🔊 해당 포스팅은 밑바닥부터 시작하는 딥러닝 2권의 교재 내용을 기반으로 자연어처리 딥러닝 신경망을 Tensorflow, Pytorch와 같은 딥러닝 프레임워크를 사용하지 않고 순수한 Numpy로 구현하면서 자연어 처리의 기초를 탄탄히 하고자 하는 목적 하에 게시되는 포스팅입니다. 내용은 주로 필자가 중요하다고 생각되는 내용 위주로 작성되었음을 알려드립니다.

지난 포스팅에서는 word2vec를 구현하기 위한 신경망 모델로 CBOW 모델과 Skip-gram 모델에 대해 알아보았다. 그리고 간단하게 한 문장의 말뭉치를 활용해서 신경망 모델을 학습시키고 학습된 신경망의 입력층 파라미터 즉, 우리가 구하고자 하는 단어의 분산 표현을 얻어보기도 했다.(이것이 word2vec를 구현한 셈!) 그런데 아직 개선할 문제점들이 있다. 저번에 구현해보았던 방식은 말뭉치 데이터가 커지게 됨에 따라 계산량이 기하급수적으로 증가하고 CBOW 같은 신경망 모델을 학습시키는 데 너무 오래걸리게 된다.
이러한 문제를 해결하기 위해서 이번 포스팅에서는 2가지 해결책에 대해 다룬다. 첫 번째는 Embedding 계층을 만드는 것. 두 번째는 네거티브 샘플링이라는 새로운 손실함수를 신경망에 도입하는 것이다.
1. 기존 방법에서 어디 부분을 개선해야 할까?
개선하는 방법들에 대해 본격적으로 다루어보기 전에 지난 포스팅에서 구현했던 CBOW 신경망 모델을 잠시 다시 살펴보자. 단, 이번에는 Vocabulary size가 적은 수가 아니고 100만개라고 가정했을 때의 그림이다.
직관적으로 W 라는 파라미터 값의 행렬 형상이 매우 커졌다. 그 말은 즉슨 계산해야 하는 연산량이 엄청나게 증가했음을 의미한다. 만일 위와 같이 100만개의 Vocabulary size가 주어진다면 행렬 곱을 연산하는 기존 CBOW 모델은 파라미터 계산만 하는데도 엄청난 시간이 소비된다. 따라서 위의 상황일 때, 컴퓨팅 계산의 병목현상이 일어나는 부분을 표시하면 아래와 같다.
위 그림처럼 2가지 부분에서 병목현상이 발생한다. 1번 부분에 대한 해결책으로는 Embedding 계층을 활용할 수 있으며, 2번 부분에 대한 해결책으로는 Negative Sampling 이라는 새로운 손실함수를 신경망에 도입하는 것으로 해결할 수 있다. 이제 해결책에 대해 하나씩 살펴보자!
2. Embedding 계층
임베딩 계층은 맥락 입력 데이터와 은닉층 사이의 파라미터를 계산할 때 활용하는 계층이다.(위 그림에서 1번 그림처럼) 임베딩 계층에 알아보기에 앞서 기존에 맥락 입력 데이터와 은닉층 사이의 파라미터 계산을 어떻게 했는지 다시 상기시켜보자. 아래의 그림처럼 맥락 입력 데이터를 원-핫 인코딩 형태로 변경 후 파라미터와 행렬 곱을 수행했다.
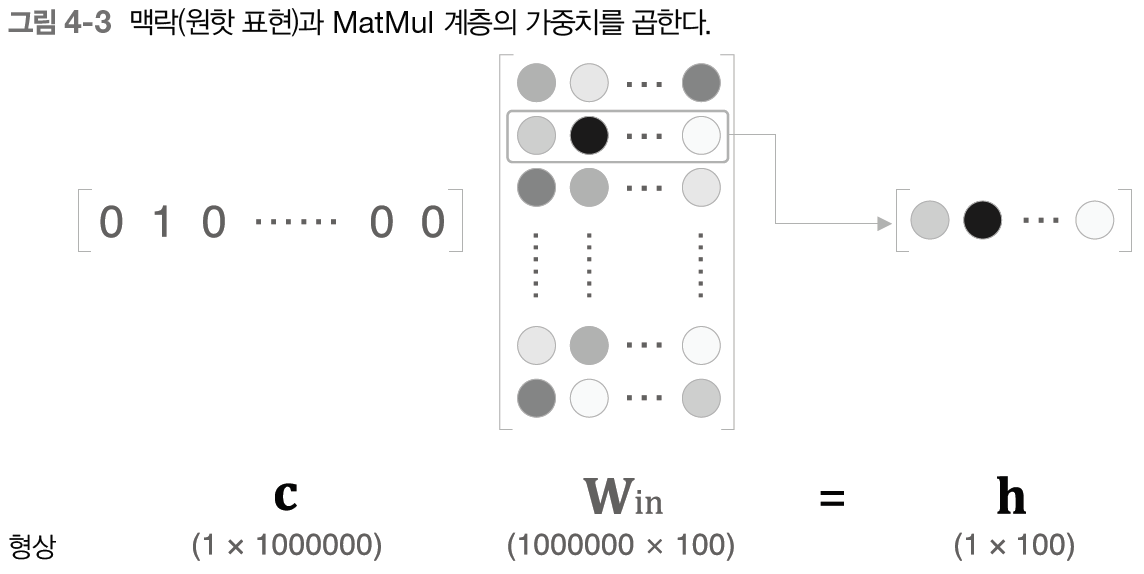
그런데, 위 그림을 잘 살펴보면 h로 나오는 결과값은 Win 파라미터의 1번째 행의 값이 그대로 나오게 된다. 왜냐하면 원-핫 인코딩 형태로 되어 있는 C에서 하나의 값만 1이고 나머지는 모두 0이기 때문에다. 따라서 C에서 값이 1인 인덱스를 행으로 하는 Win의 값이 그대로 h로 나오게 된다.
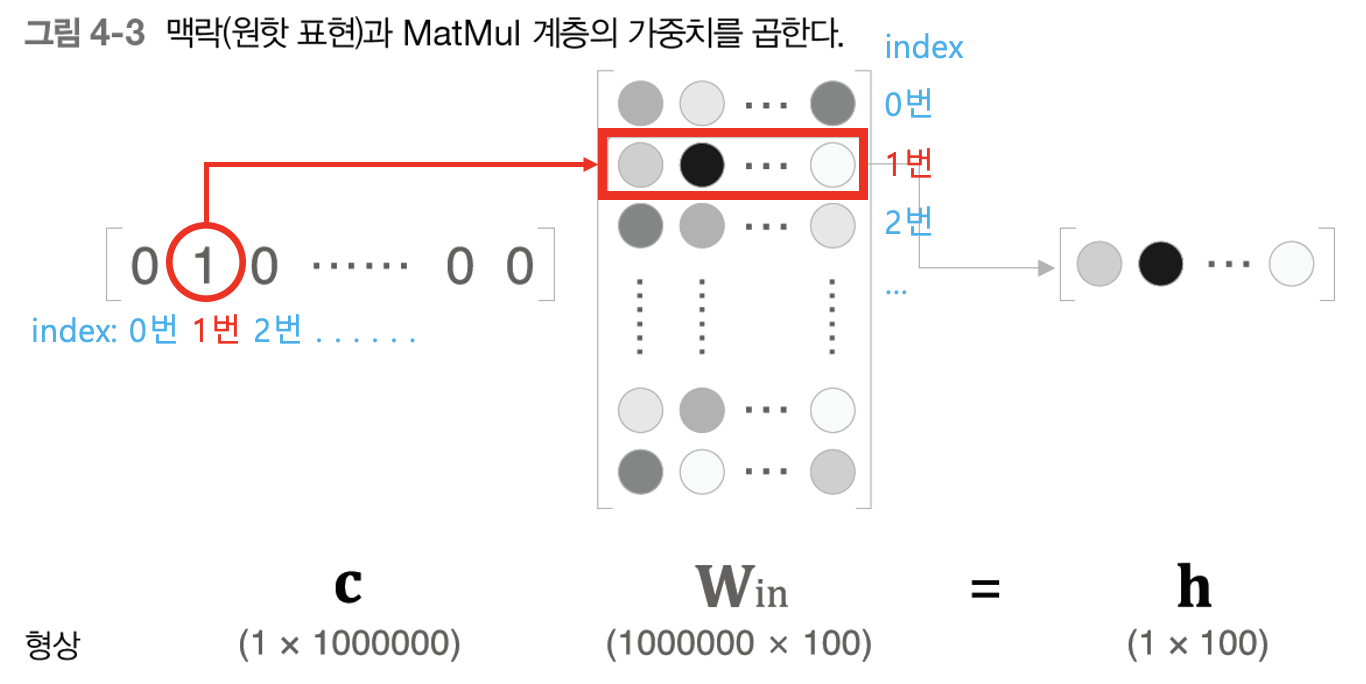
그렇기 때문에 인덱스 번호만 잘 맞춰서 매핑시켜주면 h 값을 계산하기 위해 굳이 (100만개, 100개)나 되는 Win 행렬과 연산을 할 필요가 없어지게 된다. 이러한 원리를 이용해 인덱스를 잘 매핑시켜 엄청난 행렬 연산을 하지 않아도 되도록 하는 것이 바로 임베딩 계층의 핵심이며 이것을 이해하면 임베딩 계층은 모두 이해한 것이다!
그러면 임베딩 계층을 간단하게 넘파이로 구현해보자. 우선 넘파이에는 임베딩 계층을 매우 수월하게 할 수 있다. 예를 들어, 아래와 같은 행렬이 있다고 가정하자.
