🔊 해당 포스팅은 밑바닥부터 시작하는 딥러닝 2권의 교재 내용을 기반으로 자연어처리 딥러닝 신경망을 Tensorflow, Pytorch와 같은 딥러닝 프레임워크를 사용하지 않고 순수한 Numpy로 구현하면서 자연어 처리의 기초를 탄탄히 하고자 하는 목적 하에 게시되는 포스팅입니다. 내용은 주로 필자가 중요하다고 생각되는 내용 위주로 작성되었음을 알려드립니다.

이전 포스팅까지는 Feed-Forward Neural Network(FNN)에 대해서 다루었다. 단어의 분산을 표현하기 위해 학습시켰던 신경망 모델인 CBOW 모델, Skip-gram 모델 모두 하나의 은닉층으로 하는 FNN 신경망 모델이었다. 하지만 이 FNN 모델은 순서가 중요한 특성으로 여겨지는 시퀀스 데이터 즉, 시계열 데이터를 잘 다루지 못하는 한계점이 존재한다. 그래서 이번 포스팅부터는 FNN의 한계점을 극복하는 즉, 시계열 데이터의 패턴을 잘 학습할 수 있는 순환신경망(RNN)에 대해 알아보고 이를 넘파이로 구현해본다.
1. CBOW 모델을 언어 모델(Language Model)로 활용?
RNN에 대해 본격적으로 알아보기에 앞서 저번 포스팅까지 배웠던 FNN 모델 중 하나인 CBOW 모델을 잠깐 언급하고 가자. CBOW 모델은 주변의 맥락 데이터로부터 타깃 데이터를 예측하는 모델이라고 했다. 수식으로 나타내면 아래와 같다.
$$P(w_t | w_{t-1}, w_{t+1})$$
위 수식은 타깃 단어를 기준으로 좌,우 하나씩을 맥락 데이터로 간주했을 경우의 수식이다. 만약 맥락 단어를 타깃 단어의 모두 왼쪽으로 바꾸어 버린다면 아래 수식처럼 변경될 것이다.
$$P(w_t | w_{t-1}, w_{t-2})$$
위 수식은 말 그대로 $t-2$번째 단어와 $t-1$번째 단어(맥락 단어들)가 발생했을 때, $t$(타깃 단어) 번째 단어가 발생할 확률을 의미한다. 이렇게 맥락 단어를 모두 왼쪽으로 바꿔버린 이유는 CBOW 모델을 언어 모델로 활용했을 경우를 설명하기 위함이다.
그런데 언어 모델이란 무엇일까? 저번 포스팅 말미에서 잠깐 이야기 했지만 언어 모델은 위 변경된 수식처럼 $t-2$번째 단어와 $t-1$번째 단어가 발생했을 때, 다음 순서로 나올 단어인 $t$번째 단어가 무엇으로 나올지 예측하는 모델이다. 즉, 다음 순서에 나올 단어의 자연스러움을 하나의 확률 지표값으로 예측하는 것이다. 이러한 언어 모델은 음성 인식 시스템이나 새로운 문장을 생성하는 용도로 자주 사용된다.
그러면 언어 모델을 확률 수식으로 살펴보자. 예를 들어, $m$개의 단어($w_1, w_2, ..., w_m$)가 있다고 가정할 때, 단어가 $w_1, w_2, ... , w_m$ 순서로 발생할 확률을 $P(w_1, w_2, ... , w_m)$으로 정의할 수 있다. 이를 동시 확률이라고 한다. 이 동시확률을 사후확률로 나타낼 수 있다. 사후확률은 저번 포스팅의 목차 '6. CBOW 모델과 확률의 관계' 에서 살펴본 개념이므로 따로 소개하지 않겠다. 다음 수식을 보자.
$$\begin{matrix} P(w_1, w_2, ... , w_m) &=& P(w_m | w_1, ... , w_{m-1}) P(w_{m-1} | w_1, ... , w_{m-2}) \cdots P(w_2 | w_1) P(w_1) \\ &=& \prod_{t=1}^m P(w_t | w_1, w_2, ... , w_{t-1}) \end{matrix}$$
위 수식에서 $\prod$(파이) 기호는 모든 원소를 곱하는 총곱을 의미한다. 즉, 동시확률은 사후 확률의 총곱으로 나타낼 수 있다. 그러면 위 수식의 결과를 하나씩 분해해서 살펴보자.
분해하기 위해서는 확률의 곱셈정리를 알아야 한다. 베이즈 정리에서 주로 활용되는 조건부 확률이라고하면 아시는 분들이 많을 것이다.
$$P(A, B) = P(A \cap B) = P(A | B) P(B)$$
즉, A, B가 모두 일어날 확률은 B가 일어날 확률과 B가 일어난 후 A가 일어날 확률을 곱해준 것과 같다.(여기서는 B가 조건부로 주어진다고 가정했을 경우의 수식이다. 만약 A가 조건부로 주어진다고 가정하면 수식에서 A, B를 서로 바꿔주어야 한다)
그렇다면 위의 확률의 곱셈정리를 활용해서 동시확률을 사후확률의 총곱으로 나타낼 수 있다.

