🔊 해당 포스팅은 밑바닥부터 시작하는 딥러닝 2권의 교재 내용을 기반으로 자연어처리 딥러닝 신경망을 Tensorflow, Pytorch와 같은 딥러닝 프레임워크를 사용하지 않고 순수한 Numpy로 구현하면서 자연어 처리의 기초를 탄탄히 하고자 하는 목적 하에 게시되는 포스팅입니다. 내용은 주로 필자가 중요하다고 생각되는 내용 위주로 작성되었음을 알려드립니다.

저번 포스팅까지 해서 seq2seq 모델을 '크게' 개선하는 기법으로 어텐션(Attention)을 적용한 seq2seq 모델에 대해 알아보았다. 이번 포스팅은 밑시딥 2권의 마지막 포스팅으로 어텐션을 적용한 seq2seq 모델을 좀 더 응용할 수 있는 몇 가지 방법에 대해 알아보려고 한다.
1. Encoder의 RNN 계열 모델을 양방향(Bidirectional)으로 바꾸자!
우리는 그동안 Encoder에서 단방향의 RNN 계열 모델을 사용해왔다. 여기서 단방향이란, 왼쪽에서 오른쪽으로 가는 방향을 의미한다. 이렇게 단방향으로만 이루어진 Encoder 모델은 단점이 하나 존재한다. 바로 입력 시퀀스의 전체적인 균형을 생각하지 못한다는 것이다. 아래 그림을 보자.

위 그림에서 빨간색 네모칸의 은닉 상태 벡터를 살펴보자. 이 은닉 상태에는 '나', '는', '고양이' 에 대한 정보만 담겨있을 것이다. 왜냐하면 현재 왼쪽에서 오른쪽 방향으로 진행되는 단방향 LSTM을 사용하고 있기 때문이다. 그런데 만약 빨간색 은닉 상태에 '고양이' 단어 이후에 등장하는 단어들에 대한 정보가 필요하면 어떻게 될까? 당연히 단방향 LSTM에서는 '고양이' 단어 이후에 등장하는 '로소', '이다' 라는 단어에 대한 정보는 담기지 못할 것이다.
이렇게 입력 시퀀스의 전체적인 정보를 균형있게 담게 하기 위해서 우리는 양방향 LSTM을 사용할 수 있다. 물론 양방향 LSTM을 사용하기 위해서는 Encoder의 입력 시퀀스에 해당하는 LSTM만 양방향으로 설계해야 한다. Decoder에서의 RNN 계열 층을 양방향으로 바꾸면 안된다는 것이다. 왜냐하면 입력 시퀀스는 어쨌거나 우리가 '정답'을 이미 알고 있어 입력 시퀀스 전체를 학습/테스트 시 모두 갖고 있지만 출력 시퀀스는 학습일 때는 갖고 있을 수 있지만 테스트 시에는 갖고 있을 수가 없기 때문이다. 마치 한국어 ➜ 영어 번역을 테스트 하려는데 이미 번역된 영어 문장을 알고 있는 셈 아닌가!
이제 그러면 Encoder에서 양방향 LSTM을 적용했을 때의 구조를 살펴보자.

우선 기존처럼 왼쪽에서 오른쪽으로 가는 순방향의 LSTM 계층이 존재하고 새롭게 오른쪽에서 왼쪽으로 가는 역방향의 LSTM 계층이 존재하는 것을 알 수 있다. 그리고 각 방향의 LSTM 계층에서 나온 은닉 상태 값을 연결(concatenate)하는 것이다. 이렇게 하면 양방향 LSTM 계층을 완성시킬 수 있다. 물론 각 방향에서 나온 은닉 상태 값을 단순히 '연결' 하지 않고 평균을 내거나 합하는 등 다양한 집계 방법을 취할 수도 있다.
그러면 양방향 LSTM 계층을 넘파이로 구현하는 코드도 살펴보자. 처음에 어떻게 구현하지? 하겠지만 기존에 만든 LSTM 클래스를 활용하되, 역방향 LSTM 계층만 잘 구현해주면 된다. 역방향 LSTM 계층을 구현하기 위해서는 LSTM 계층을 뒤집는 것이 아니라 입력 시퀀스를 뒤집으면 된다! 필자도 소스코드를 보고 이게 왜 이렇게 되지? 했지만 직접 손으로 써보면서 생각해보니 이해가 되었다. 아래 그림을 보자.
