🔊 해당 포스팅은 밑바닥부터 시작하는 딥러닝 2권의 교재 내용을 기반으로 자연어처리 딥러닝 신경망을 Tensorflow, Pytorch와 같은 딥러닝 프레임워크를 사용하지 않고 순수한 Numpy로 구현하면서 자연어 처리의 기초를 탄탄히 하고자 하는 목적 하에 게시되는 포스팅입니다. 내용은 주로 필자가 중요하다고 생각되는 내용 위주로 작성되었음을 알려드립니다.

이번 포스팅부터는 밑바닥부터 시작하는 딥러닝 2권을 학습하면서 배운 내용을 기록해보려 한다. 2권은 주로 자연어 처리에 관련된 내용이다. 필자는 개인적으로 Weekly NLP를 통해서 자연어 처리에 입문했었는데, 그 때는 이론적인 측면에서 접근했다고 한다면 이번엔 이론을 더 깊게 파보면서 넘파이로 구현하는 과정까지 어떻게 신경망으로 자연어 처리를 할 수 있는지에 대해 공부해보려 한다. 본격 자연어 처리에 도입하기 전에 첫 장은 1권의 내용을 전체적으로 복습하는 내용이다. 여기서는 필자가 생각하기에 1권에서는 없었지만 2권에는 있는 내용에 대해 주로 포스팅하려 한다.
1. 계산 그래프를 활용해 오차역전파 이해하기
1권 내용을 다루면서 여러가지 연산 노드(덧셈, 나눗셈, 로그, 행렬 곱, 활성함수 등등)에 대해서 역전파를 수행할 때, 상류에서 흘러들어온 값을 어떻게 전달하는지에 대해 배웠었다. 여기서는 1권 내용에서 다루지 않았던 분기 노드, Repeat 노드, Sum 노드에 대해 역전파를 수행하는 방법에 대해 알아보자. 이번에 배울 연산 노드는 1권 내용에서 배웠던 것에 비해서 매우 간단하므로 겁먹지 말자!
1-1. 분기 노드
분기 노드란, 아래와 같은 그림의 형태의 계산 그래프를 의미한다.

별다른 '연산'을 하는 노드는 없지만, 계층 종류별로 구현하다보면 이런 분기노드가 존재할 때가 있다. 위는 순전파 시 전달되는 방법인데, 단순히 똑같은 $x$ 값을 갈라지는 분기로 각각 동일한 $x$ 값을 보내면 된다. 그렇다면 위 분기노드가 역전파될 때는 어떤 식으로 계산 그래프가 그려질까?

위 그림을 보면 갈라진 2개의 분기로부터 역전파가 수행될 때 동일한 ${\partial y \over \partial x}$라는 미분값이 전달된다. 그렇다면 갈라진 2개 분기가 합쳐진다면 각 분기로 들어온 ${\partial y \over \partial x}$ 미분값 2개를 더해주면 된다.
1-2. Repeat 노드
위에서 2개로 분기되는 노드를 살펴보았다. 분기 노드가 N개로 일반화(확장)되면 그것이 바로 Repeat 노드이다. 아래 그림처럼 말이다.

위 그림처럼 N개로 복제하는 것이다. 그렇다면 역전파는 반대로 수행해주는 것이다. 단, 하나로 합쳐주기 위해서 복제된 N개를 행 방향(axis=0)으로 sum을 취해주면 된다.

