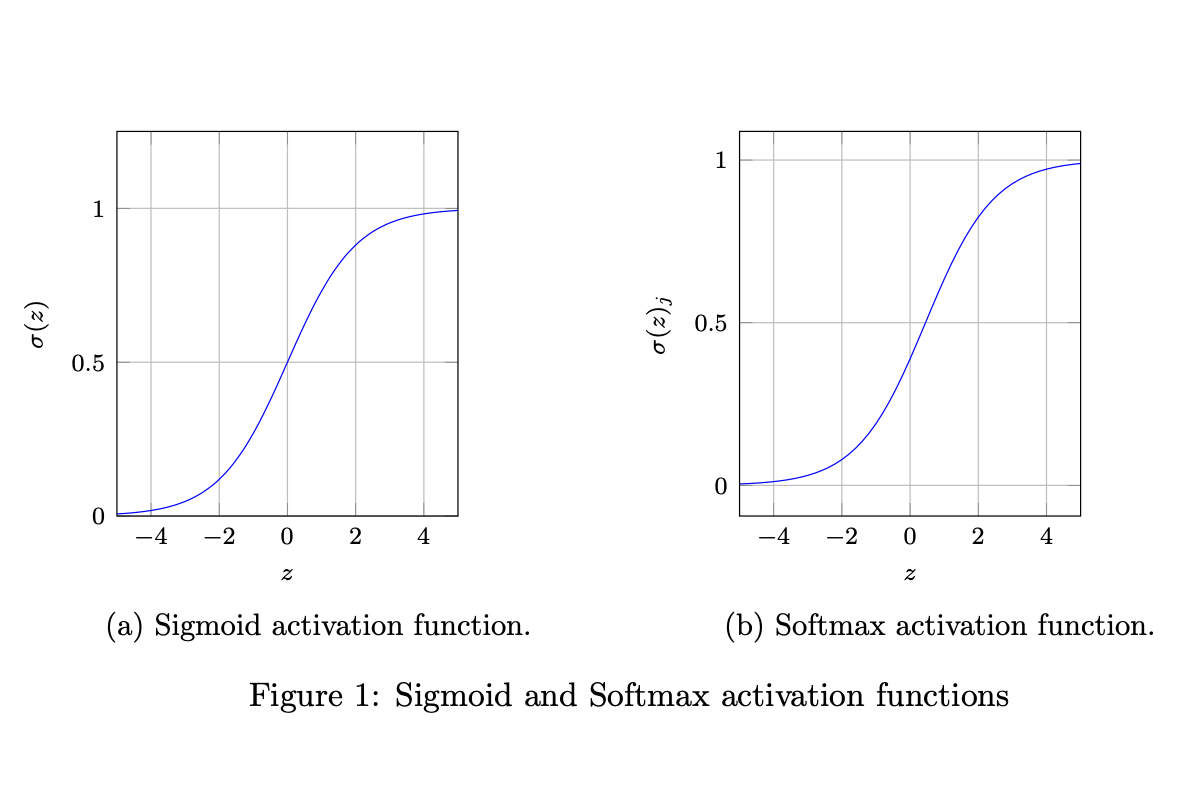
반면에, 원본 인풋 값들에 1.0 보다 작은 값을 곱해준 후(1.0 보다 작은 값을 곱해준다는 것은 인풋 값을 축소하는 셈) Softmax 함수를 적용하면 원본 인풋 값들을 Softmax 함수에 넣었을 때의 출력값보다 0과 1로 부터 멀어지는 것을 볼 수 있다. 이렇게 되면 역전파 시 상대적으로 기울기 소실 문제를 유발하지 않게 된다. 그래서 Compatibility Function 내에서 원본 인풋($QK^T$)에 1.0보다 작은 값을 곱해주는 Scale 항(여기서는 ${\frac{1}{\sqrt{d_{k}}}}$을 곱해줌)을 적용하는 것이다!
어쨌거나 Compatibility Function의 결과값은 결국 $V$에 부여해줄 가중치인 $Weight$를 의미한다. 따라서 가중치를 $V$와 Weighted Sum 하는 수식까지 포함해 Scaled Dot-Product Attention의 최종 수식은 아래와 같다.
$$Attention(Q, K, V) = softmax({\frac{QK^T}{\sqrt{d_{k}}}})V$$
지금까지 알아본 Scaled Dot-Product Attention을 $h$개 만큼 반복 수행해준 후 나온 결과값들을 모두 연결(Concatenate)한 후 다시 한 번 Linear 연산을 취하게 되면 최종적으로 한 개의 Multi-Head Self-Attention 계층 연산이 끝나게 된다.
