앞으로 전개할 내용은 Coursera 딥러닝 강의의 내용을 기반으로 필자가 직접 정리하는 내용이며 해당 컨텐츠 이외의 다른 강의에 관심이 있다면 여기를 참고해 수강해보자.
이번 포스팅에서 다룰 주제는 분류 문제에서의 '데이터 분할'에 대한 내용이다. 머신러닝 모델을 학습시키고 검증하고 테스트 하기 위해서는 내가 갖고 있는 데이터를 적당하게 나누어 주어야 한다. 보통 갖고 있는 데이터 셋이 학습용, 검증용(개발용), 테스트용 총 3가지로 나누는데, 이에 대해 자주 적용되는 데이터 분할 비율, 각각은 어떤 역할을 하는지에 대해서는 이전 포스팅에서 소개했으므로 이에 대한 내용은 생략하고 다른 측면에서 다루어 보려고 한다.

이번 포스팅에서 중점적으로 다루려는 부분은 데이터를 분할하면서 고려해야 할 점과 각 데이터에 대한 모델 성능을 관찰함으로써 얻을 수 있는 모든 인사이트에 대해 다루려고 한다.
1. 각각의 분포를 고려해서 데이터를 분할해야 한다!
머신러닝을 구축하고 상용화 시키기 위해서는 머신러닝을 우선 데이터로 학습시키고 성능이 괜찮은지 검증 및 테스트 해보아야 한다. 그런데 이 학습, 검증, 테스트 데이터를 분할할 때 각 데이터들의 분포를 고려해야 한다.
우선 검증과 테스트 데이터들의 분포는 같은 분포로부터 유래해야 한다. 왜냐하면 검증 데이터의 목적은 테스트 데이터로 모델을 최종 평가하기 전 하이퍼파라미터 튜닝과 같은 모델 성능 향상이기 때문이다. 예를 들어, 검증 데이터와 테스트 데이터의 분포가 다를 때, 검증 데이터로 모델의 하이퍼파라미터 튜닝을 시도하고 이후 성능이 괜찮다고 판단되어 테스트 데이터에 적용을 해보았다.
그런데 이런 웬걸? 테스트 데이터에 대한 성능이 매우 낮아졌다.
이유는 왜일까? 당연히 테스트 데이터는 검증 데이터와 비슷하게 생기지 않았기 때문이다. 따라서 검증 데이터만을 기준으로 모델의 파라미터를 튜닝했기 때문에 검증 데이터와 생김새가 다른 낯선 테스트 데이터를 모델이 만났으니 예측 정확도가 내려갈 수 밖에 없다.
반면에 학습 데이터와 검증(또는 테스트) 데이터와의 분포가 같다면 매우 이상적이지만 만약 분포가 달라도 상관은 없다고 하지만 맞춰주는 것이 좋다고 한다. 그렇다면 분포가 다르다면 어떻게 해야할까? 우선 다음과 같은 이미지 종류의 데이터가 있다.

예를 들어, 우리는 위와 같이 사진 속 카메라의 객체를 인식하고 카메라로 분류하는 머신러닝 모델을 만들어본다고 가정하자. 분류 모델을 학습시키기 위해서 우리는 구글에 '사진작가 사진'과 같은 키워드로 검색해 카메라가 들어있는 수많은 화질이 좋은 이미지를 크롤링하여 학습 데이터로 만들 수 있다. 즉, 그림의 왼쪽과 같은 고화질 이미지를 말이다. 반면에 검증 데이터는 실제 환경에서 맞닥뜨릴 데이터와 비슷하도록 만들기 위해 화질이 좋지 않은 이미지 데이터들로 구성시킨다. 그래서 결국 우리는 분포가 서로 다른 학습 데이터와 검증 데이터를 얻었다.
이러한 경우, 우리는 어떻게 올바르게 데이터를 분할 할 수 있을까?
첫 번째, 그냥 다 ~ 합쳐서 마구 섞어서 다시 분할하자!
제목 그대로 분포가 서로 다른 학습, 검증 데이터를 서로 합쳐 하나의 데이터로 만든후 랜덤하게 마구 섞어준다.(Shuffle 수행) 그리고 다시 학습, 검증 데이터로 랜덤하게 분할한다. 이렇게 되면 학습, 검증 데이터의 분포가 서로 유사해질 수 있다. 하지만 이 방법은 단점이 존재한다. 우선 학습 데이터는 검증 데이터보다 수치적으로 훨씬 많은 갯수를 갖는다. 그런데 이를 무작위로 분할 후 검증 데이터 안의 분포를 살펴본다면 확률적으로 저화질 이미지(실제 모델을 검증하는 데 사용될 이미지) 개수는 고화질 이미지보다 현저하게 적을 것이다.