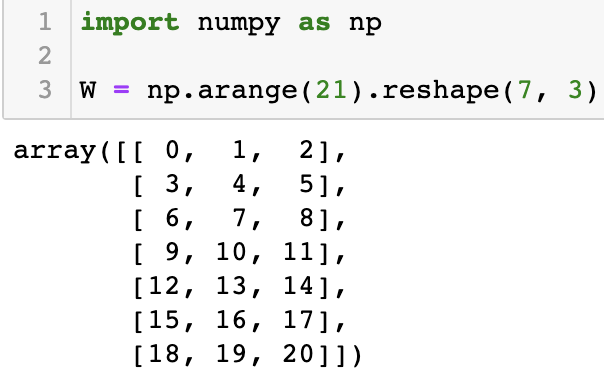
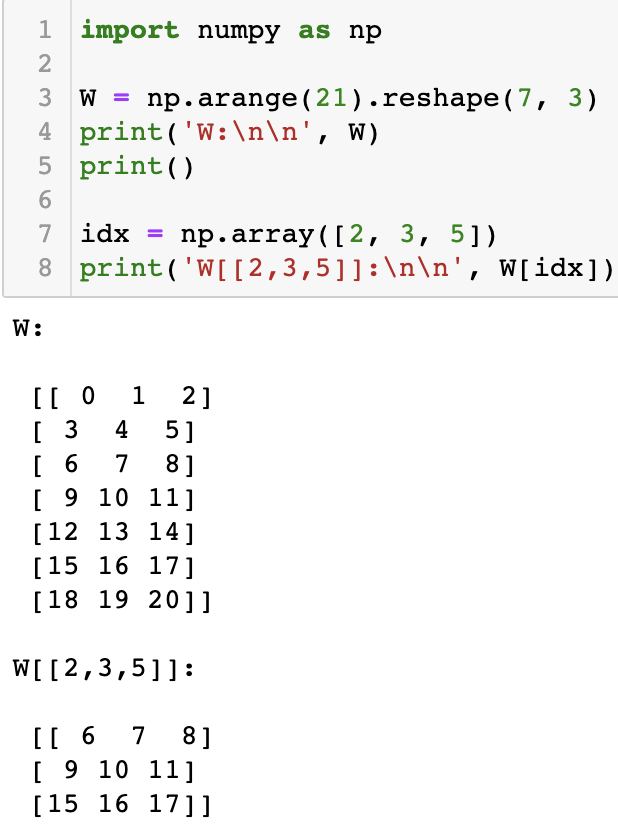
위 행렬 W에서 3번째 행의 배열을 갖고오고 싶다면 간단하게 넘파이에 인덱싱만 취해주면 된다. W[3] 처럼 말이다. 그렇다면 2번, 3번, 5번 행 3개를 동시에 갖고오고 싶다면 어떻게 할까? 넘파이 인덱싱에 추출하고 싶은 행들을 원소로 하는 배열을 넣어주면 된다. 아래처럼 말이다.
위와 같은 원리를 활용해서 넘파이로 임베딩 계층 클래스를 구현하는 소스코드이다.
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
다음은 임베딩 계층의 역전파를 구현해야 한다. 역전파는 어떻게 구현할까? 우선 임베딩 계층의 순전파를 다시 생각해보자. 임베딩 계층 순전파 시에는 행렬에 어떠한 연산을 하나도 가하지 않고 단순히 특정 행의 값만을 추출해내 그대로 흘려보냈다. 따라서 역전파일 때도 그대로 흘려보내면 된다.(왜 그대로 흘려보내야 되는지에 대해 잘 모른다면 예전 포스팅의 '1-1. 분기 노드' 목차를 참고하자) 그래서 역전파 함수를 구현하면 아래와 같다.(아래 소스코드는 위 코드랑 이어지는 코드이다)
def backward(self, dout):
dW, = self.grads
dW[...] = 0
dW[self.idx] = dout
return None
그런데 위 역전파 함수에서 추가적으로 해주어야 할 것이 있다. 위 소스코드 그대로 구현하게 되면 self.idx(위 소스코드의 변수인 self.idx를 의미) 값에 중복된 값이 존재하면 문제가 발생하게 된다.
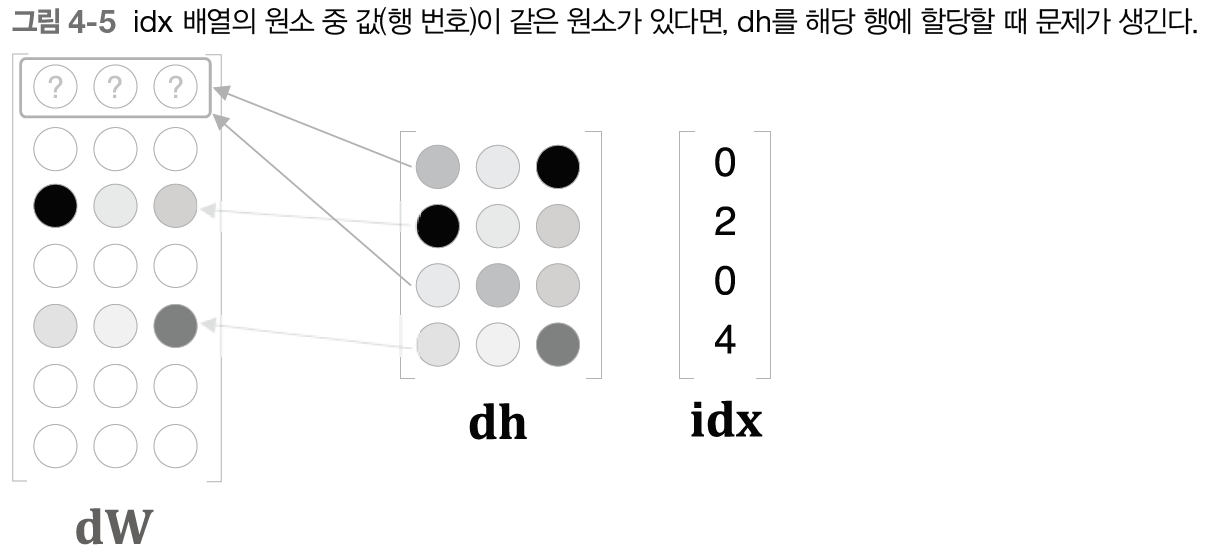
위 그림처럼 idx 값이 [0, 2, 0, 4] 가 있다. 여기서 idx 값은 임베딩 계층의 순전파 수행 시 추출한 특정 행의 인덱스이다.(더 세부적으로 말하면 Vocabulary의 고유한 단어 ID가 된다) 위와 같은 상황일 때, 역전파를 수행하게 되면 0번의 인덱스 값이 두번 전달되게 된다. 따라서 문제가 발생한다. 이 중복 문제를 해결하기 위해서는 중복되는 값들을 모두 더해주어야 한다. 아래처럼 말이다.
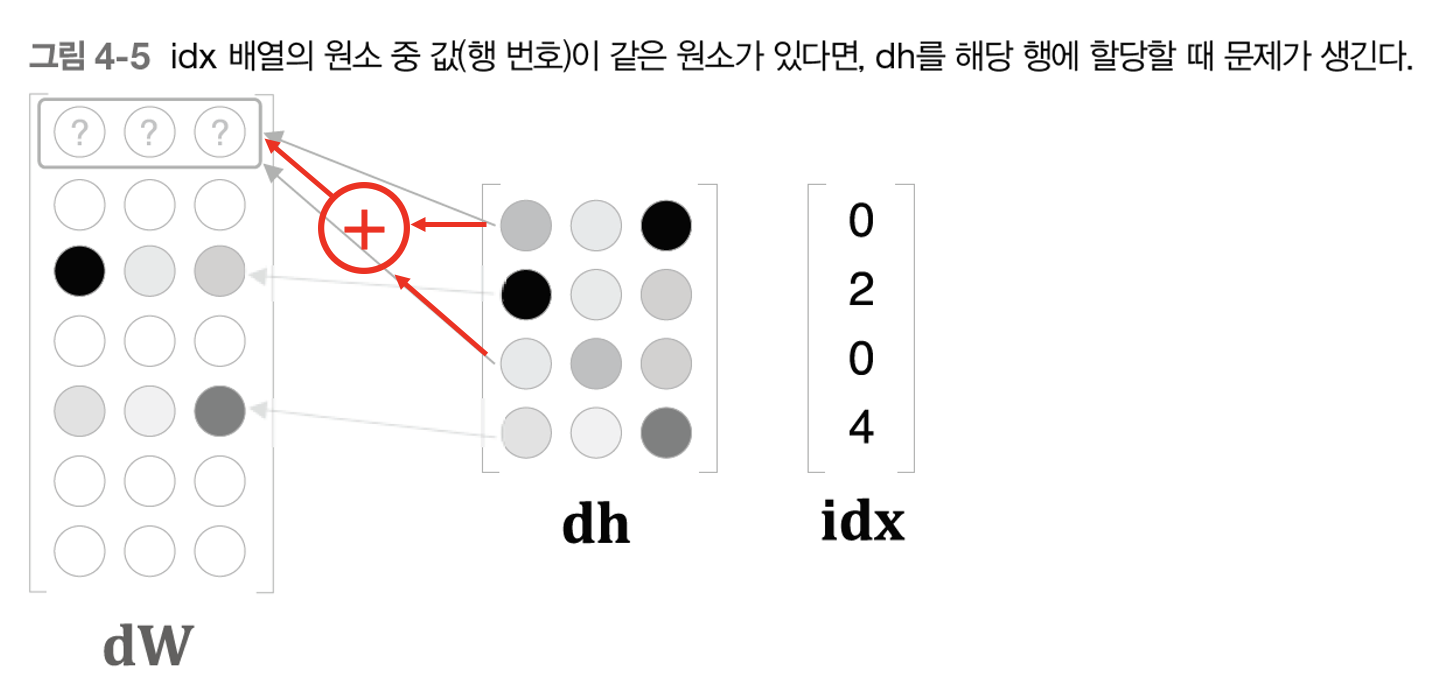
그런데 위와 같이 더해야 하는 이유는 무엇일까? 이는 예전 포스팅에서 알아보았던 Repeat(복제) 노드의 순전파, 역전파 과정을 적용하기 때문이다. Repeat(복제) 노드의 순전파, 역전파 과정에 대한 자세한 내용은 여기를 참고하고, 여기서는 Repeat 노드의 순전파, 역전파 도식화 그림만 보고 넘어가자.