위 수식은 $w_m$ 단어에 대해 정리한 것이다. $w_1, w_2, .. , w_{m-1}$ 단어가 순차적으로 발생할 동시확률을 간단히 표시하기 위해 $A$라는 것으로 치환했다. 그리고 난 후 확률의 곱셈정리를 이용해 사후확률로 분해해주면 위 그림의 가장 오른쪽으로 분해가 된다. 이번엔 그러면 $w_{m-1}$ 단어에 대해 똑같이 수행해보면 아래와 같아진다.

이번엔 $w_1, w_2, .. , w_{m-2}$ 단어가 순차적으로 발생할 동시확률을 $A'$으로 치환했다. 그리고 사후확률로 분해해주면 위와 같이 된다. 이렇게 분해하는 과정을 계속 반복하여 $w_1$ 단어까지 수행해주게 되면 결국 사후확률의 총곱인 $\prod_{t=1}^m P(w_t | w_1, w_2, ... , w_{t-1})$로 된다는 것을 알 수 있다. 참고로 이렇게 확률의 곱셈정리인 조건부 확률을 이용한다고 해서 위와 같은 수식의 언어 모델을 조건부 언어 모델이라고도 한다.
그렇다면 위 수식을 기반으로 타깃 단어 기준 왼쪽 2개의 맥락 단어를 이용한 CBOW 모델을 언어 모델로 활용한다고 했을 경우에, 수식은 아래와 같아진다.

위 그림처럼 원래 $t$개의 맥락 단어를 활용한 조건부 언어 모델을 2개의 맥락 단어로 일종의 근사시킨 언어 모델이 바로 CBOW 모델을 활용한 언어모델인 셈이다. $t$개의 맥락 단어를 활용해 예측한 것이 어떻게 2개의 단어 즉, $t-2, t-1$ 단어로만 예측한 것이랑 확률 값이 어떻게 비슷하냐라는 것에 대해 의문을 제기할 수 있다.
이는 수학적 이론은 마르코프 체인을 가정한 것이다. 예전 Hidden Markov Model에 대한 포스팅을 한 적이 있는데, 마르코프 체인은 간단히 말하면, 현재 $t$ 시점의 값은 과거 전체의 시점에 상관없이 직전의 시점인 $t-1$ 시점의 값에만 영향을 받는다라는 이론이다. 물론 이 정의는 $t-1$이라는 직전 1개에만 의존한다고 하여 1층 마르코프 체인이라고 한다. 만약 직전 2개에만 의존한다고 하면 2층 마르코프 체인, 직전 $N$개에만 의존한다고 하면 $N$층 마르코프 체인이라고 한다.
그래서 위 CBOW 모델은 현재 직전 2개의 단어들만 고려하기 때문에 2층 마르코프 체인 이론에 기반하여 위 그림의 가장 오른쪽 수식으로 근사시킬 수 있게 된다. 그런데 이렇게 직전 2개의 단어만 고려하게 되면 문제가 발생할 가능성이 존재한다. 말 그대로 직전 2개의 단어만 고려하고 그 이전의 단어들은 아예 배제해버리기 때문이다.
그렇다면 CBOW 모델을 만들 때, 고려하는 맥락 단어 개수를 엄청나게 크게 늘리면 되지 않을까? 할 수 있다. 하지만 맥락 크기에 상관없이 CBOW 모델은 내부적으로 단어의 순서를 무시하게 된다. 예전에 살펴본 맥락 데이터 2개를 고려했을 경우의 CBOW 모델 구조를 잠시 살펴보자.