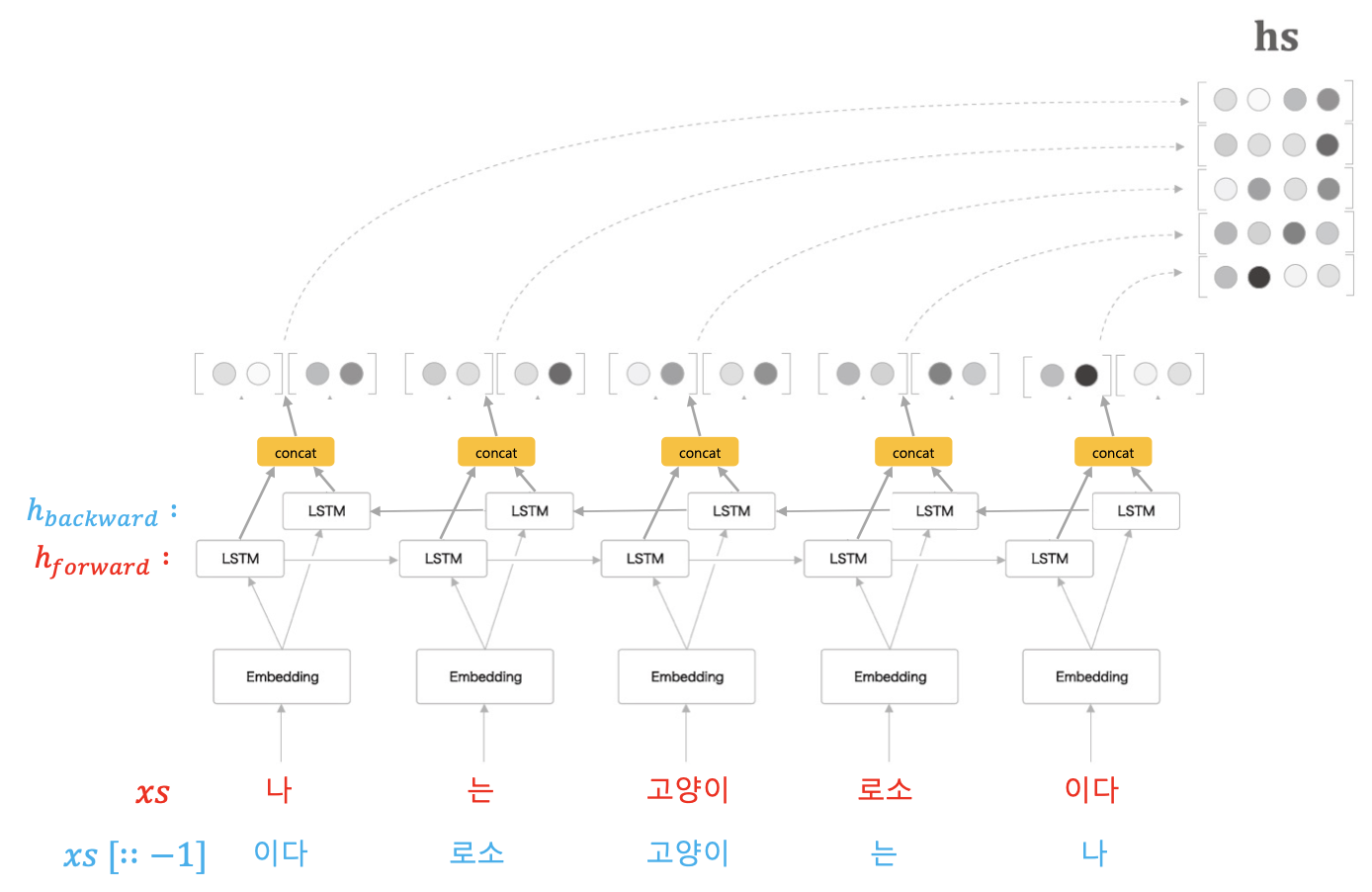
파이썬에 익숙하신 분들은 [::-1] 이 어떤 것을 의미하는지 바로 이해할 것이다. [::-1]은 파이썬의 리스트(또는 넘파이의 배열) 자료구조 순서를 뒤집는 것을 의미하는데, 여기선 말 그대로 원래 입력 시퀀스 $xs$를 뒤집어서 역방향의 LSTM($h_{backward}$)에 넣는다는 의미다. 양방향 LSTM을 넘파이로 구현하기 위해서는 기존에 구현했던 단방향 LSTM을 사용하되 입력만 뒤집어서 넣어주면 된다.