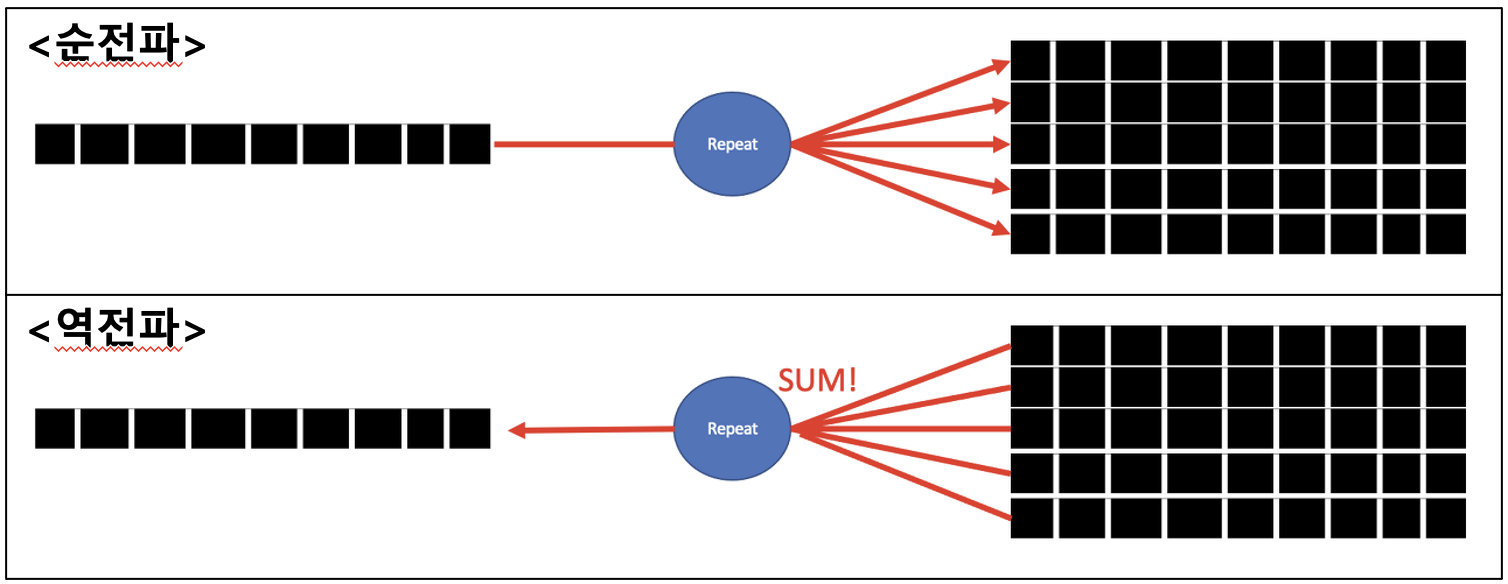
따라서 위 Repeat 노드 역전파 원리를 활용해 임베딩 계층의 역전파 함수를 개선한 최종 코드는 아래와 같다.
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
# 일반 for loop로 구현
#for i, word_id in enumerate(self.idx):
#dW[word_id] += dout[i]
# dout에 지정된 self.idx(word_id)에 대응하는 dW 행렬의 인덱스 값에 각각 더해줌
np.add.at(dW, self.idx, dout)
return None
위 소스코드에서 Repeat 노드 역전파를 구현할 때 일반 for loop와 넘파이의 add 함수를 사용한 두 가지 방법이 있다. 당연히 행렬 개수가 많아질수록 넘파이를 활용해 구현하는 것이 연산이 효율적이다. 넘파이의 add 함수에 대한 설명은 여기에서 잘 해놓았으니 모른다면 참고하자.
3. 다중분류(Softmax)에서 이진분류(Sigmoid)로 바꾸자, 그리고 Negative Sampling!
지금까지 임베딩 계층을 활용해서 아래 병목현상 두 부분 중 1번에 해당하는 부분을 해결했다. 이제 2번에 대한 해결방법에 대해 알아보자.
2번 병목현상도 1번 때와 마찬가지로 Wout 행렬의 형상이 급격히 커짐에 따라 계산 병목현상이 발생하게 된다. 그리고 Softmax 함수를 사용하는 것도 계산 병목현상을 일으킨다. 왜일까? Softmax 함수의 수식을 살펴보면 그 이유를 알 수 있다. 아래의 수식은 위 그림처럼 Vocabulary size가 100만개일 때의 Softmax 수식이다.
yk=exp(sk)∑1000000i=1exp(si)
위 수식에서 si는 출력층의 노드 하나 값을 의미한다. Softmax 함수는 예전 포스팅에서도 언급했지만 포인트 중 하나가 바로 분모에 있다고 했다. 분모를 살펴보면 모든 si값들에 모두 exp 연산을 취한 후 계산하게 된다. 즉, 여기서는 1개의 출력값에 대한 Softmax 식을 계산하려면 매번 100만개의 si값들을 모두 계산하게 된다. 이런 특성 때문에 Vocabulary size가 커짐에 따라 Softmax 계층에서도 연산의 병목현상이 발생하게 된다.
3-1. 다중분류에서 이진분류로!
이를 해결하기 위해 활성함수를 Softmax에서 Sigmoid 함수로 교체해버린다. 활성함수를 Softmax에서 Sigmoid로 변경한다는 말은 곧 다중분류 문제에서 이진분류 문제로 바꾸어버린다는 의미이다. 이게 어떻게 가능한걸까?
지금까지 우리는 계속 다중분류 문제를 해결해왔다. 예를 들어, CBOW 모델로 가정한다면, 'you' 와 'goodbye' 라는 2개의 맥락 단어가 입력으로 주어졌을 때, 가운데에 나올 단어가 무엇인가? 라는 다중분류 문제를 해결해왔다. 그런데 이를 약간의 관점을 변형하여 이진분류 문제로 바꿀 수 있다. 방금 예시를 든 경우로 하자면, 'you' 와 'goodbye' 라는 2개의 맥락 단어가 입력으로 주어졌을 때, 가운데에 나올 단어는 'say'인가? 아닌가? 로 바꿀 수 있게 된다.
다중 분류 : " 'you' 와 'goodbye' 라는 2개의 맥락 단어가 입력으로 주어졌을 때, 가운데에 나올 단어가 무엇인가? "
이진 분류 : " 'you' 와 'goodbye' 라는 2개의 맥락 단어가 입력으로 주어졌을 때, 가운데에 나올 단어는 'say'인가? 아닌가? "
위처럼 다중분류 문제를 이진분류로 만들어서 2번 병목현상을 해결할 수 있다. 그리고 이렇게 다중분류에서 이진분류로 변환하는 과정에서 바로 Negative Sampling(네거티브 샘플링)이라는 기법이 활용된다.
네거티브 샘플링을 알아보기 이전에 CBOW 모델이 만약 다중분류에서 이진분류 문제로 바뀌게 된다면 신경망의 구조는 어떻게 바뀔까?