위 그림에서 주목할 부분은 파란색 동그라미이다. CBOW 모델에서 맥락 2개 데이터를 입력으로 받은 후, 은닉층으로 보내면서 1개의 맥락 데이터에 대해 은닉층 결과값을 단순히 더한 후 평균값을 내주는 식으로 구현된다는 것을 배웠다. 이렇게 '단순히 더한 후 평균을 낸다는 것' 때문에 입력으로 들어가는 맥락 데이터들의 순서가 고려되지 않는다는 것이다!(이렇게 모델 안에서 단어의 순서가 고려되지 않는다고 하여 CBOW 모델이 일명 가방 속의 단어라고 'Bag Of Words(BOW)' 라고 불리는 이유이다)
물론 CBOW 모델의 단어 순서롤 고려하지 않는다는 문제점을 극복하기 위해 시도한 방법도 존재한다. 바로 아래처럼 각 맥락 데이터를 입력시킨 후 나온 은닉층 결과값을 연결(concatenate)하여 출력해주는 시도도 있었다.(아래의 오른쪽 그림)

오른쪽 그림과 같은 모델을 신경 확률론적 언어 모델(Neural Probablistic Language Model)이라고 한다. 하지만 이 모델은 은닉층을 연결하기 때문에 자연스레 은닉층의 노드 수도 증가하게 된다. 그렇게 되면 고려하는 맥락의 크기에 비례하여 은닉층의 노드 수도 같이 증가하게 될 것이고 그러면 은닉층과 출력층 사이의 파라미터인 $W_{out}$의 행렬도 커지며 계산해야 하는 파라미터 수도 엄청나게 증가하게 된다.
이렇게 은닉층을 '연결' 한다는 신경 확률론적 언어 모델도 연산량 문제라는 게 발생한다. 그래서 이 연산량 문제도 해결하고 단어의 순서도 고려할 수 있는 해결책으로 바로 순환신경망(RNN)이 등장하게 된다.
2. 순환신경망(RNN)
Recurrent Neural Network의 준말인 RNN은 말 그대로 '순환하는' 신경망을 의미한다.(참고로 Recursive Neural Network라는 것도 있는데, 이는 우리가 지금 배우는 RNN과는 다른 것이라고 한다. 주로 트리 구조의 데이터를 처리하기 위한 신경망이 Recursive Neural Network라고 한다)
RNN은 '순환'한다는 것에 무엇을 순환시킨다는 것일까? 바로 뉴럴 네트워크에서 나오는 출력을 뉴럴 네트워크의 입력으로 다시 넣어준다는 것을 의미한다. 그래서 순환시키기 위해서 RNN에는 순환하는 경로인 '닫힌 경로'가 필요하다.(여기서 '닫힌' 이라는 키워드 때문에 개인적으로 이해가 확 와닿지 않아서 '닫힌 경로'를 그냥 '순환하는 경로'로 필자는 이해했다)
RNN은 이 순환하는 경로를 통해서 과거의 정보를 기억하면서 최신 데이터로 갱신할 수 있게 된다. RNN 계층 하나를 도식화해보면 아래와 같다.

위 그림을 보면 $x_t$라는 입력 데이터(입력 벡터)가 RNN 네트워크로 들어간다. 그리고 $h_t$라는 출력값이 나오게 되는데, RNN은 여기서 출력값인 $h_t$를 두 갈래길로 분기(복제)시켜 보낸다. 한 쪽은 말 그대로 출력값으로 보낸다. 그리고 한 쪽은 순환하는 경로를 통해서 $h_t$값을 태워 다시 RNN 네트워크로 들여보낸다. 위 그림은 순환하는 구조를 표현하다 보니 느낌이 와닿지 않을 수 있다. 그러면 이 순환하는 구조를 옆으로 펼쳐서 도식화해보면 아래와 같다.