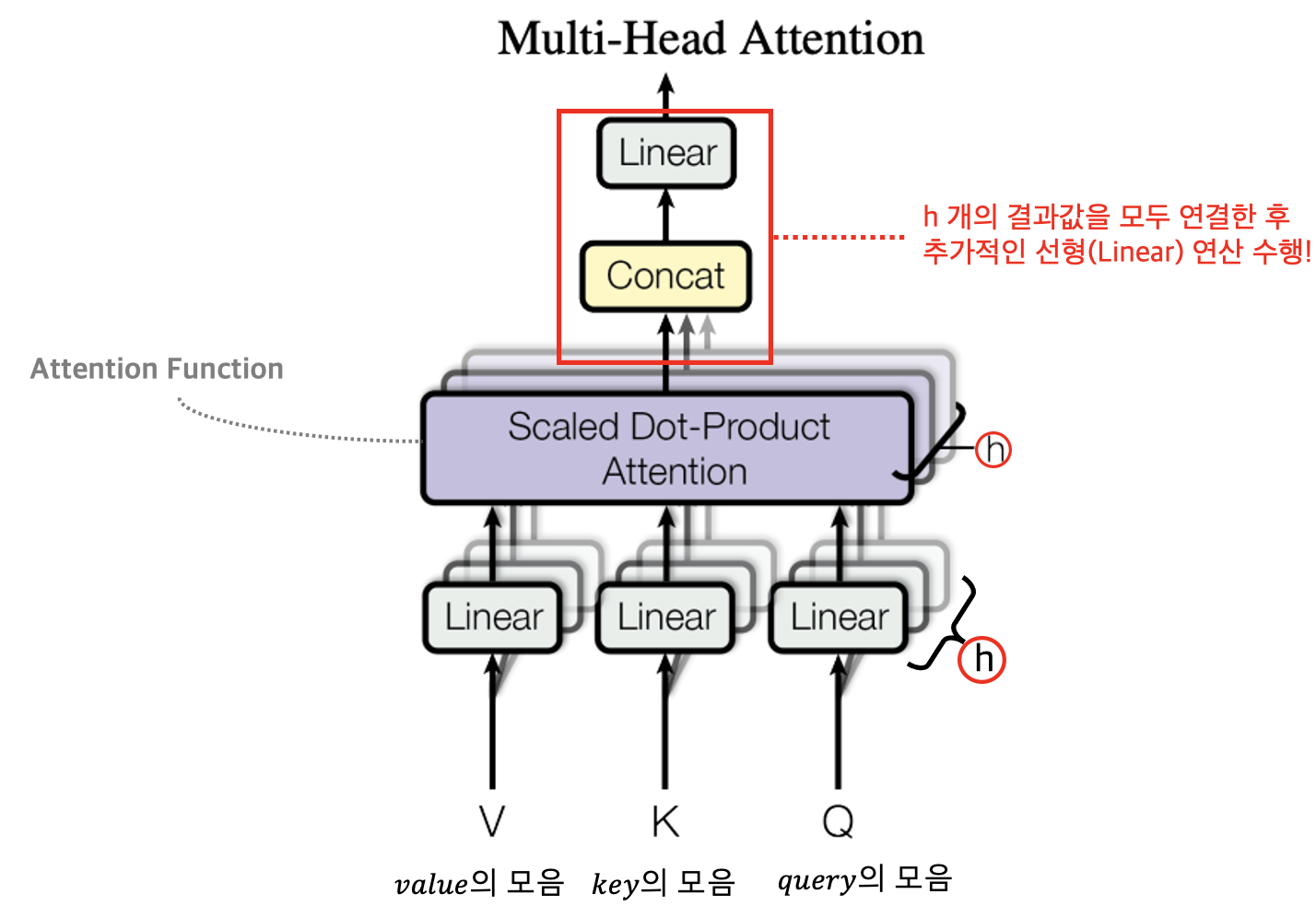
그리고 논문에서는 Compatibility Function을 만드는 데, 크게 2가지 기법이 존재한다고 언급한다. 첫 번째는 Multiplicative(Dot-Product) 기법, 두 번째는 Additive 기법이다. 첫 번째는 우리가 위에서 알아본 것과 동일하다.(엄밀히 말하면 Scale항을 제외한 것이 Multiplicative 기법임) Additive 기법은 Dot-Product를 사용하지 않고 하나의 은닉층을 갖고 있는 FC Layer를 활용하여 계산하는 기법이다. 트랜스포머 모델이 둘 중 Multiplicative 기법을 선택한 이유는 큰 행렬 연산을 하는 데 최적화된 기술(Numpy와 같은 라이브러리) 때문이다. Dot-Product는 행렬 내적을 모든 원소별로 수행해주어야 하는데, 이렇게 큰 행렬의 연산에는 Numpy, Tensor와 같은 라이브러리가 매우 빠르게 해준다.