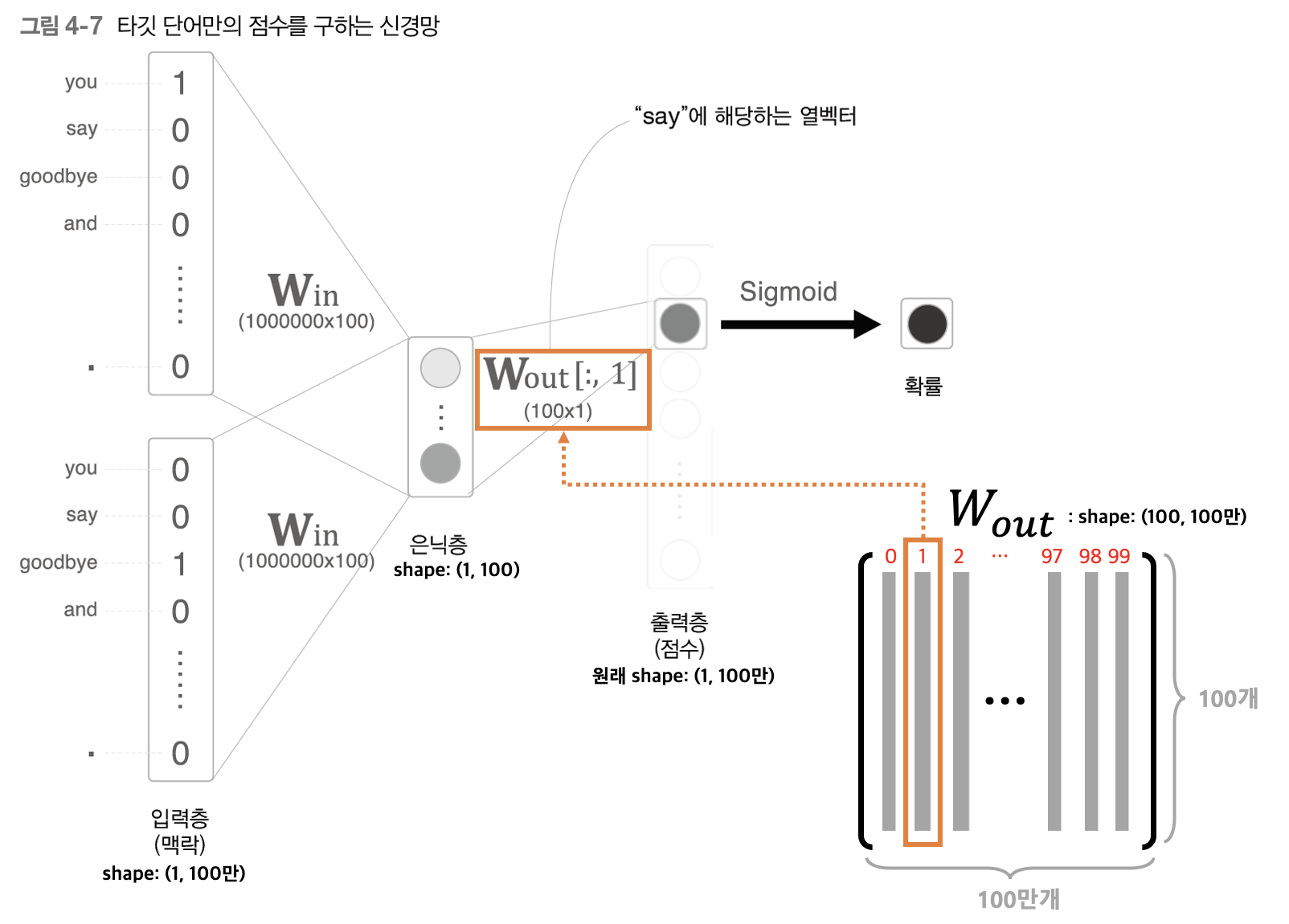
위 그림을 보면 크게 달라진 점이 2가지가 있다. 우선 은닉층에서 출력층으로 가는 파라미터인 Wout의 전체를 이용하지 않고 일부만 이용하는 것이다. 이 때, 여기서는 예시를 'say' 라는 단어로 지정했다. 'say'라는 단어가 단어 ID이자 입력층의 단어 벡터로 치자면 인덱스가 1에 있는 단어이다. 따라서 현재 상황이 'you'와 'goodbye'라는 맥락 데이터 2개가 들어갔을 때, 가운데에 올 단어는 'say'이냐 아니냐? 라는 이진분류로 바뀐 것이다.
따라서 은닉층과 'say'라는 단어 벡터가 들어가 있는 Wout 행렬에서 1번째 열 벡터만 내적하여 계산한다. 그렇게 되면 출력층에는 하나의 노드만 갖게 되며 이를 Sigmoid 활성함수를 적용하여 0~1 사이의 일종의 확률 값으로 변환시켜 준다. 그래서 만약 Sigmoid를 취했을 때 값이 0.99가 나왔다고 한다면 그 의미는 'you'와 'goodbye' 라는 맥락 데이터가 주어졌을 때, 가운데에 나올 단어는 99% 확률로 'say'라는 단어가 올 것이라는 의미이다. 반대로 만약 Sigmoid를 취한 값이 0.01 같은 값으로 매우 낮다면 가운데에 나올 단어는 'say' 라는 단어가 절대 아닐 것이라는 것을 의미한다.
다중 분류에서 이진 분류로 변환하는 과정을 잠시 정리해보자면 다음과 같다. 먼저 주어진 맥락 데이터가 입력되었을 때, 나올 단어를 미리 하나 점 찍어(?) 놓는다(이 과정에서 추후에 Negative Sampling이 관여한다). 위 예시에는 'say'를 점 찍어 놓은 셈이다. 그리고 은닉층과 Wout 행렬에서 미리 점 찍어 놓은 단어 벡터랑만 행렬 내적을 수행한다. 그리고 Sigmoid 활성함수를 적용한 후, 미리 점 찍어 놓은 단어가 정답인지 아닌지 이진 분류하는 문제로 학습하게 된다.
3-2. 이진분류의 손실함수와 오차역전파
3-1 목차에서 다중분류에서 이진분류 문제로 바꾸는 방법을 알아보았다. 그러면 문제 유형이 바뀌었으니 그 문제에 맞는 손실함수도 바꾸어주어야 한다. 이진분류에서도 다중분류에서와 마찬가지로 크로스 엔트로피 오차(CEE)를 손실함수로 사용한다. 수식이 변경된 것 같지만 단지 클래스가 여러개에서 단 두개(정답이냐 아니냐)로 줄어든 것 밖에 없다. 이진분류일 때의 CEE 함수 수식은 아래와 같다.
L=−(tlogy+(1−t)log(1−y))
위 수식에서 t는 정답을, y는 모델이 내뱉은 예측값을 의미한다. 다중분류 때와 마찬가지로 정답 즉, t=1일 경우에만 실질적으로 손실함수를 계산하게 된다.
손실함수가 바뀌었으니 이제 바뀐 손실함수로 오차역전파를 다시 구현해야 한다. 하지만 Sigmoid의 역전파 과정, CEE의 역전파 과정은 예전 포스팅에서 계산 그래프를 활용해가면서 구체적으로 배웠었다. 각 계층 별로 오차역전파가 진행되는 과정은 예전 포스팅을 참고하도록 하자. 여기에서는 Softmax-with-Loss 계층처럼 Sigmoid도 CEE 계층과 합쳐 Sigmoid-with-Loss 계층의 역전파 과정을 간략하게만 알아보도록 하자.
Sigmoid-with-Loss 계층의 역전파 과정을 도식화하면 아래와 같다.
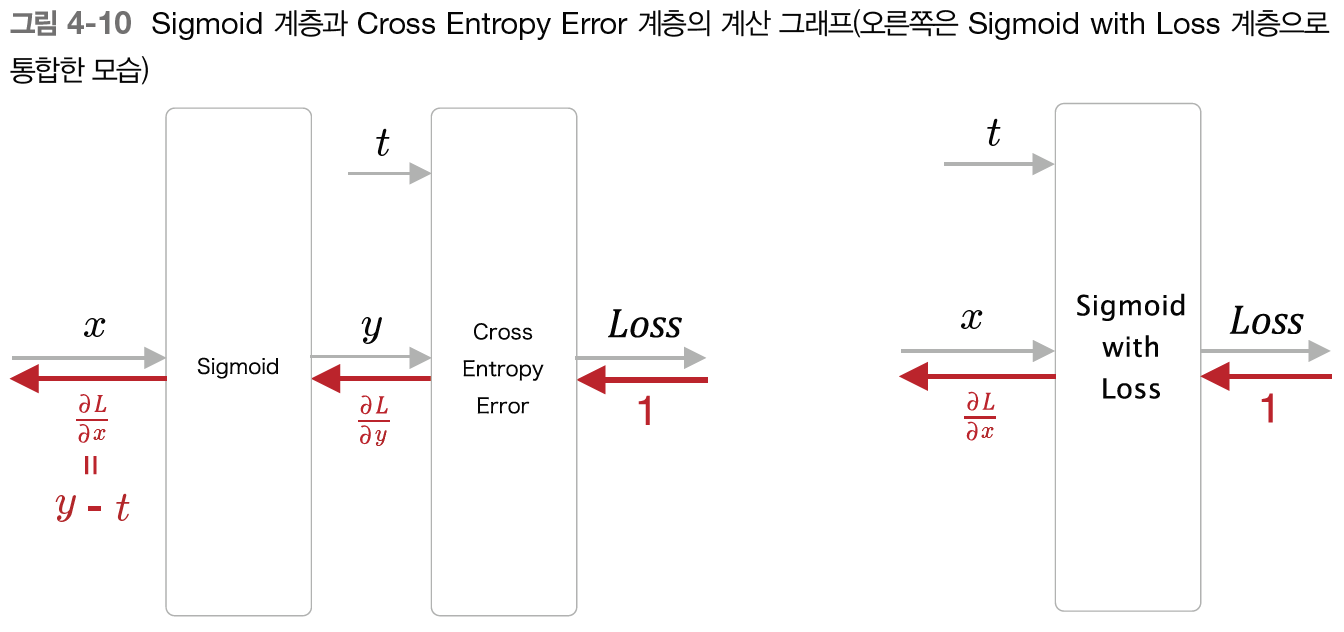
우선 Sigmoid-with-Loss 계층의 오차역전파 후 최종 미분 값인 ∂L∂x는 y−t가 된다. 어떻게 이러한 값이 나오게 되었는지 하나씩 살펴보자. 먼저 ∂L∂x을 구하기 위해서는 Chain Rule을 활용해 아래의 값들을 구하면 된다.
∂L∂x=∂L∂y∂y∂x
우선 ∂L∂y 값부터 구해보자. 해당 값은 CEE 계층을 거쳐 나온 값이다. 예전 포스팅에서 Softmax-with-Loss 계층을 배워보면서 다중분류 일 때, CEE 계층을 거쳐나온 국소적인 미분 값들은 −t1y1,−t2y2,−t3y3,...−tkyk 라는 것을 알았다.(이 때, k는 클래스의 개수를 의미) 그런데 여기서는 이진 분류이기 때문에 CEE 계층을 거쳐나온 국소적인 미분 값들은 −ty,1−t1−y가 된다. 그리고 순전파 시 이진분류이기 때문에 두 갈래로 갈라져 나갔던 분기 노드를 다시 역전파하면서 합쳐야 하기 때문에 두 값 −ty,1−t1−y을 더해준다. 그렇게 해서 ∂L∂y은 아래와 같이 정의된다.