위 그림처럼 RNN의 출력값인 $h_t$ 값이 하나는 출력하는 갈래로 가고 동일한 $h_t$ 하나는 다음 RNN 계층으로 들어가게 된다. 그래서 $x_0$가 들어가는 맨 처음 RNN 계층($x_0$일 때)을 제외한 나머지 계층들은 $x_t$와 $h_{t-1}$ 두 개의 입력을 받게 된다. 그래서 각 RNN 계층의 출력값인 $h_t$를 계산하는 수식을 나타내면 아래와 같다.
$$h_t = tanh(h_{t-1}W_h + x_t W_x + b)$$
RNN 계층은 피드포워드 신경망과는 달리 Bias값인 $b$를 제외하고도 2개의 가중치가 필요하다. 첫 번째는 $t$시점의 입력 데이터인 $x_t$와 곱해지는 가중치 값($W_x$)이다. 두 번째는 이전 RNN 계층으로부터 흘러들어오는 $h_{t-1}$와 곱해지는 $W_h$라는 가중치 값이다. 이 때, 이전 RNN 계층에서 흘러들어오는 $h_{t-1}$를 은닉 상태(hidden state) 혹은 은닉 상태 벡터라고 한다. 그래서 RNN 계층을 '상태'를 가지는 계층 혹은 '메모리(기억)'을 가지는 계층이라고도 한다.

그런데 위 그림에서 주의해야 할 부분이 있다. 위 그림은 RNN 구조에 대한 이해를 손쉽게 하기 위해 옆으로 펼쳐놓았다고 가정했기 때문에 위 수식에서 $x$가 $t$ 방향으로 감에 따라 $W$ 라는 파라미터 값들이 여러개 존재한다고 생각할 수 있다. 하지만 추후에 넘파이 코드로 구현하는 과정에서 알 수 있지만 $W_{h_t-1}, W_{x_t}, b$ 라는 각 파라미터는 한 개씩만 존재하며 순환하면서 같은 파라미터인 $W_{h_t-1}, W_{x_t}, b$을 계속 갱신시키는 것이다. 무슨 말인지 잘 이해가 되지 않는다면 아래 그림을 통해 이해하자.