3-1-2. 미래의 데이터는 보지말고 예측하자, Masking Self-Attention!
다음은 Masking Multi-Head Self-Attention 계층의 Masking에 대한 내용이다. 이 특별한 셀프-어텐션 계층은 아래 그림처럼 Decoder 부분에만 들어가 있는 것을 볼 수 있다. 왜그럴까?
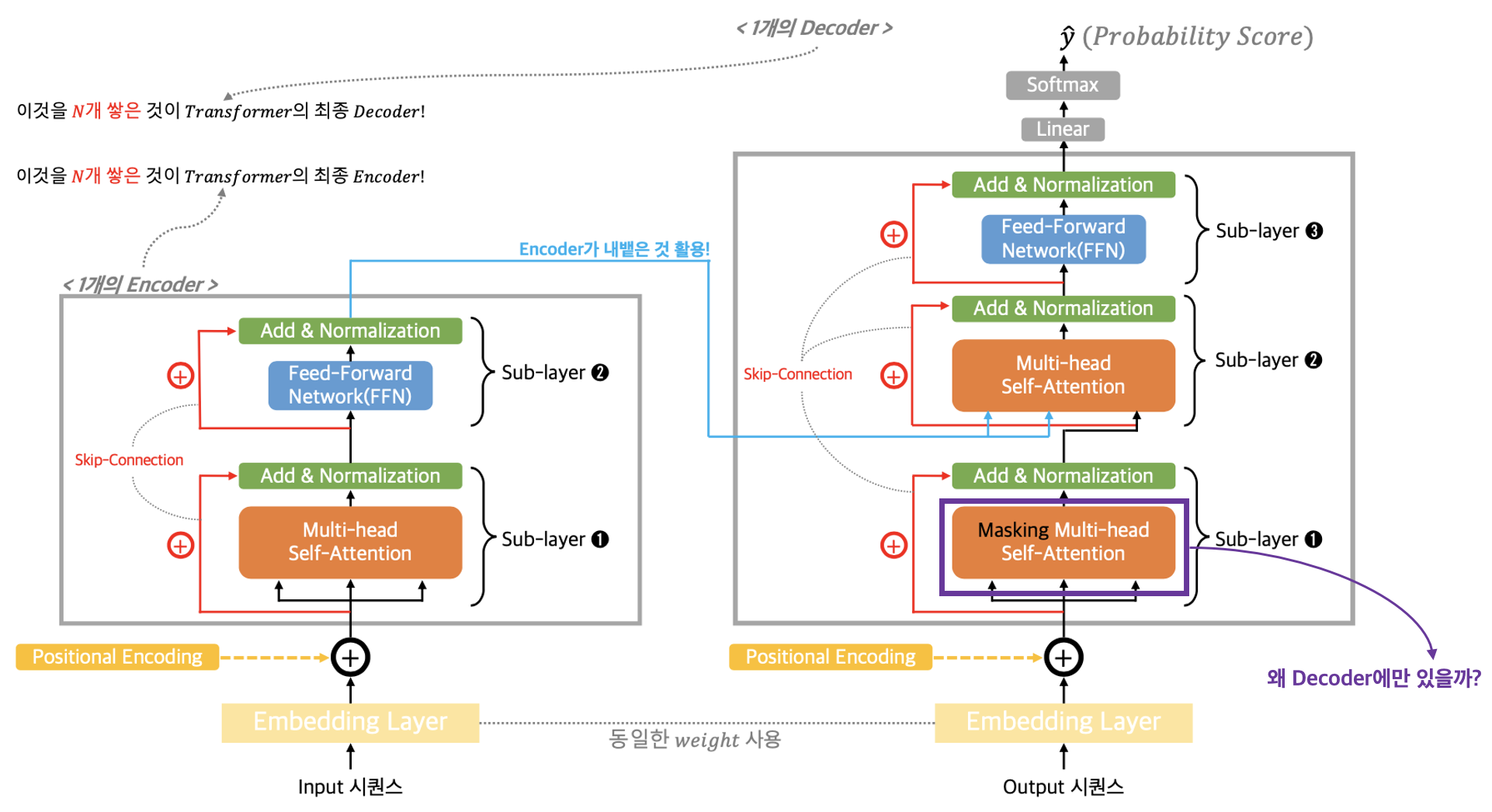
Masking이 필요한 이유를 이해하기 위해서 위에서 배웠던 셀프-어텐션의 개념을 다시 상기시켜보자. 셀프-어텐션은 입력 시퀀스, 출력 시퀀스 각각 내부의 토큰들 간의 관계를 파악하는 것이라고 했다.