∂L∂y=−ty+1−t1−y=y−ty(1−y)
이제 다음은 ∂y∂x 을 구할 차례이다. 이 값은 Sigmoid 계층을 거쳐서 나오는 역전파이다. 이 또한 예전 포스팅에서 Sigmoid 계층의 역전파 시 y(1−y)가 된다는 것을 배웠었다. 이를 활용하게 되면 ∂y∂x 값은 아래와 같이 정의된다.
∂y∂x=y(1−y)
최종적으로 구하고자 하는 Sigmoid-with-Loss 계층의 최종적인 미분 값은 두 개의 값을 곱하여 아래처럼 된다.
∂L∂x=y−ty(1−y)y(1−y)=y−t
3-3. 1번, 2번 병목현상 해결 방법을 적용한 후의 신경망 구조
지금까지 기존의 신경망 모델(여기서는 CBOW를 예시로 사용)의 계산 병목현상을 어떻게 해결하는지에 대해 알아보았다. 그렇다면 이 2가지 해결 방법을 적용한 후의 신경망 구조를 살펴보자. 우선 하단의 그림은 1번째 병목현상을 해결하는 Embedding 계층만 적용했을 때의 다중분류 CBOW 모델 구조이다.
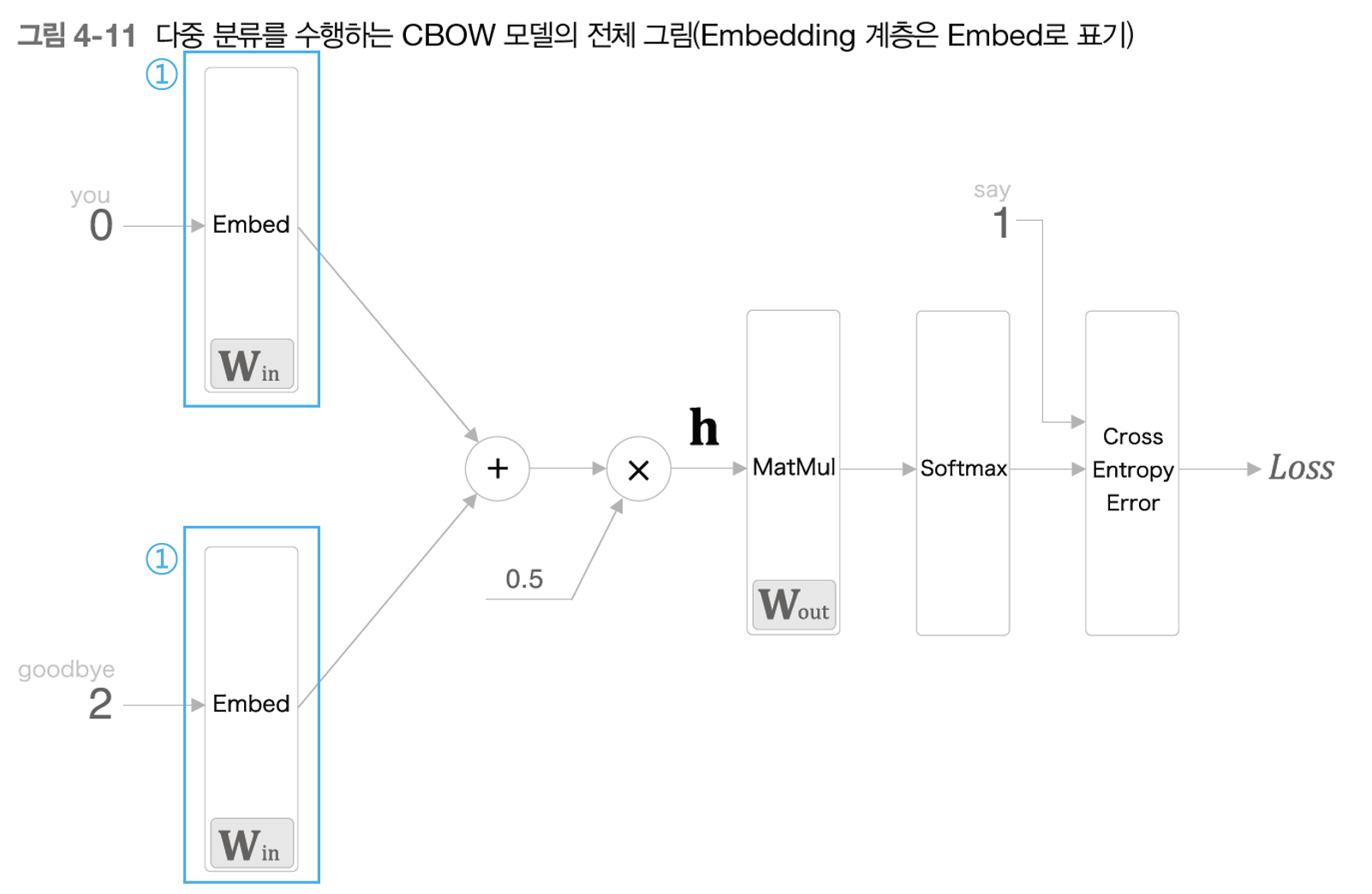
위 그림에서 맥락 데이터는 'you' 와 'goodbye' 단어 2개가 입력되고 있다. 그리고 Softmax 함수를 적용해서 현재 다중분류 문제를 해결하고 있다. 이제 Sigmoid 함수를 사용해서 이진분류로 만든 후의 신경망 구조를 살펴보자. 이 때 미리 점 찍어(?)놓는 정답일 것 같은 단어는 'say' 이고 진짜 정답 레이블도 'say' 라고 가정했다.
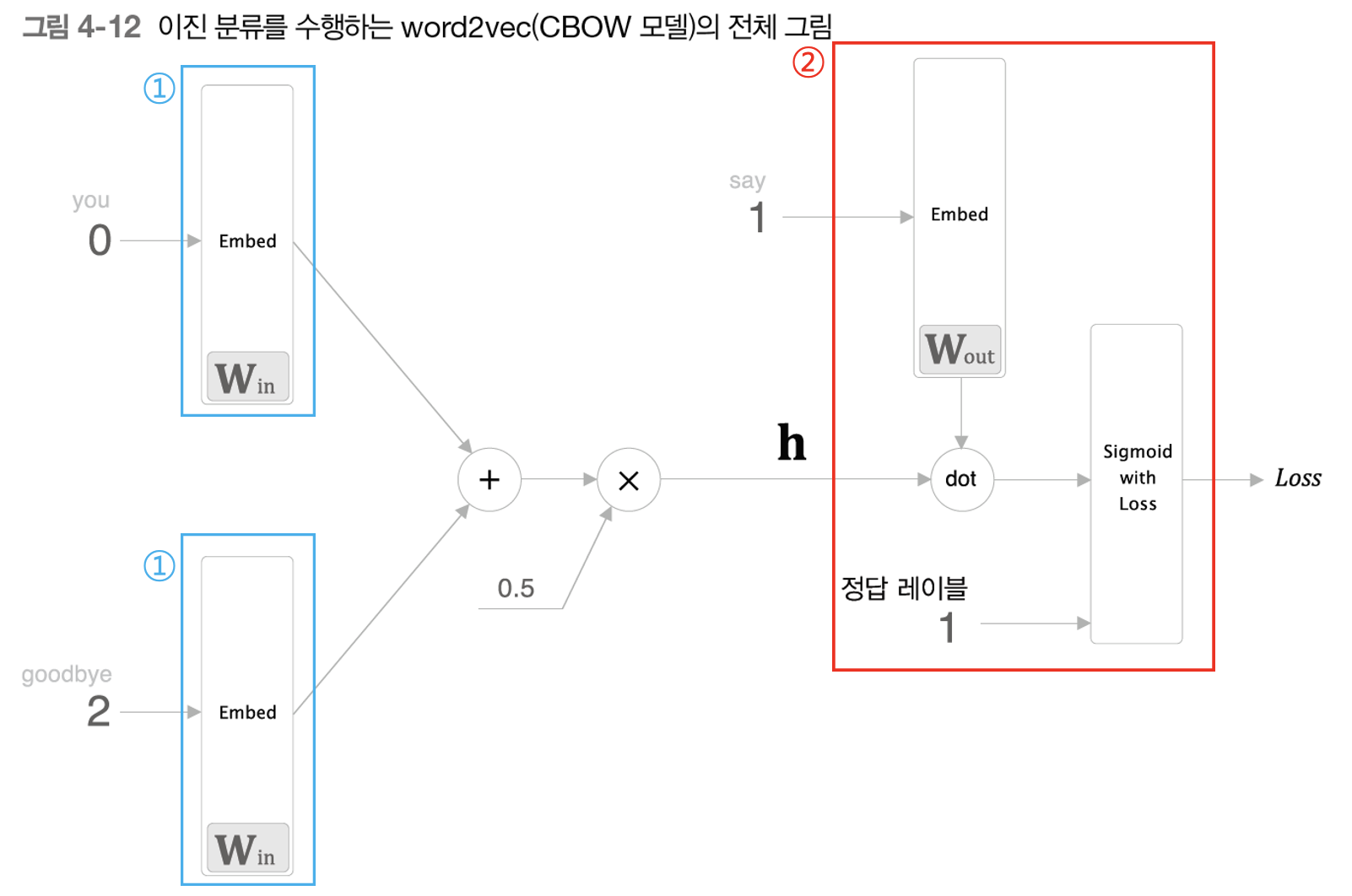
위 그림을 보면 2번 빨간색 네모칸에서 살짝 특이한 부분을 볼 수 있다. 바로 2번에도 1번과 마찬가지로 임베딩 계층이 들어간 것이다! 여기서 잠시 임베딩 계층이 하는 기능을 다시 상기시켜보자. 임베딩 계층은 특정 행의 벡터만 추출하는 기능을 했다. 그런데 2번 병목현상에서도 우리는 특정 행의 벡터를 추출해야 한다. 왜냐하면 사전에 점 찍어 놓은 단어인 'say'가 정답인지 아닌지 이진분류하는 문제로 바꾸었기 때문에 우리는 'say'라는 단어의 벡터만 은닉층의 노드와 계산하면 되기 때문이라고 위에서 배웠기 때문이다. 따라서 임베딩 계층을 2번에도 적용한 후 임베딩 계층이 추출한 특정 행 벡터(여기서는 'say' 벡터일 것임)와 은닉층의 노드인 h와 내적(dot)을 수행만 하면 되는 것이다!