위 Repeat 노드의 순전파, 역전파 과정을 넘파이로 구현하면 아래와 같다.
# Repeat 노드
D, N = 8, 7
# 순전파
x = np.random.randn(1, D)
y = np.repeat(x, N, axis=0) # 행 방향으로 복제!
print('x:', x.shape)
print('y:', y.shape)
# 역전파
dy = np.random.randn(N, D) # (7, 8)
dx = np.sum(dy, axis=0, keepdims=True) # 2차원 유지
print('dy:', dy.shape)
print('dx:', dx.shape)1-3. Sum 노드
다음은 Sum 이다. Sum 노드는 여러가지 분할된 가지에서 하나로 모아(합해)주는 것이다. 위 Repeat 노드에서 역전파를 수행할 때 처럼 말이다. 그래서 Sum 노드의 순전파, 역전파 과정은 아래와 같다.
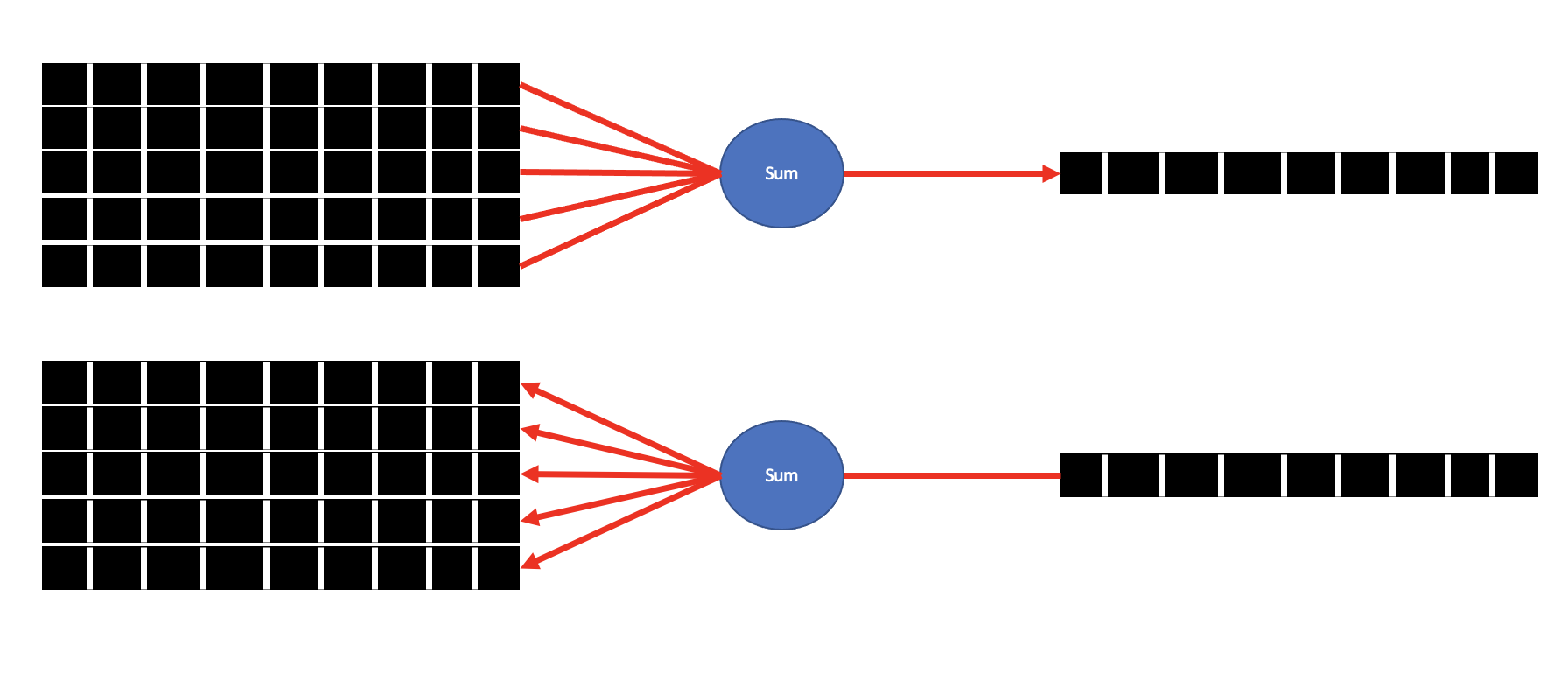
위 과정을 넘파이로 구현하면 아래와 같다. 단지, Repeat 노드를 반대로 구현하면 된다!
# Sum 노드 - repeat노드와 반대 관계!
D, N = 8, 7
# 순전파
x = np.random.randn(N, D) # (7, 8)
y = np.sum(x, axis=0, keepdims=True)
print('x:', x.shape)
print('y:', y.shape)
# 역전파
dx = np.random.randn(1, D)
dy = np.repeat(dx, N, axis=0)
print('dx:', dx.shape)
print('dy:', dy.shape)
그리고 책에서는 MatMul 연산에 대해서 소개하는데, 이는 저번 포스팅에서 다루었으니 생략하겠다. 여기의 목차 'Affine 계층' 부분을 보면 된다.
그리고 책에서 개념을 설명하면서 넘파이의 특이한 문법을 하나 알게되었다. 바로 점 3개로 이루어진 생략(ellipsis) 기호(...) 이다. 이 기호를 사용하게 되면 넘파이 배열에서 깊은 복사가 이루어진다. 파이썬에서도 깊은 복사, 얕은 복사 개념이 있었는데, 넘파이에서도 존재한다는 것을 처음 알았다. 우선 아래와 같은 넘파이 배열이 있다고 가정해보자.
import numpy as np
a = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
a라는 2차원 배열에서 우리는 [1,2,3] 원소를 [100,200,300]으로 갱신하려고 한다. 그러면 보통은 아래처럼 코드를 수행해 변경한다.
a[0] = [100,200,300]
위 코드를 수행하고 배열 a를 출력하면 잘 변경된 것을 볼 수 있다. 하지만 이렇게 하는 것은 일명 '얕은 복사' 이다. 얕은과 깊은을 구분하는 차이점은 넘파이 배열이 가리키는 메모리 위치를 고정시키고 덮어쓰기를 하는 것인지 아닌지이다. 넘파이 배열이 가리키는 메모리 위치를 고정시키지 않는 것이 얕은 복사이다. 얕은 복사와 깊은 복사의 차이를 도식화하는 자료는 책의 자료를 빌리겠다.
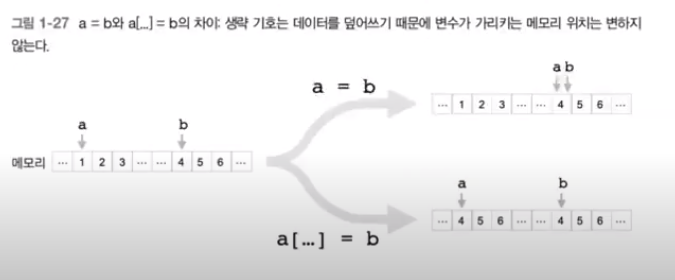
그렇다면 깊은 복사를 하기 위해서는 생략 기호(...)을 사용해야 한다. 위 a라는 배열을 다시 깊은 복사로 수행해보자.
import numpy as np
a = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
a[0][...] = [100,200,300]
print(a)