3. RNN의 오차역전파, BPTT와 Truncated BPTT
위 목차에서 순환하는 RNN 구조를 펼쳤을 때의 구조를 살펴보았다. 아래 그림처럼 펼쳐본 구조로 보니 RNN도 순전파, 역전파가 적용될 수 있다는 것을 직관적으로 알 수 있다. 즉, 순전파를 순서대로 진행한 후, 역전파를 수행해 파라미터의 기울기 값을 구할 수 있다. RNN에서의 오차역전파법은 오른쪽으로 갈수록 즉, 시간이 흐르는 방향대로 펼친 신경망의 오차역전파라고 하여 BPTT(Backpropagation Through Time)이라고 한다.
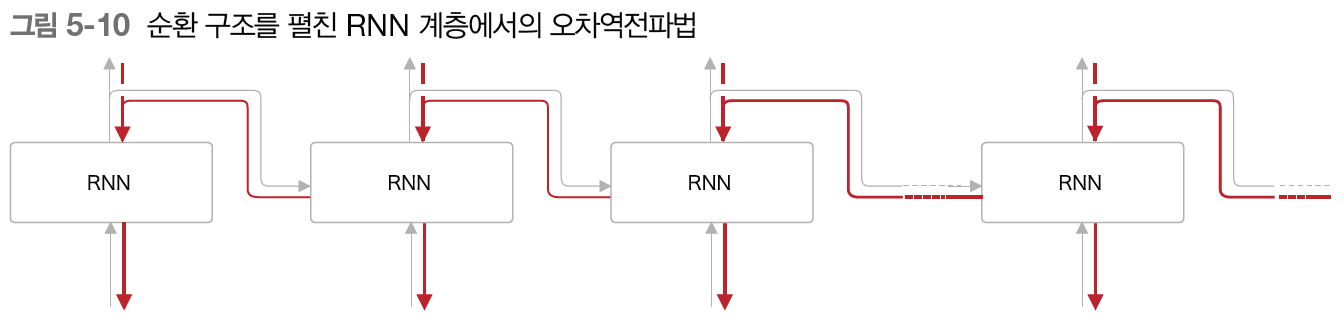
위 그림의 빨간색이 RNN에서의 오차역전파인 BPTT를 의미한다. 그런데 이러한 BPTT 방법은 문제점이 있다. 긴 시계열 데이터를 학습할 때이다. 왜냐하면 시계열 데이터의 길이가 길어짐에 비례하여 BPTT가 소비하는 컴퓨팅 연산량도 증가하기 때문이다. 컴퓨팅 연산이 증가하는 이유는 BPTT를 이용해 기울기를 구하려면 각 RNN 계층마다 거쳐간 중간 데이터를 메모리에 모두 유지해야 하기 때문이다. 또한 시간 길이가 길어지면서 역전파 시 기울기가 소실되는 문제가 발생할 수 있다.
그래서 이 문제를 해결하기 위해 긴 시계열 데이터일 때는 RNN 신경망 연결을 적당한 길이로 끊는 Truncated BPTT가 등장한다. Truncated BPTT는 너무 길이가 길어지는 RNN 신경망을 적당한 지점에서 잘라내어서 작은 RNN 신경망 여러개로 만든다는 아이디어이다. 그리고 잘라낸 각 신경망에서 오차역전파를 수행한다. 단, 주의할 점은 역전파일 때만 잘라내야 한다는 것이다. 순전파일 때는 잘라내지 않고 계속 출력값 $h_t$을 다음 RNN 계층으로 보내야 한다. 무슨 말인지 잘 모르겠다면 아래의 그림을 살펴보자.
우선 아래 그림처럼 긴 RNN 신경망이 있고 앞 부분을 3개의 작은 RNN 신경망으로 잘라낸다고 가정하자.

그럼 우선 1번 보라색 신경망에서 2번 녹색 신경망으로 순전파, 역전파가 어떤 순서로 진행되는지 살펴보자.

위 그림에서 노란색으로 칠해진 텍스트 번호를 순서대로 천천히 과정을 따라가보자. 보면 가장 첫 번째 작은 신경망인 1번 보라색 신경망의 순전파 과정을 수행한다. 그리고 보라색 신경망에 대한 역전파를 수행하는데, 이 때 보라색 신경망의 최종 출력힌 $h_9$는 다음 녹색 신경망으로 전달해주어야 하기 때문에 $h_9$ 값을 잠시 메모리에 저장해준다. 왜냐하면 위에서도 언급했다시피 Truncated BPTT는 역전파의 연결을 끊되 순전파는 계속 이어지도록 해주어야 하기 때문이다.
그리고 난 후, 보라색 신경망의 역전파 과정을 수행하고 완료한 뒤, 2번 녹색 신경망의 순전파를 수행한다. 이 때, 아까 메모리에 저장해둔 $h_9$ 즉, 이전 보라색 신경망의 최종 출력값을 은닉 상태로 전달해줌으로써 보라색 신경망에 대한 기억을 유지시키도록 한다. 이 과정을 2번 녹색에서 3번인 주황색 신경망도 동일하게 수행해준다. 그래서 Truncated BPTT 순서를 그림으로 표현하면 아래와 같다.

위 그림은 데이터를 10개마다 작은 신경망으로 잘라낸 Truncated BPTT의 예시이다. 그리고 배치 사이즈가 1개일 경우의 예시이다. 그렇다면 배치사이즈가 여러개일 경우엔 어떤 구조로 바뀔까? 아래 그림은 전체 시계열 데이터 길이가 1,000일 때, 10개 마다 작은 신경망으로 잘라냈고 배치 사이즈가 2일 경우의 그림이다.