위 그림의 빨간색 2번 네모칸을 좀 더 확대해서 살펴보면 아래의 그림과 같이 'Embedding Dot' 이라는 하나의 계층으로 만들 수 있다.
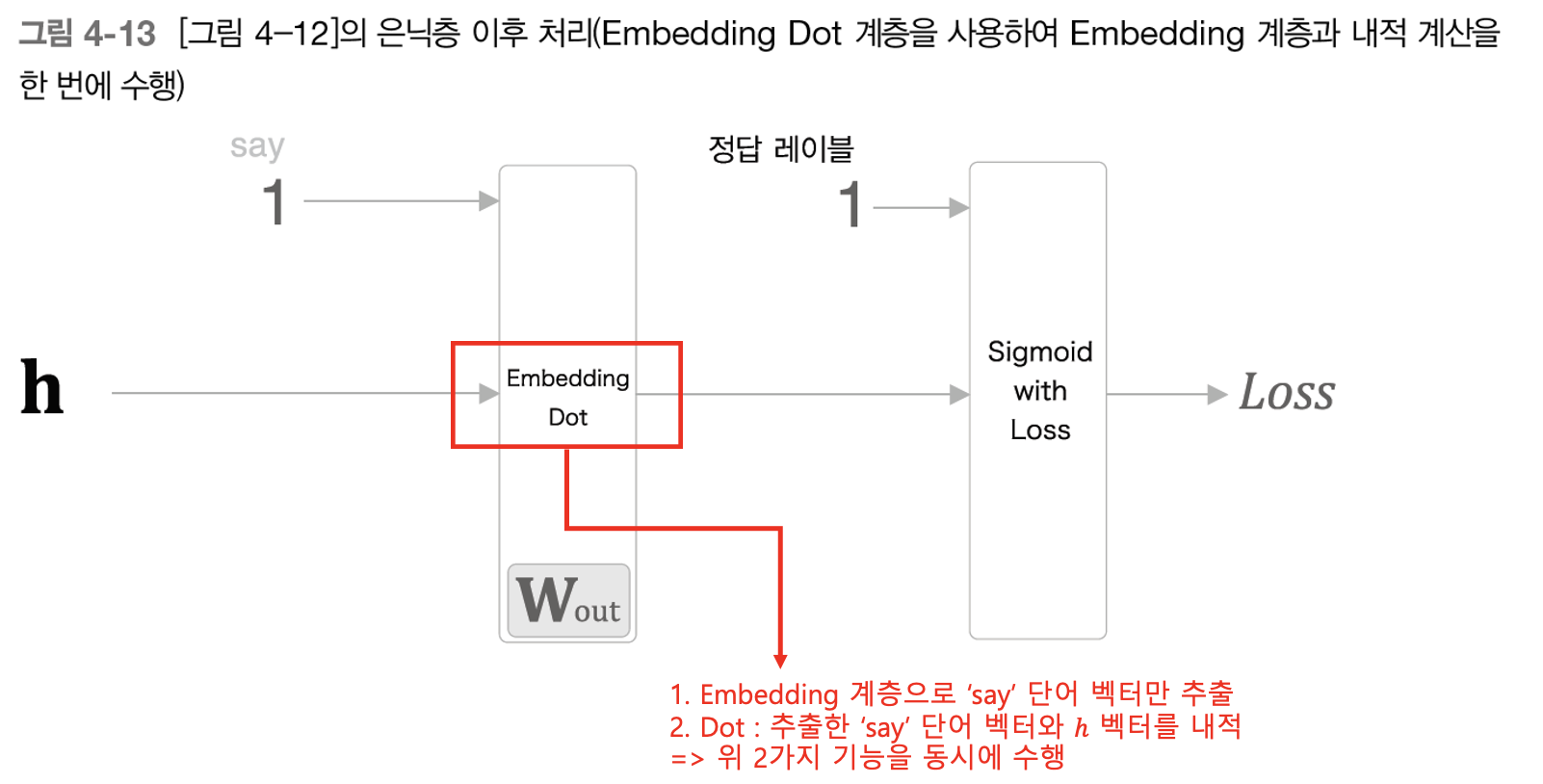
위처럼 Embedding Dot 이라는 계층을 굳이 만드는 이유는 넘파이로 구현할 때 이렇게 구현할 것이기 때문이다. 위의 Embedding Dot 계층을 넘파이로 구현하면 아래 소스코드와 같다. 참고로 Embedding Dot 계층을 구현하기 위해서는 Sigmoid-with-Loss 계층을 먼저 구현하는 과정이 선행되어야 한다. Sigmoid-with-Loss 계층 코드는 여기를 참조하자.(Embedding Dot 원본 코드는 여기)
# Embedding Dot 계층 구현
import numpy as np
from common.layers import Embedding, SigmoidWithLoss
class EmbeddingDot:
def __init__(self, W):
# 임베딩 계층 생성
self.embed = Embedding(W)
# 임베딩 계층의 파라미터 가져오기
self.params = self.embed.params
self.grads = self.embed.grads
self.cache = None
def forward(self, h, idx):
# W_out 파라미터에서 특정 idx에 해당하는 행 벡터만 추출
target_W = self.embed.forward(idx)
# dot을 안하고 곱(*)하는 이유: 어차피 하나의 행 벡터와 열 벡터를 내적하는 것이기 때문에 곱하는 것과 동일.
# 곱(*) 사용하면 행 벡터, 열벡터 shape 맞춰줄 필요도 없이 편함
out = np.sum(target_W * h, axis=1)
self.cache = (h, target_W) # 역전파 시 해당 값들을 사용해야 하므로 캐싱해두기
return out
def backward(self, dout):
h, target_W = self.cache
# 1개의 값만 있는 dout들이 배치 사이즈만큼 있음 -> 행렬 곱 수행하기 위해
dout = dout.reshape(dout.shape[0], 1)
# 1. dot 계층 역전파 - 곱셈 노드의 역전파 = 순전파 시 반대편 입력을 곱하면 됨!
dtarget_W = dout * h
dh = dout * target_W
# 2. 임베딩 계층 역전파
self.embed.backward(dtarget_W)
return dh3-4. 미리 점 찍어(?) 놓는 방법! Negative Sampling
다중분류에서 이진분류로 바꾸는 과정에서 핵심 중 하나는 정답일 것 같은 데이터를 미리 점 찍어(?) 놓고 이 점 찍은 정답이 진짜 정답인지 아닌지 판별하는 이진분류로 바꾸는 것이라고 했다. 위에서 예시를 들은 것처럼 'you' 와 'goodbye' 라는 2개의 맥락 단어가 주어졌을 때, 가운데 나올 단어를 진짜 정답인 'say'로만 미리 찍어놓고 이진분류로 변경한 후 모델을 학습시킨다. 하지만 이렇게 '진짜 정답'만 학습하는 경우에는 '정답이 아닌 경우' 예를 들어, 'say' 가 아닌 'I', 'he', 'she' 와 같은 다른 단어를 점 찍어놓았을 때, 모델이 어떤 결과를 내놓을지 예상할 수 없다. 막말로 정답이 아닌 경우에 대해서 학습이 잘 되지 않은 상태라면 'he' 라는 단어에 대해서도 정답이라고 예측할 지도 모른다.
따라서 우리는 진짜 정답인 'say' 단어를 미리 찍어놓는 경우(이를 긍정적이라 하여 Positive 라고 함) 말고도 정답이 아닌 경우에 대해서도 모델을 학습시켜야 한다. 그래야 모델이 정답이 아닌 경우도 잘 분별해낼 수 있을 것이다. 그래서 '정답이 아닌 경우'를 부정적 즉, Negative라고 하여 Negative Sampling 이라고 하는 것이다.
그런데 여기서 생각해볼 필요가 있는 점이 하나 있다. 예를 들어, 100만개의 Vocabulary size가 있다고 가정하자. 그리고 'you'와 'goodbye'라는 2개의 맥락 데이터를 입력으로 했을 때, 가운데가 나올 단어가 무엇인지 예측하려고 한다. 그러면 이 때, 가운데에 나올 100만개의 단어 후보군들 중 정답(Positive)인 단어들이 많을까? 정답이 아닌 단어들(Negative)이 많을까? 당연히 Negative한 경우가 많을 것이다.
하지만 Negative한 경우는 많아도 너~무 많을 것이다. 그러면 이 Negative한 단어들을 모두 학습시켜야 할까? 그럴 수 없다. 왜냐하면 우리가 지금까지 임베딩 계층을 쌓고 다중분류에서 이진분류로 문제를 변경하려 했던 근본적인 목적은 기존 모델의 계산 병목현상을 해결하기 위함이었기 때문이다. 그런데 만약 모든 Negative한 단어들을 고려해야 한다면, 다시 계산 복잡도가 기하급수적으로 증가해 우리가 도달하려는 '계산 병목현상 해결'이라는 목적에서 벗어나게 된다.
따라서 우리는 수많은 Negative 단어들을 모두 고려하지 않고도 모두 고려한 것처럼에 '근사'하기 위해서 Negative 단어들 '몇 개'만을 선택해 학습시켜야 한다. 이러한 이유 때문에 Negative Sampling 에서 'Sampling' 이라는 단어가 붙은 것이다.