# 양방향 LSTM으로 구성된 Time BiLSTM
from common.time_layers import TimeLSTM
class TimeBiLSTM:
""" 양방향 LSTM을 입력 시퀀스 길이(T)개 한번에 처리하는 클래스
Args:
Wx1, Wh1, b1: 순전파(왼->오) 방향의 LSTM에 들어갈 파라미터
Wx2, Wh2, b2: 역전파(오->왼) 방향의 LSTM에 들어갈 파라미터
"""
def __init__(self, Wx1, Wh1, b1,
Wx2, Wh2, b2, stateful=False):
self.forward_lstm = TimeLSTM(Wx1, Wh1, b1, stateful) # 순전파 방향(왼->오)의 LSTM
self.backward_lstm = TimeBiLSTM(Wx2. Wh2, b2, stateful) # 역전파 방향(오->왼)의 LSTM
# 파라미터, 기울기 취합
self.params = self.forward_lstm.params + self.backward_lstm.params
self.grads = self.forward_lstm.grads + self.backward_lstm.grads
def forward(self, xs):
""" 양방향 LSTM 순전파
Args:
xs: 입력 시퀀스 전체
"""
o1 = self.forward_lstm.forward(xs)
o2 = self.backward_lstm.forward(xs[:, ::-1])
o2 = o2[:, ::-1] # 다시 뒤집어야 함!
# concat 노드
out = np.concatenate((o1, o2), axis=2)
return out
def backward(self, dhs):
""" 양방향 LSTM 역전파
Args;
dhs: Encoder가 내뱉은 모든 은닉상태 모음의 기울기
"""
H = dhs.shape[2] // 2 # 은닉상태 차원 수를 2로 나누기(하나는 순전파 방향의 LSTM, 하나는 역전파 방향의 LSTM)
do1 = dhs[:, :, :H]
do2 = dhs[:, :, H:]
# 순전파 방향의 LSTM 역전파
dxs1 = self.forward_lstm.backward(do1)
# 역전파 방향의 LSTM 역전파
do2 = do2[:, ::-1] # 뒤집기
dxs2 = self.backward_lstm.backward(do2)
dxs2 = dxs2[:, ::-1]
dxs = dxs1 + dxs2
return dxs2. Attention 계층을 다른 곳에다도 넣어보자!
이번 목차는 어텐션 계층을 기존과 다른 위치로 옮김으로써 어텐션 계층을 좀 더 다양하게 활용하는 방법이다. 우선 우리가 처음 어텐션을 배울 때, seq2seq 모델의 어느 부분에다가 삽입했었는지 다시 상기시켜보자.

물론 위 그림에서 Affine 계층으로 들어가는 2가지 입력 데이터를 연결(concatenate) 해주는 노드가 엄밀히 말하면 빠지긴 했지만, 어쨌거나 어텐션 계층을 위 그림의 위치에 그동안 활용했던 건 맞다. 그러면 어텐션 계층을 다른 어디로 옮길 수 있을까? 책에서도 소개하는 실제 어떤 논문에서 제안한 어텐션 계층의 새로운 위치는 다음과 같다.