만약 배치 사이즈가 늘어났다면, 배치 데이터 마다 시작 위치를 늘려주면 된다. 예를 들어, 위의 데이터 같은 경우, 원래는 길이가 1,000인 데이터를 10개 마다 작은 신경망으로 잘라내고 배치 사이즈가 1일 경우에는 $t_0, ... , t_9$ 까지 작은 신경망 1개, $t_{10}, ... , t_{19}$ 까지 작은 신경망 1개$, ... , $ $t_{990}, ... , t_{999}$ 작은 신경망 1개 이런 식으로 분할했다.
하지만 배치 사이즈가 2로 늘어날 경우, 1개의 배치 당, $t_0, ... , t_9$ 작은 신경망과 $t_{500}, ... , t_{509}$ 작은 신경망 이렇게 총 2개의 작은 신경망을 한 번에 학습시킨다. 이렇게 계속 배치를 나눌 경우, 마지막 배치에는 $t_{490}, ... , t_{499}$ 작은 신경망과 $t_{990}, ... , t_{999}$ 작은 신경망을 한 번에 학습시키게 될 것이다.
(참고로 이렇게 배치사이즈를 여러개 여기서는 2개로 한다면 첫 Epoch에는 $t_{499}$에서 $t_{500}$ 으로 전달하는 은닉 상태 벡터는 없을 것이다. 하지만 두 번째 Epoch 부터는 $t_{499}$에서 $t_{500}$ 으로 전달하는 은닉 상태 벡터가 저장될 것이다. 이에 대해 언급하는 이유는 필자가 배치 사이즈를 여러개로 했을 때 가만히 생각했을 때 문득 의문을 가졌고, 이와 관련해 글을 작성한 다른 블로거 분과 소통을 한 후 최종 결론을 내릴 수 있었다! 역시 집단 지성의 힘!)
4. RNN 구현
이제 RNN 이론에 대해 살펴보았으니 RNN을 넘파이 코드로 구현해보자. 구체적인 구현 소스코드를 여기다 게시해놓으면 너무 내용이 길어질 뿐만 아니라 어차피 가시적으로도 보기가 힘드므로 소스코드는 필자가 한줄씩 따라쳐보면서 정리한 깃헙 링크를 첨부해 놓겠다. 여기서는 RNN을 구현하기 위해 필요한 부분들에 대해 살펴보자. 그 중 첫번째는 RNN 계층 내에서 행렬 형상의 아다리 맞추기, 그리고 두 번째는 RNN 계층 내에서 역전파 계산 방법이다.
4-1. RNN 계층 내 행렬 형상의 아다리 맞추기
RNN 계층 내에서의 출력값인 은닉 상태 벡터 $h_t$를 계산하는 수식을 다시 살펴보자.
$$h_t = tanh(h_{t-1}W_h + x_t W_x + b)$$
위 수식에서 각 변수에 대한 파라미터 행렬의 형상을 맞추는 방식을 도식화해보면 다음과 같다.

위 형상 공식대로 넘파이에서 구현해주면 된다.
4-2. RNN 계층 내 역전파 계산 그래프
RNN 계층에서 역전파를 구현하는 방법에 대해 알아보자. 우선 RNN 계층 내에서 순전파를 수행하는 것을 계산그래프로 나타내보면 아래와 같다.