결론적으로 네거티브 샘플링 기법은 긍정적인 경우를 학습하면서 동시에 샘플링한 부정적인 경우 몇 가지를 함께 학습하게 된다. 함께 학습한다는 것은 고로 긍정적인 경우에 대한 손실함수 값을 구하고, 샘플링한 부정적인 경우들에 대한 손실함수 값을 각각 구하고, 계산한 모든 손실함수 값들을 모조리 합한 값을 최종 손실값으로 간주하게 된다.
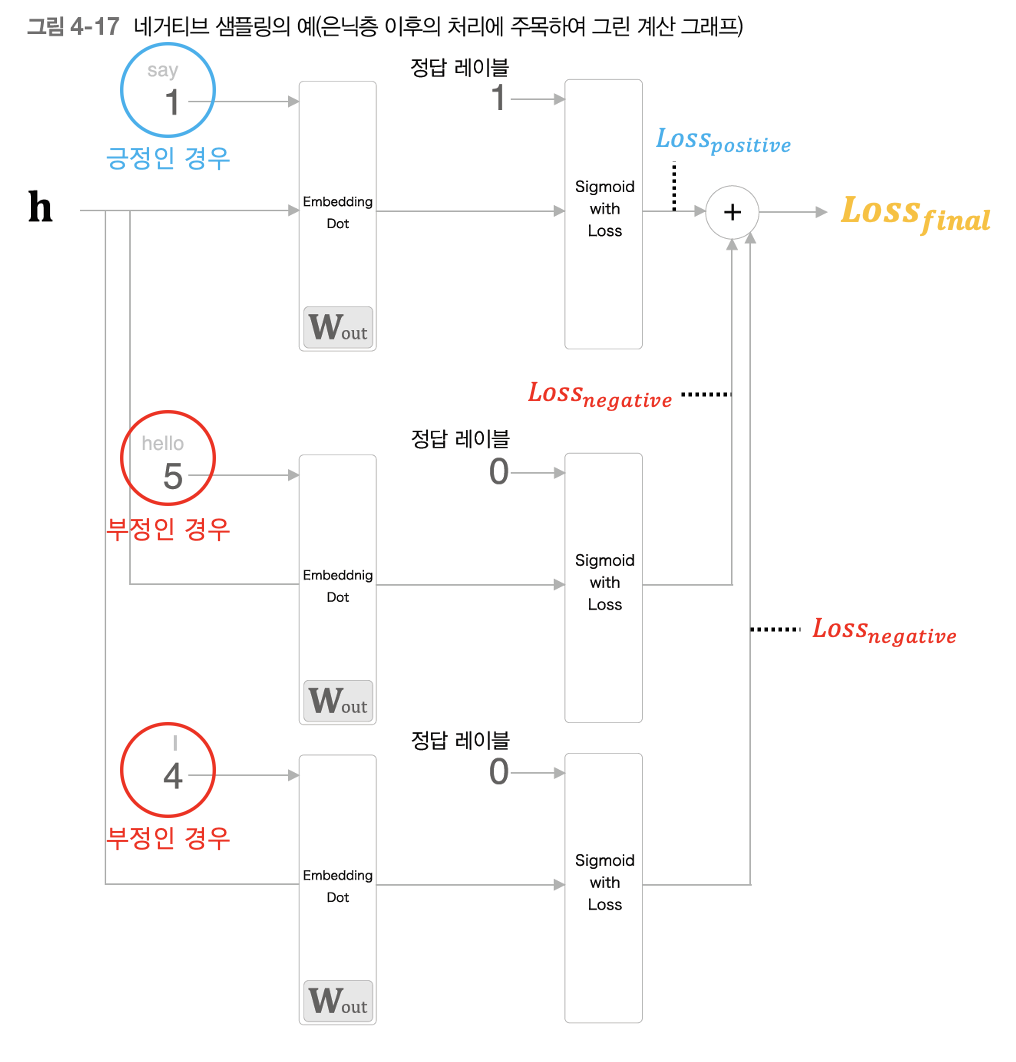
3-5. 그래서 어떻게 Samping 한다는 것인가?
위 내용까지 해서 Negatvie Sampling이 모델이 정답이 아닌 부정적인 경우에도 학습할 수 있도록 하기 위해 사용되는 것인지도 알아보았다. 그렇다면 부정적인 경우를 샘플링할 때 어떻게 샘플링을 할까? 그냥 무작위로 할까? 이에 대해서도 좋은 방법이 있다. 바로 주어진 말뭉치 데이터의 통계 지표를 기반으로 샘플링 하는 것이다. 여기서 통계 지표란, 단어의 확률 분포 즉, 단어의 발생 확률을 기반으로 샘플링 한다. 그렇기 때문에 단어의 발생 확률이 높은 즉, 말뭉치에서 자주 등장하는 단어는 많이 추출하고 말뭉치에서 드물게 등장하는 단어는 적게 추출하는 것이다.
말뭉치에서 단어의 확률 분포를 구하기 위해서는 말뭉치에서 각 단어별 출현 횟수를 바탕으로 구할 수 있다. 이렇게 구한 단어의 확률 분포를 기반으로해서 부정적인 경우들을 샘플링(Negative Sampling) 하면 되는 것이다!
그런데 word2vec에서 네거티브 샘플링을 수행할 때, 한 가지 사항을 권고한다고 한다. 말뭉치의 단어별 확률 분포를 구한 다음 각 단어별 확률에 0.75라는 숫자를 제곱하라는 것이다. 수식으로 나타내면 아래와 같다.
P′(wi)=P(wi)0.75∑njP(wj)0.75
위 수식에서 P(wi)는 말뭉치에서 i번째 단어인 wi 단어가 발생할 확률을 의미한다. 위처럼 P′(wi)로 wi라는 단어의 발생 확률을 새롭게 정의하는데, 기존 발생 확률 P(wi)에서 0.75 제곱을 해준다. 분모에서 ∑ 해주는 이유는 확률의 총합이 1이 되어야 하므로 일종의 스케일링 항이 되겠다.
그런데 위처럼 0.75를 제곱하면 어떤 효과가 발생하는 걸까? 매우 적게 출현하는 단어의 발생 확률을 약간 높여주는 효과가 있다. 그 말은 곧 발생 빈도가 적은 단어를 아예 배제하지는 않고 샘플링할 것이라는 걸 의미한다. 0.75 제곱의 효과를 간단하게 살펴보자. 아래와 같은 확률 분포가 각각 있다고 가정해보자.
import numpy as np
# 각 확률 분포
p = [0.8, 0.15, 0.05]
new_p = np.power(p, 0.75)
new_p /= np.sum(new_p)
new_p = np.round(new_p, 3)
print('기존 확률분포 p:', p)
print('새로운 확률분포 new_p:', new_p)

위 결과값을 보면 매우 적은 확률분포였던 0.15, 0.05가 새로운 확률 분포에서는 약간 확률 값이 상승한 것을 볼 수 있다. 반면 가장 확률이 높았던 0.8이 새로운 확률에서는 0.7로 낮아지기도 했다. 이렇게 0.75라는 숫자를 제곱함으로써 얻는 효과는 적은 발생 확률을 약간 높여주는 효과가 있다. 책에서는 제곱하는 수인 0.75가 절대적인 숫자값은 아니라고 한다. 사용 경우에 따라 유동적으로 바꿀 수 있다. 단, 적은 확률을 높여주기 위해서는 반드시 0과 1사이의 값으로 설정해야 하며 0과 1사이의 값 중에서도 0에 가까운 수를 제곱해줄수록 적은 확률을 더 큰 폭으로 높여주는 효과가 발생한다.
4. CBOW 모델을 평가해보자
이제 CBOW 모델을 PTB 벤치마크 말뭉치 데이터로 학습하고 성능을 평가해보자. 책에서는 위에서 소개한 임베딩 계층과 네거티브 샘플링을 모두 적용한 개선된 CBOW 모델 코드와 이를 학습하는 소스코드를 소개한다. 필자도 직접 따라쳐보며 구현해보았다. 해당 포스팅에서는 너무 길어질 것 같기에 CBOW 모델 설계 코드는 여기, 학습 코드는 여기를 참조하자.
여기서는 학습한 CBOW 모델의 단어 벡터(단어 분산 표현)를 가져와서 성능이 어떠한지 평가해보자. 학습한 CBOW 모델의 파라미터는 저자 Github에서 'cbow_params.pkl' 파일로 제공하고 있다. 그러면 이 pickle 파일을 로드해서 한 번 평가해보자.
# 이미 학습된 가중치를 불러와서 모델 평가해보기
import pickle
import random
from common.util import most_similar
pkl_file = 'cbow_params.pkl'
with open(pkl_file, 'rb') as f:
params = pickle.load(f)
word_vecs = params['word_vecs']
word_to_id = params['word_to_id']
id_to_word = params['id_to_word']
vocabulary = list(params['word_to_id'].keys())
querys = random.sample(vocabulary, 5)
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs)
위의 소스코드를 수행하면 아래와 같은 결과가 나타난다. 참고로 most_similar 함수는 예전 포스팅에서 만들어본 함수인데, 특정 단어를 입력시키면 해당 단어 벡터와 코사인 유사도를 기반으로 가장 비슷한 단어들을 출력해주는 함수였다.

결과화면을 보면 hard 라는 단어는 rough 라는 단어와 유사도가 가장 높은 것을 볼 수 있다. 또 미국식 이름에서 'Miss'를 의미하는 'ms.' 단어는 she, woman 등 여자 성별을 상징하는 단어와 유사한 것을 볼 수 있다.