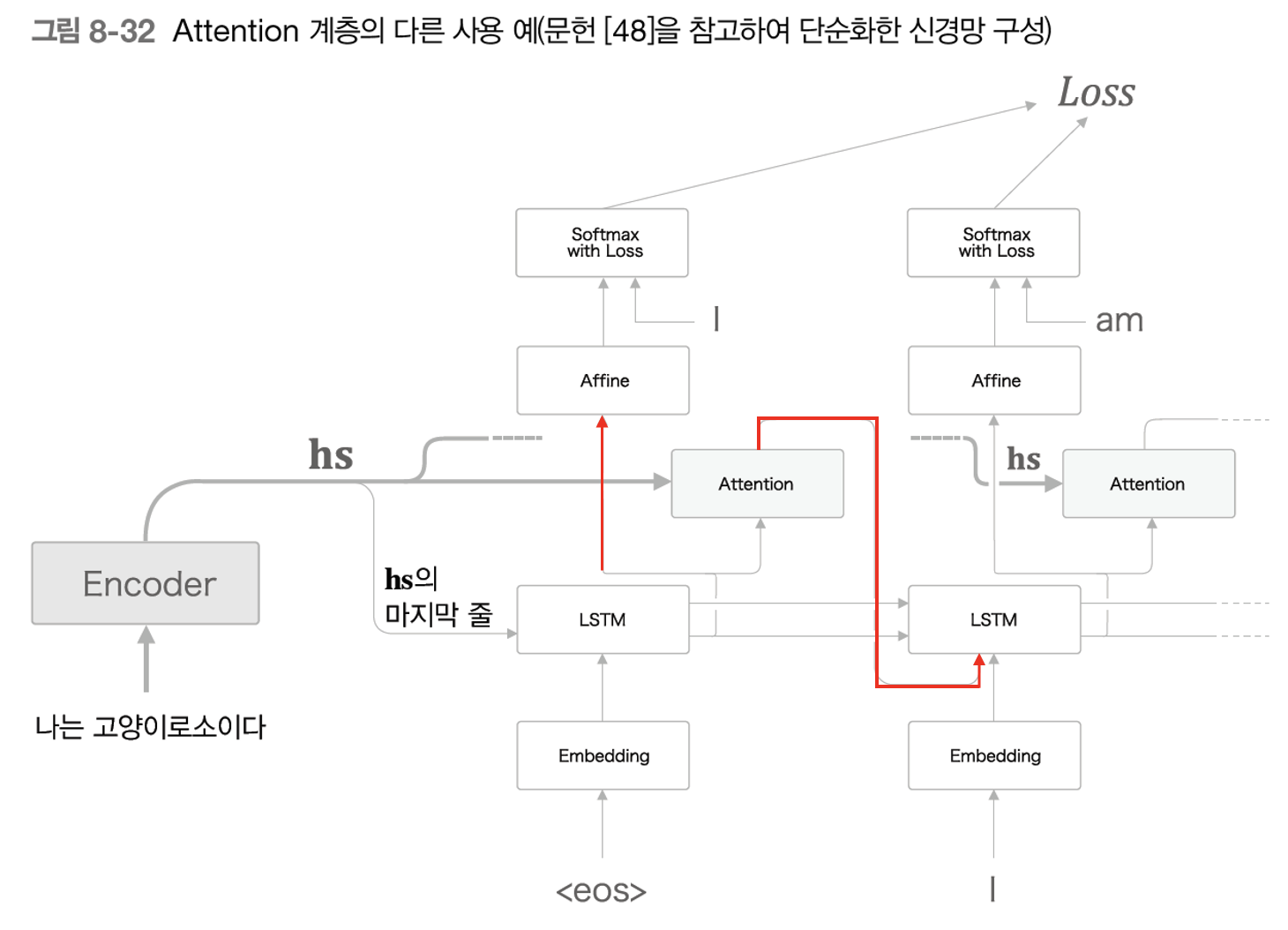
기존과 달라진 점을 빨간선으로 표시해보았다. 기존에는 Affine 계층에 LSTM에서 나온 은닉 상태($h_{LSTM}$)와 어텐션 계층에서 나온 맥락 벡터($c$) 2개가 입력으로 들어갔지만 이번에는 $h_{LSTM}$ 1개만 입력으로 들어가는 것을 볼 수 있다. 대신 어텐션에서 배출하는 $c$는 다음 순서의 LSTM 계층의 입력으로 들어가게 된다. 이렇게 하게 되면 LSTM 계층이 맥락 벡터($c$)를 이용할 수 있게 된다. 맥락 벡터를 이용한다는 것은 곧 LSTM 계층도 입력-출력 시퀀스 간의 대응 관계를 이용할 수 있다는 것이다.
물론 이렇게 다양하게 어텐션의 위치를 옮긴다는 것이 기존 어턴센의 위치보다 더 높은 성능을 보장하는 것은 아니다. 결과론적으로 성능을 측정해봐야 알 수 있게 된다.