위 과정을 역전파해보기 전에, 그동안 우리가 배웠던 노드 연산 중에 $tanh$에 대한 역전파 연산은 어떻게 되는지에 대해 배우지 못했다. 이에 대해서는 책의 부록에서 자세히 수식으로 다룬다. 여기서는 간단하게만 서술하려 한다. $tanh$ 공식은 아래와 같다.
$$y = tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$$
이것을 $x$에 대해 미분을 수행해야 하는데, 이 때 분수 함수의 미분 공식과 네이피어 수($e$, 자연상수라고도 불리는 듯 하다. 출처: 나무위키)에 대한 미분을 해석적으로 유도하게 되면 $tanh$에 대한 미분 후 나오는 수식은 아래와 같다.
$$\begin{matrix} \partial tanh(x) \over\partial x &=& 1 - tanh(x)^2 \\ &=& 1 - y^2 \end{matrix}$$
결국 $tanh(x)$ 연산에 대한 미분값은 입력 $x$를 $tanh$ 연산 취해준 $y$ 제곱한 값을 1에서 빼준 값이 된다! 이런 수식 유도로 인해 $tanh$ 미분 값을 쉽게 계산할 수 있고 이를 RNN 계층 내 역전파 구현 시에 사용하면 역전파 계산식이 매우 간단하게 된다. 그렇다면 이를 모두 적용해서 RNN 계층 내 역전파를 수행해주게 되면 아래의 그림처럼 된다.

위 자료는 책에는 없지만 필자가 그동안 배운 내용을 기반으로 직접 역전파 계산 과정을 재현해보았다. 저자 소스코드로도 확인해보니 일치하는 것으로 보아 아마 위 그림은 명확한 RNN 계층 내 역전파 구현 과정이 맞다.
위 2가지 방법을 기반으로 RNN 계층을 넘파이로 구현한 코드는 여기를 들어가서 볼 수 있다. 그런데 책에서는 만약 $T$ 길이의 시계열 시퀀스가 존재할 때, 이를 한 번에 구현하는 TimeRNN 계층을 구현한다. 즉, RNN 클래스라는 단일 RNN 계층을 만들고 이것을 $T$개로 확장해 사용한다. 소스코드가 궁금한 분은 그 점을 참고해서 보면 좋겠다. 또 추가적으로 시계열에 맞는 TimeEmbedding 계층, TimeAffine 계층 클래스도 있다. 그리고 해당 코드는 RNN 역전파를 수행 시 Truncated BPTT로 구현한 코드이다. 이에 대해 완전한 내용을 포스팅에서 못담는게 아쉽긴 하다.. 궁금하신 분은 꼭 책으로 공부해길 권해본다!
5. 언어모델의 평가 척도, Perplexity
지금까지 조건부 언어 모델 이론 + RNN 신경망 구조를 활용해서 RNN을 활용한 언어모델에 대해 배워보았다. 조건부 언어 모델 이론이란 우리가 위에서 1번 목차에서 동시확률을 사후확률의 총곱으로 나타낼 수 있다는 것을 기반으로 배웠던 내용이다. 그런데 이렇게 생성한 언어 모델의 성능을 평가하는 지표는 무엇일까?
성능을 평가하는 대표적인 지표로 Perplexity(퍼플렉서티)가 등장한다. 퍼플렉시티는 언어모델이 다음 단어를 얼마나 잘 예측하는지 정확도를 평가하는 지표이다. 퍼플렉서티는 '확률의 역수'를 의미하는데, 이게 아직 정확히 무슨 말인지 감이 오지 않을 것이다.