우선 Encoder에 들어가는 입력 시퀀스는 우리가 모델을 학습시킬 때나 테스트시킬 때나 항상 알 수 있는 데이터이다. 그러므로 입력 시퀀스 내부의 토큰들 간의 대응관계를 무조건 파악하는 것이 좋다. 반면에 Decoder에 들어가는 출력 시퀀스는 모델을 학습시킬 때는 '정답'으로서 우리가 알 수 있는 데이터지만 테스트시킬 때는 우리가 알 수 없는 값이다. 흔히 우리가 머신러닝 모델을 만들 때, 학습 데이터에는 레이블(정답)이 있지만 테스트 데이터에는 레이블이 없는 것처럼 말이다!
따라서, 테스트일 때를 대비해서 학습 시에도 출력 시퀀스 내부에서 일종의 '미래' 데이터를 보고 예측해서는 안되게 만들어야 한다. 이게 무슨 말이냐면 출력 시퀀스도 시간 순서상 즉, [왼쪽 ➜ 오른쪽] 갈수록 미래 데이터를 의미한다. 그런데 만약 학습 시에 출력 시퀀스 내의 모든 토큰들 간의 대응관계를 파악해버리면(즉, Encoder의 셀프-어텐션과 똑같이 동작한다면) 정답 데이터를 미리 보고 대응관계를 파악한 후 예측하는 것이나 마찬가지다. 만약 이해가 안된다면 아래 예시를 통해 이해해보자.
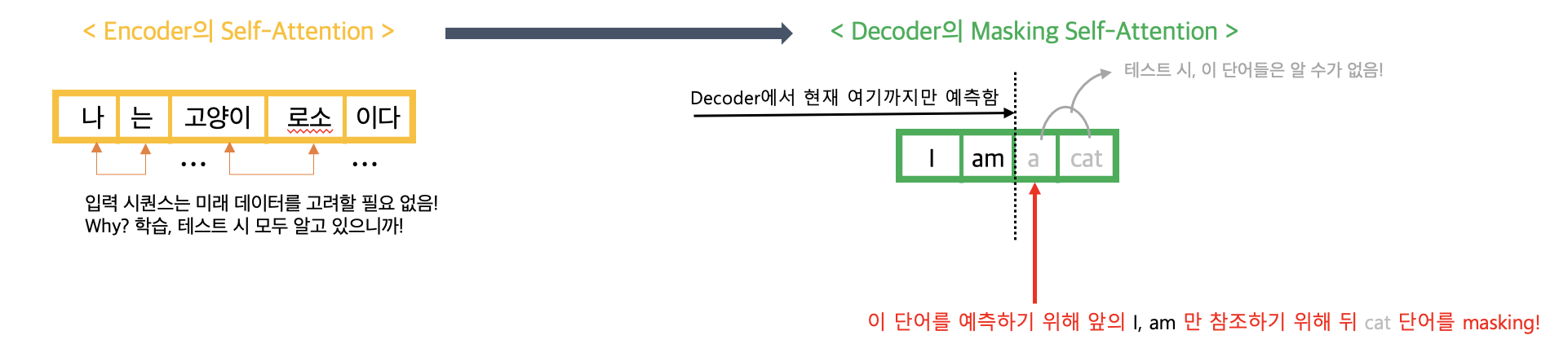
3-2. Point-wise Feed-Forward Network(FFN) 뜯어보기
다음은 트랜스포머 모델의 두 번째 구성요소인 FFN에 대해 알아보자. 앞에 Point-wise라는 용어가 붙긴 하지만 우리가 흔히 알고 있는 Feed-Forward Network와 동일하다. 트랜스포머 모델 구조를 다시 살펴보면서 FFN 구조가 어디있었는지 다시 한 번 살펴보자.