3. seq2seq를 더 깊게! , 그리고 Skip Connection
seq2seq란, Encoder-Decoder 라고도 부른다고 했다. 즉, Encoder와 Decoder로 구성된다는 것인데, 이것은 순환하는 신경망인 RNN을 2개 이어붙인 모델이었다. 이번 목차에서 말하고자 하는 바는 다음과 같다. seq2seq 모델도 RNN을 사용한다. 그러므로 RNN을 깊게 쌓음(다층화)으로써 다층화(심층화)시킨 seq2seq 모델도 구현할 수가 있다.

위 그림은 각 Encoder, Decoder에 있는 LSTM 모델을 3층으로 다층화시킨 seq2seq 모델이다. 보통 다층화시킬 때는 Encoder, Decoder의 층수를 동일하게 맞추는 것이 일반적이다. 이렇게 다층화시켜 seq2seq 모델을 구성하면 더 복잡한 패턴도 파악할 수 있는 표현력이 높은 모델을 구축할 수 있다. 단, 계층을 깊게 할 경우에는 모델의 일반화 성능(과적합이 발생하지 않도록!)을 떨어뜨리지 않도록 하는 것이 중요하다. 일반화 성능을 유지하기 위해서는 보통 드롭아웃과 가중치 공유 등의 기술이 효과적이다.
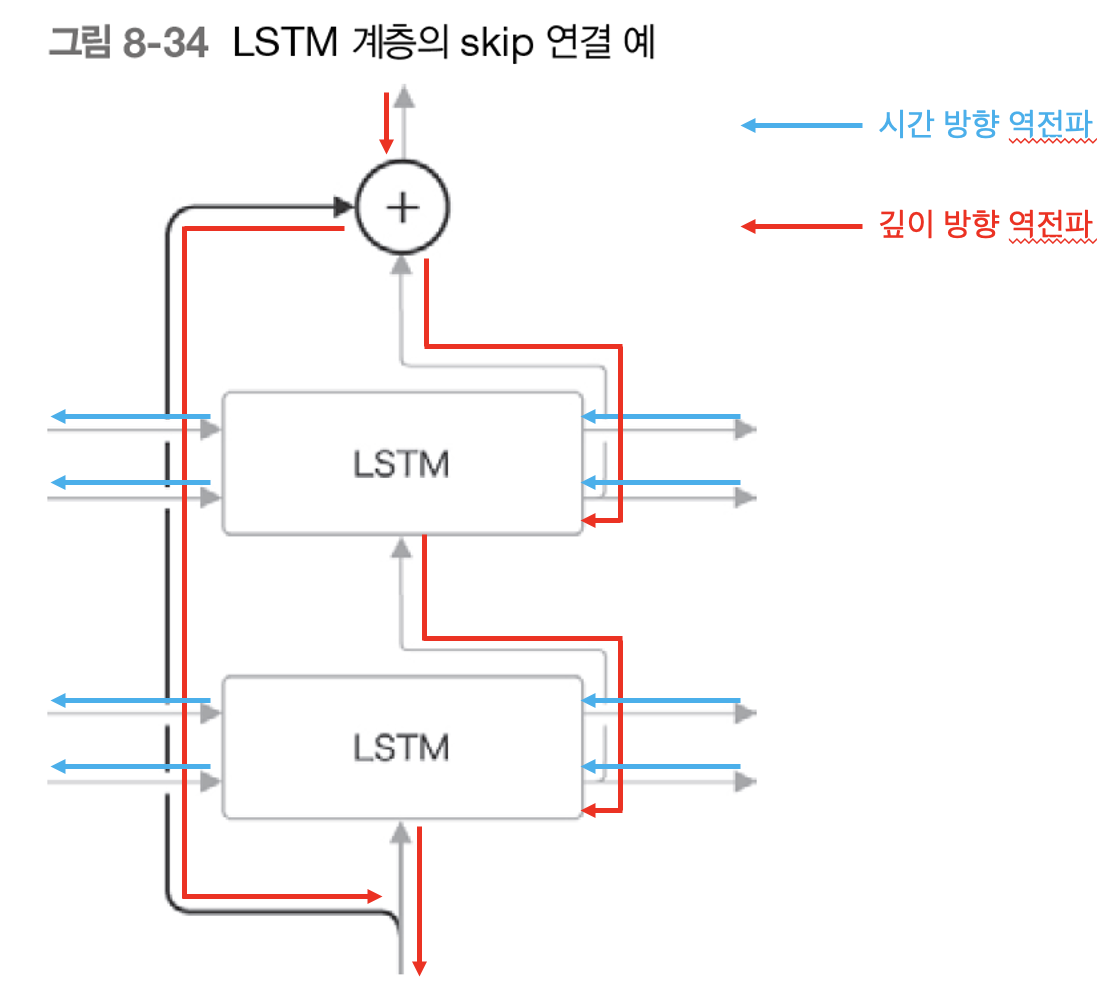
이렇게 다층화시킨 seq2seq 모델의 일반화 성능을 떨어뜨리지 않는 방법 중 하나로 Skip Connection 기법이 있다. 예전 포스팅에서 다층화시킨 RNN 모델 1개를 사용해 만든 언어 모델의 성능을 떨어뜨리지 않는 방법으로 가중치 공유(Weight tying) 기법을 배우면서 Skip Connection에 대해 언급한 적이 있었다. 컴퓨터 비전 분야의 이미지 분류 모델 중 하나인 ResNet에서 등장한 기법이다.

위처럼 Skip Connection은 출력값을 깊이 방향의 다음 LSTM 계층 출력값에 더해주는 방식으로 수행해준다. 그런데 왜 곱셈도 나눗셈도 뺄셈도 아닌 덧셈일까? 예전에 계산 그래프를 통해서 덧셈 연산일 경우의 역전파 방식을 생각하면 알 수 있다. 덧셈 연산을 역전파로 수행해줄 때는 이전으로부터 흘러들어온 기울기(국소적인 미분값)를 건드리지 않고 그대로 흘려보낸다. 이는 곧 순전파를 수행하면서 덧셈 연산을 아무리 추가해도 역전파 과정에서 기울기가 소실되거나 폭발하는 문제가 발생할 수가 없기 때문이다.