이렇게 깊은 복사를 하는 이유는 넘파이로 신경망을 구현할 때, 매개변수의 기울기를 계속 저장해야 하기 때문이다. 매개변수의 기울기는 학습 시마다 계속 갱신되므로 깊은 복사를 수행하면 메모리 주소가 변하는 일 없이 항상 값을 덮어쓰기 때문에 기울기를 그룹화하는 작업을 최초에 한 번만 하면 된다는 장점이 생긴다고 한다.
2. 계산 고속화
1권의 마지막 부분에서 나온 이야기긴 하지만 이전에 따로 언급한 적은 없었다. 2권에서 짧게 소개하고 있어 해당 내용을 소개해본다. 보통 우리가 사용하는 넘파이는 64비트의 부동소수점을 사용한다. 자기가 활용하고 있는 넘파이가 몇 비트의 부동소수점을 사용하고 있는지 확인하기 위한 코드는 아래와 같다.
import numpy as np
a = np.random.randn(1)
a.dtype
필자도 64비트를 사용하고 있다. 이렇게 '몇 비트'라고 표현하는 것은 '비트 정밀도'라고 한다. 결국 비트의 값이 클수록 그만큼 표현할 수 있는 수가 많음을 의미하고 더 정확한 연산을 수행할 수 있다. 하지만 모델과 데이터가 커짐에 따라 64비트가 신경망의 학습, 추론 속도를 제한하거나 학습된 모델을 저장할 때 용량이 너무 커진다는 문제를 발생시킬 수도 있다.
보통 신경망의 추론과 학습 과정에서 32비트 부동소수점의 수로도 성능의 저하없이 학습과 추론을 모두 수행할 수 있다고 한다. 이렇게 64비트에서 32비트로 줄인다면 학습 속도도 빨라질 뿐만 아니라 모델을 저장할 때도 용량이 절반으로 줄어들 것이다. 또 신경망 계산 시 데이터를 전송하는 '버스 대역폭(bus bandwidth)'이 병목이 되는 문제도 막을 수 있다.
그렇다면 내가 사용하고 있는 64비트의 넘파이를 32비트로 바꾸려면 어떻게 할까? astype을 활용하면 된다.
import numpy as np
a = np.random.randn(1).astype(np.float32)
a.dtype
신경망을 '추론'만 한다는 범위로 한정한다면, 32비트의 절반인 16비트에서 마저도 모델의 성능 저하 없이 추론을 잘한다고 한다. 물론 넘파이에도 16비트로 변환할 수는 있지만, CPU, GPU가 애초에 연산 자체를 32비트로 수행하기 때문에 16비트로 변환한다고 해도 처리 속도 측면에서는 혜택이 없을 수도 있다. 하지만 학습된 모델을 저장 시 16비트를 활용해야 한다면 이득이 될 수 있을 듯 하다!
이렇게 해서 2권의 챕터 1 내용을 마쳤다. 그동안 한 내용을 복습하고 따로 코드도 따라치면서 여러가지를 다시 배울 수 있었다. 참고로 책 버젼마다 깃헙 레포지토리의 디렉토리를 다르게 하고 있다. 따라치다보니 1권 때의 변수를 정의하는 데이터 타입과 같은 세부적인 코드가 변경되었으므로 복습할 겸 다시 구현했다. 1권에 대한 코드는 여기, 2권에 대한 코드는 여기이다. 물론 필자가 사용할만한 코드를 저장해놓은 것이고 원 저자 코드는 여기를 참고하자.
'Data Science > 밑바닥부터시작하는딥러닝(2)' 카테고리의 다른 글
| [밑시딥] 게이트가 추가된 RNN, LSTM(Long-Short Term Memory) (2) | 2021.12.16 |
|---|---|
| [밑시딥] 과거의 기억을 그대로, 순환신경망(RNN) (4) | 2021.12.09 |
| [밑시딥] Embedding 계층과 Negative Sampling으로 효율적인 word2vec 구현하기 (2) | 2021.12.03 |
| [밑시딥] 단어의 분산을 표현하는 또 다른 기법, word2vec (2) | 2021.11.30 |
| [밑시딥] 오직! Numpy로 단어의 분산 표현하기 (0) | 2021.11.26 |