Encoder, Decoder 각각 하나씩 존재하며, 모두 Multi-Head Self-Attention 계층에서 흘러나온 값을 입력으로 받는 것을 볼 수 있다. 여기서의 FFN은 Relu 활성함수를 활용한 선형회귀식을 활용한다. 수식부터 살펴보자.
$$FFN(x) = max(0, xW_1 + b_1)W_2 + b_2$$
수식을 보면 특이한 점이 있다. 바로 선형 회귀식을 두 번 이용한다는 점이다. 첫 번째는 마치 Relu 활성함수를 활용한 듯한 $max(0, xW_1 + b_1)$ 에서 $xW_1 + b_1$ 선형 회귀식이다. 그리고 난 후 $W_2$ 를 곱하고 $b_2$를 더하며 두 번째 선형 회귀식을 사용한다.
이러한 FFN을 입력 또는 출력 시퀀스 내의 모든 포지션의 토큰들에 대해 적용해준다. 이 때, FFN 이라는 네트워크 구조는 동일하게 적용하지만 매번 적용하는 FFN은 서로 다른 파라미터를 사용한다는 것도 잊지말자.
3-3. Add & Normalization 계층
이번 목차는 우리가 그동안 배웠던 개념을 적용하면 된다. 여기서 Add는 Skip(Residual) Connection을 의미한다. Skip Connection은 여러번 설명했기 때문에 따로 설명하지 않겠다. Skip Connection을 사용하는 이유는 '덧셈' 연산의 역전파 시 기울기를 건드리지 않고 그대로 흘려보내는 특성 때문에 기울기 소실, 폭발 문제를 막을 수 있기 때문이다.
Normalization 계층은 출력값들의 분포를 인위적으로 표준정규분포 형태로 만들어 주는 것이다. 이전에 배웠던 Batch Normalization 개념과 동일하다고 보면 되겠다.
3-4. Positional Encoding
다음은 [입력 또는 출력 시퀀스 ➜ Embedding Layer]로 나온 이후에 취해주는 Positional Encoding 기법이다. Positional Encoding은 왜 필요할까? 우선 기존에 배웠던 seq2seq 모델은 RNN 계열을 사용하기 때문에 입력, 출력 시퀀스 내부의 시간적인 순서를 고려할 수 있었다. 하지만 오늘 배운 트랜스포머 모델은 RNN을 사용하지 않기 때문에 입력, 출력 시퀀스 내부의 시간적인 순서를 고려할 수가 없다.
따라서 트랜스포머 모델에도 입력, 출력 시퀀스 내부의 위치(Position)적인 정보를 제공하자는 목적 하에 Positional Encoding 이라는 기법을 도입했다. 논문에서는 Positional Encoding을 하는 다양한 방법들이 있지만 그 중에서도 Sin, Cos 함수를 활용했다. Sin, Cos 함수를 활용하면 모델이 토큰들 간에 상대적인 위치를 쉽게 학습할 것이라고 가정했기 때문이다. 또한 Sin, Cos 함수를 사용한 선형회귀식을 만들어 다른 위치의 토큰을 상대적으로 고려할 수도 있는데, 이에 대해서는 매우 설명이 잘된 블로그를 참조하면 좋을 듯 하다.
어쨌거나 Positional Encoding은 차원 수가 $d_{model}$인데, 이는 Embedding Layer 벡터의 차원 수와 동일한 것을 의미한다. 그렇기 때문에 Positional Encoding 벡터와 Embedding Layer 벡터를 더해(sum)주는 것이 가능해진다. 이렇게 함으로써 트랜스포머 모델도 RNN 계열 모델을 사용한 것처럼 입력, 출력 시퀀스 내의 순서를 고려할 수 있게 되었다.