따라서, 다층화시킨 LSTM 계층에서 깊이 방향으로의 기울기 소실, 폭발 문제는 Skip Connection을 활용해 해결할 수 있다. 반면에 시간 방향에서의 기울기 폭발은 Gradient Clipping으로, 기울기 소실은 게이트가 추가된 LSTM, GRU 모델로 구조를 뜯어고침으로써 해결할 수 있다.
지금까지 밑시딥 2권에서 필자가 새롭게 배운 내용이거나 중요하다고 생각하는 내용에 대한 챕터 블로깅을 모두 마쳤다. 중간중간 힘든 순간도 있었지만 모델을 그야말로 '밑바닥'부터 넘파이로 설계해보면서 여태껏 중 가장 깊이 있게 딥러닝 모델을 공부한 큰 경험이었다.
책 마지막 챕터에 seq2seq의 Encoder, Decoder의 RNN을 제거하고 RNN 대신 어텐션 계층만 적용한 Transformer(트랜스포머) 모델에 대해 간단히 소개한다. 이에 대해서는 여기서 짧막하게 소개하기 보다는 조만간 책에서 간단히 소개하는 트랜스포머 내용과 트랜스포머 원 논문을 공부한 후, 종합적으로 정리해서 블로깅해보려고 한다.
'Data Science > 밑바닥부터시작하는딥러닝(2)' 카테고리의 다른 글
| [밑시딥] Transformer 동작과정을 밑바닥부터 뜯어보자! (13) | 2022.01.21 |
|---|---|
| [밑시딥] RNN의 역할도 어텐션으로 대체한 seq2seq 모델, Transformer (4) | 2022.01.17 |
| [밑시딥] seq2seq를 더 강력하게, 어텐션(Attention)을 적용한 seq2seq (3) | 2021.12.30 |
| [밑시딥] RNN을 사용한 문장 생성, 그리고 RNN을 이어 붙인 seq2seq(Encoder-Decoder) (0) | 2021.12.26 |
| [밑시딥] 게이트를 추가한 GRU와 RNN LM 성능 개선 방법 (0) | 2021.12.21 |