5. word2vec의 남은주제
이번 목차는 word2vec 구현 이외의 주제에 대해서 간략하게 책에서 다룬다. 하나씩 핵심 내용만 살펴보자.
5-1. word2vec를 사용한 애플리케이션
word2vec를 구현하기 위해서는 매우 큰 연산장치가 필요하다. 그러므로 word2vec 에서는 전이학습이 매우 중요하다. 즉, 남이 거대한 하드웨어로 잘 학습시켜놓은 단어의 분산표현 즉 word2vec를 가져다 쓸 수 있다는 것이다. 보통 자연어 문제를 풀 때 word2vec를 처음부터 구현하는 일은 거의 드물다고 한다. 미리 누군가 학습시켜 놓은 단어의 분산표현을 가져와서 사용하는 것이 보통이라고 한다.
단어의 분산 표현이 중요한 이유 중 하나는 서로 다른 단어(문자열)를 고정된 길이의 벡터로 만들어 줄 수 있다는 것이다. 물론 단어가 모여서 만들어지는 문장들도 고정된 길이의 벡터로 만들 수 있다. 가장 간단한 방법은 문장을 이루고 있는 단어들의 분산 표현의 합을 구하는 것이다. 이를 BOW(Bag Of Words) 라고 한다. 우리가 이번에 배웠던 CBOW 모델이 그것이다. 하지만 BOW는 단순한 '합'이기 때문에 문장을 이루고 있는 단어 순서를 전혀 고려하지 않는다. 그래서 CBOW 모델은 문장을 생성하는 언어 모델(Language Model)에는 사용되지 않는다. 언어 모델로는 좀 더 발전된 방법으로 순환신경망(RNN)을 사용해 문장을 고정된 길이의 벡터로 변환한다. 이는 다음 챕터부터 소개되는 내용이기도 하다.
어쨌거나 word2vec는 서로 생김새가 다른 단어들을 고정된 길이의 벡터로 변환시켜줄 수 있다. 이렇게 고정된 길이의 벡터로 변환시켜주면 뭐가 좋을까? 바로 머신러닝 모델의 입력 데이터로 넣어줄 수 있다는 것이다!
예를 들어, 스팸 메일 분류기 머신러닝 모델을 만들려고 한다고 가정하자. 그렇다면 분류 모델을 만들기 위해 입력 데이터가 있어야 한다. 그러므로 입력 데이터로서 이메일 데이터를 수집한다. 그리고 어떤 이메일은 '스팸' 이다. '아니다' 라고 사람이 직접 레이블링 작업을 해준다. 이 작업이 끝나면 학습된 word2vec를 활용해서 입력 데이터(이메일의 텍스트 내용)를 벡터화시킨다. 그리고 벡터화 시킨 이 입력 데이터를 X 값으로, 레이블링한 레이블을 Y 값으로 하여 머신러닝 모델 분류기에 넣어주게 되면 머신러닝 모델은 스팸 메일의 패턴을 잘 파악할 수 있을 것이다.
5-2. 내가 사용하고 있는 word2vec는 좋은 것일까?
위에서 word2vec는 사람들이 이미 학습시켜놓은 word2vec를 활용하거나 여건만 된다면 내가 직접 word2vec를 구현할 수도 있을 것이다. 그러면 학습된 word2vec들도 여러개일텐데 어떤 게 좋은 word2vec이고 어떤 게 나쁜 word2vec일까? 그 판단하는 기준은 무엇일까?
word2vec를 평가하는 기준으로는 단어의 유사성 정도와 유추 문제를 얼마나 잘 풀어내는지 2가지를 주로 사용한다. 단어 유사성으로 평가를 할 때는 사람이 직접 작성한 유사도를 하나의 검증 도구로 사용한다. 예를 들어, 유사도 범위가 0부터 10사이로 존재한다면, 사람이 직접 'cat' 과 'animal' 단어 간의 유사도는 8점, 'cat' 과 'car'의 유사도는 3점으로 정의해놓는다. 그리고 이렇게 사람이 부여한 점수와 word2vec에서 얻어내는 코사인 유사도 점수와 비교를해 word2vec의 성능을 평가하게 된다.
다음은 유추 문제를 얼마나 잘 풀어내는지이다. 대표적인 예시로, king : queen = man : ? 에서 ?에 어떤 단어가 오는지 맞추는 것이 유추 문제이다. 이렇게 유추 문제를 word2vec를 활용해 풀어보고 정답률이 얼마나 높은지를 기준으로 word2vec의 성능을 평가한다.
잠시 책에서 소개하고 있는 성능 표를 보자. 아래 표에서는 '차수' 즉, 신경망 모델에서 은닉층 노드 개수를 의미하고 말뭉치 크기는 말 그대로 해당 신경망 모델을 학습시킨 말뭉치 데이터 크기이다. 그리고 '의미(semantics)'는 유추 문제를 잘 푸는지 정확도를 의미하고 '구문(syntax)'는 단어의 형태를 얼마나 잘 맞추는지이다. 예를 들어, bad : worst = good : ? 에서와 같이 ?를 잘 맞추는지 보는 것이다.(?에는 best가 들어가야 한다)
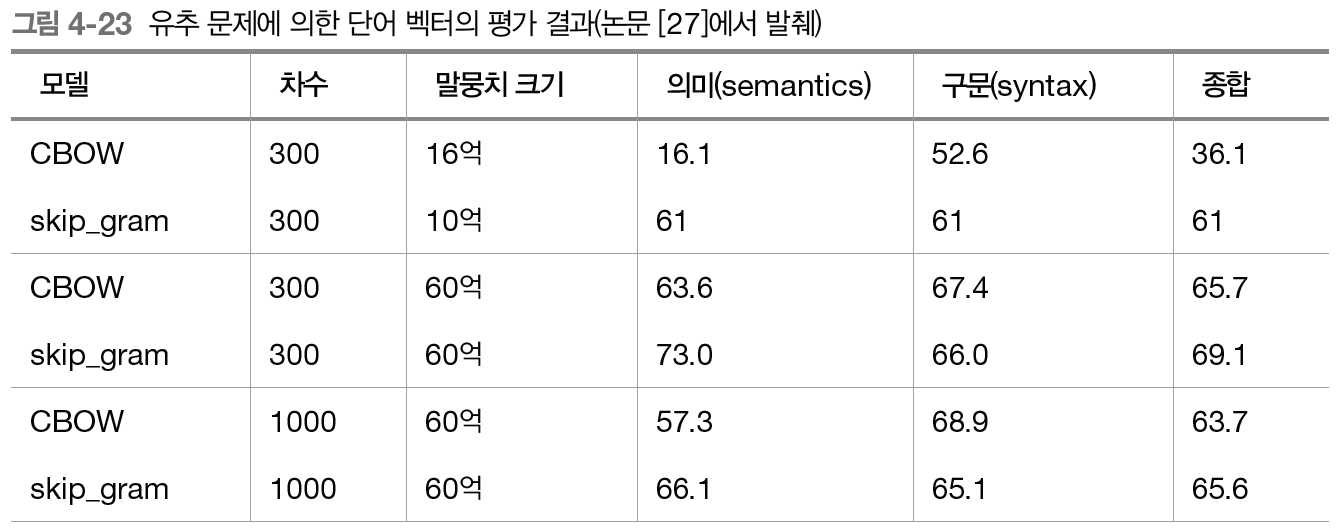
위 표에서 의미, 구문 항목에 대해 성능척도를 보자. 확실히 말뭉치 크기가 16억, 10억일 때보다 60억일 때가 정확도가 많이 상승했다.(특히 CBOW가 매우 상승) 그런데 말뭉치 크기는 동일하게 하되 차수(은닉층의 노드 개수)를 300에서 1000으로 늘렸더니 약간의 오버피팅이 발생한 것을 볼 수 있다. 따라서 말뭉치 크기는 클수록 정확도가 올라가지만 차수는 계속 늘렸다간 오버피팅 문제가 일어날 가능성이 높다는 것을 보여준다. 이것은 또 '데이터의 크기'가 그만큼 모델 성능에 크에 기여한다는 것을 시사하는 것이 아닐까 한다.
이렇게 해서 기나긴 word2vec 이론, 구현 챕터가 끝이 났다. 2개의 챕터로 배우게 되었는데 코드도 따라치면서 블로깅도 하느라 시간이 꽤 오래 걸린 듯 하다. 하지만 이론 뿐만 아니라 코드도 하나씩 쳐보면서 남의 코드를 이해하는 것에서도 정말 많은 것을 배울 수 있었다. 무엇보다 내 개인 레포지토리에도 나만의 방식으로 소스코드를 정리해서 나중에 넘파이를 직접 활용한 word2vec 구현 시에 도움을 많이 받을 수 있을 듯 하다. 이제 다음 챕터부터는 순환신경망(RNN)에 대한 내용이다. 점점 더 내용이 복잡해지면서 진도 나가는 속도가 느려지는 게 체감된다. 그래도 조금 느리더라도 꾸준히 학습해보도록 하자!
'Data Science > 밑바닥부터시작하는딥러닝(2)' 카테고리의 다른 글
| [밑시딥] 게이트가 추가된 RNN, LSTM(Long-Short Term Memory) (2) | 2021.12.16 |
|---|---|
| [밑시딥] 과거의 기억을 그대로, 순환신경망(RNN) (4) | 2021.12.09 |
| [밑시딥] 단어의 분산을 표현하는 또 다른 기법, word2vec (2) | 2021.11.30 |
| [밑시딥] 오직! Numpy로 단어의 분산 표현하기 (0) | 2021.11.26 |
| [밑시딥] 오직! Numpy로 구현했던 딥러닝 신경망 복습 (0) | 2021.11.25 |