참고로 논문에서는 선정한 Positional Encoding 기법 말고 시도한 다른 방법으로서 Positional Embedding을 사용하기도 했다. 이는 특정 논문에서 제안한 이미 학습된 Embedding 벡터를 Embedding Layer의 벡터와 더해(sum)주는 것이다. 두 가지 기법을 모두 사용해본 결과, 모델의 성능은 거의 비슷했다고 한다. 하지만 이미 학습된 벡터인 Positional Embedding은 학습될 때 보았던 특정 범위 길이의 시퀀스만 처리하는 데 특화되어 있기 때문에 '못보던 경우' 즉, 학습 때 본 범위 길이를 넘어가는 시퀀스는 잘 처리하지 못하게 된다. 따라서 못보던 경우도 잘 처리할 수 있는(이를 논문 상에서 Exploration, Extrapolate 라고도 함) Positional Encoding 기법으로 최종 선택했다고 한다.
4. Transformer는 Self-Attention으로 어떤 효과를 보았는가?
지금까지 트랜스포머 모델이 등장하게 된 이유와 모델 구조를 살펴보면서 각 구성요소의 역할, 동작과정도 살펴보았다. 그렇다면 트랜스포머는 Self-Attention으로 구체적으로 어떤 효과들을 얻었는지 나열해보면서 포스팅을 마무리하자.
우선은 하나의 레이어 당 전체 연산 복잡도(Computational Complexity)를 줄일 수 있었다. 그리고 RNN 계열에서는 하지 못했던 병렬 처리 연산의 양을 대폭 늘릴 수 있었다. 그래서 자연스레 학습 시간을 많이 감소시킬 수 있었다.
다음은 시퀀스 변환에서의 핵심인 '장기간 의존성(Long-range Dependency)'을 다른 모델에 비해 잘 학습할 수 있었다. 신경망 모델이 순전파, 역전파를 수행(순회, 논문에서는 traverse라고 함)하면서 대응관계가 있는 토큰들 간의 물리적인 거리가 길은지 짧은지는 시퀀스 변환 문제에 있어서 매우 중요하다. 즉, 거리가 짧으면 그만큼 대응관계를 잘 파악할 수 있을 것이고 거리가 길다면 기울기 소실, 폭발같은 문제가 발생할 가능성이 높아 대응관계를 잘 파악하지 못하게 된다.
트랜스포머 모델은 대응관계가 있는 토큰들 간의 물리적인 거리값들 중 최댓값이 다른 모델에 비해 매우 짧다는 특성을 갖고 있다. 그렇기 때문에 '장기간 의존성'을 잘 학습할 수 있고 시퀀스 변환 문제도 잘 해결할 수 있게 된다.
마지막으로는 '어텐션' 이라는 가중치를 시각화 하여 토큰들 간의 대응관계를 눈으로 직접 확인할 수 있다. 즉, 다른 모델에 비해 트랜스포머는 모델이 내뱉은 결과를 해석할 수 있다는 장점이 있다.
지금까지 트랜스포머 원본 논문을 기반으로 직접 내용을 정리해보았다. 예전에는 "트랜스포머 모델을 어떻게 이해하지.." 싶었는데 밑바닥부터 시작하는 딥러닝 2권 책을 통해 기초개념을 정립하고 나니 스스로 논문을 읽는 데 생각보다 시간도 별로 걸리지 않았고 이해하는 데 큰 어려움이 있지 않았다. 다음 포스팅에서는 트랜스포머 모델 구조가 '진짜'로 어떻게 동작하는지 밑바닥부터 살펴보도록 하자. 다음 포스팅에서는 이번 포스팅에서 미처 이해하지 못했던 $key, value, query$가 구체적으로 무엇을 의미하는지 이해할 수 있을 것이다.
'Data Science > 밑바닥부터시작하는딥러닝(2)' 카테고리의 다른 글
| [밑시딥] Transformer 동작과정을 밑바닥부터 뜯어보자! (13) | 2022.01.21 |
|---|---|
| [밑시딥] 어텐션을 적용한 seq2seq을 한층 더 응용해보자 (0) | 2022.01.02 |
| [밑시딥] seq2seq를 더 강력하게, 어텐션(Attention)을 적용한 seq2seq (3) | 2021.12.30 |
| [밑시딥] RNN을 사용한 문장 생성, 그리고 RNN을 이어 붙인 seq2seq(Encoder-Decoder) (0) | 2021.12.26 |
| [밑시딥] 게이트를 추가한 GRU와 RNN LM 성능 개선 방법 (0) | 2021.12.21 |