위 그림에서 모델 1,2가 존재한다. 그리고 각 모델은 'you'라는 단어를 입력받고 다음에 나올 단어를 각각 확률분포로 예측했다. 모델 1은 다음에 'say'라는 단어가 80%(0.8)의 확률로 등장한다고 예상했고, 모델 2는 'say'라는 단어가 20%(0.2)의 확률로 예측했다. 그렇다면 모델 1의 퍼플렉시티는 확률값인 0.8의 역수인 1.25가 된다. 모델 2의 퍼플렉시티는 0.2의 역수인 5가 된다.
이 때, 퍼플렉시티는 결론부터 말하면 작을수록 좋다. 왜냐하면 퍼플렉시티는 '분기 수(Number of branches)'로 해석할 수 있다. 여기서 분기 수란, 다음에 취할 수 있는 선택사항의 수를 의미한다. 우리는 지금 다음에 나올 단어를 예측하는 언어 모델에 대해 이야기하고 있으니 이에 대해 빗대어 표현하면, 언어 모델이 'you'라는 단어를 입력으로 받았을 때, 다음에 나올 단어의 후보 개수를 의미하게 된다.
그러면 위 예시에서 모델 1의 퍼플렉시티가 1.25였다. 그말은 즉슨 'you'라는 단어를 입력시켰을 때, 다음에 나올 단어의 후보 개수를 1.25개 정도로 추렸다는 것이다. 반면에 모델 2의 퍼플렉시티는 5였다. 그말은 결국 ''you' 단어를 입력시켰을 때, 다음에 나올 단어의 후보 개수가 5개나 된다는 것이다. 결국 모델 2보다는 모델 1이 좀 더 정확한 예측 언어 모델이라고 할 수 있을 것이다.
그러면 퍼플렉서티의 구체적인 계산 공식을 살펴보자. 아래 공식은 입력 데이터가 여러개일 때의 공식이다.
$$L = -\frac{1}{N} \sum_{n} \sum_{k} t_{nk} logy_{nk}$$
$$perplexity = e^L$$
위 수식에서 $N$은 입력된 데이터의 개수이고 $t_{nk}$는 $N$개 중 $n$번째 데이터의 $k$번째 정답 레이블 값을 의미한다. 여기서 $k$번째 값이란, 정답 벡터의 원소들 중 $k$번째 원소일 것이다.(정답이므로 해당 벡터는 모두 원-핫 인코딩 상태일 것이며 벡터의 원소값들은 0 또는 1 둘 중에 하나일 것이다)
반면에, $y_{nk}$는 $N$개 중 $n$번째 데이터의 $k$번째 예측 값을 의미한다. 여기에서는 출력 값으로 나온 벡터일 것이며 원소값들은 Softmax를 취해준 값일 것이다.(0과 1사이의 실수값)
그런데 위 $L$ 수식을 어디서 많이 봤지 않은가? 바로 크로스 엔트로피 손실 함수(CEE)와 동일하다! 즉, $N$개의 데이터에 대한 CEE 값을 자연상수($e$)의 지수에 넣어주어 변환시켜준다. 어쨌거나 핵심은 퍼플렉서티는 '언어 모델의 정확도 성능'을 측정하는 지표이며 퍼플렉서티의 값은 '다음에 나올 단어의 후보 개수'를 의미하며 이 값이 작을수록(아마 1이 최소이지 않을까..!?) 언어모델의 성능이 정확함을 의미한다.
이번시간까지 배워본 RNN 순환 신경망은 은닉 상태 벡터(hidden_state)라는 것을 기반으로 과거의 상태를 현재, 미래에서도 기억하도록 학습시키는 모델이었다. 이론적으로는 이렇지만 막상 실제 세계의 데이터를 활용해서 학습시킬 때는 RNN 신경망이 잘 학습하지 못하는 경우가 빈번하다고 한다. 다음 챕터에서는 이러한 RNN 신경망의 문제점이 무엇인지 알아보고 이를 대체하는 게이트가 추가된 RNN인 LSTM, GRU에 대해 알아보도록 하자!
지금까지 RNN 순환 신경망에 대해 알아보았다. 길고도 긴 여정이었다. 점점 내용이 심화되면서 적을 내용도 많아지고 직접 넘파이 코드를 하나씩 따라치면서 구현하면서 배운 점을 여기에 모두 담지 못해서 아쉽다. 가장 좋은 점을 물론 책을 구입해서 직접 내용을 체득하는 것 같다. 강!추!
'Data Science > 밑바닥부터시작하는딥러닝(2)' 카테고리의 다른 글
| [밑시딥] 게이트를 추가한 GRU와 RNN LM 성능 개선 방법 (0) | 2021.12.21 |
|---|---|
| [밑시딥] 게이트가 추가된 RNN, LSTM(Long-Short Term Memory) (2) | 2021.12.16 |
| [밑시딥] Embedding 계층과 Negative Sampling으로 효율적인 word2vec 구현하기 (2) | 2021.12.03 |
| [밑시딥] 단어의 분산을 표현하는 또 다른 기법, word2vec (2) | 2021.11.30 |
| [밑시딥] 오직! Numpy로 단어의 분산 표현하기 (0) | 2021.11.26 |