위 그림을 보면서 이해해보자. 검증, 테스트 데이터의 분포를 집중적으로 살펴보자. Shuffle을 하기 전 검증, 테스트 데이터의 분포를 보면 저화질 이미지 데이터 비율이 더 많다. 이 분포 상태가 위에서 언급했던 것처럼 바람직한 상태이다. 반면에 Shuffle을 수행하고 무작위로 분할한 후의 검증, 테스트 데이터의 분포를 살펴보자. 무작위로 분할했기 때문에 총 데이터 개수가 많은 고화질 데이터가 확률적으로 더 많이 검증, 테스트 데이터로 분할될 가능성이 높다. 따라서 이러한 방법은 모델을 검증하고 테스트 하기에는 부적절한 방법임을 알 수 있다.
두 번째, 실제 주어질 데이터를 검증, 테스트 데이터에 몰빵시키자!
이 방법은 실제 환경에서 맞닥뜨릴 저화질 이미지를 검증, 테스트 데이터에 거의 몰아주는 것이다. 다음 그림을 보자.

위 그림의 첫 번째 막대를 보면 학습 데이터에는 저화질 이미지를 하나도 분포시키지 않는 것을 볼 수 있다. 반면에 두 번째 막대를 보면 저화질 이미지 데이터 일부를 학습 데이터에 분포시킨다. 이 두 막대 중 장기적으로는 두 번째 막대와 같은 방법이 좋다고 한다. 즉, 학습 데이터에 저화질 이미지를 일부 분포시킴으로써 실제 주어질 데이터에 대비하면서 학습을 하고, 저화질 이미지로만 구성된 검증, 테스트 데이터로 모델을 실제 서비스화시켰을 때와 가장 가까운 성능이 나오게끔 한다.
2. 학습, 검증, 테스트 데이터에 대한 성능을 보고 인사이트 도출하기
지금까지 배웠던 방식으로 학습, 검증, 테스트 데이터를 올바르게 분할했다. 물론 학습, 검증, 테스트 데이터에 대한 성능이 모두 좋게 나온다면 더할나위 없이 좋을 것이다. 하지만 안타깝게도 현실은 그렇지 못한 경우가 대부분이다. 그렇다면 학습, 검증, 테스트 데이터에 대한 성능을 각각 비교함으로써 모델이 어떤 문제점을 갖는지 판단할 수 있는지 살펴보자.
우선 살펴보기 전에 Train Dev라는 고화질, 저화질 이미지 데이터가 같이 분포하는 데이터 셋을 다음 그림과 같이 하나 더 분할하자.

그리고 다음과 같이 각 데이터 셋에 대한 Error값들을 얻었다.
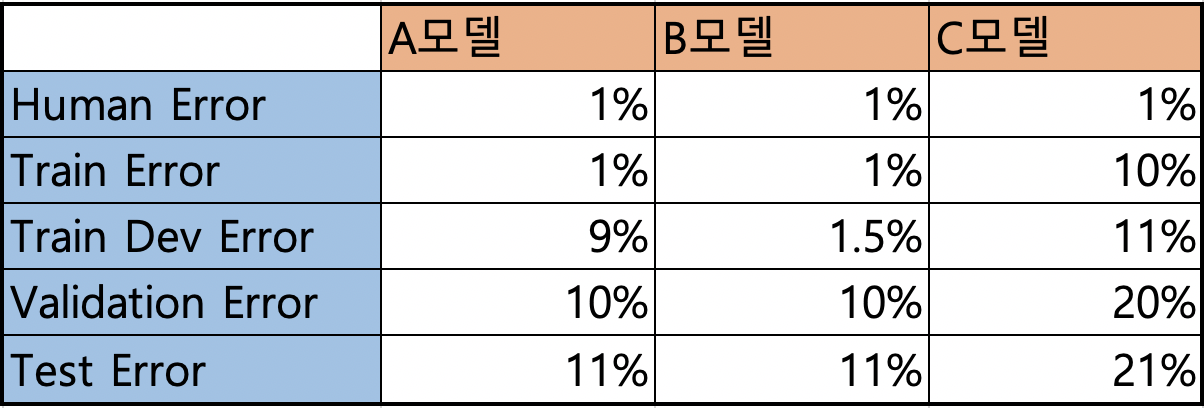
위 표를 설명하기에 앞서 'Human Error' 에 대해서 간단하게 짚고 넘어가보자. 'Human Error' 란, 말 그대로 인간의 능력으로 해당 문제를 예측할 때 에러를 의미한다. 예를 들어 고양이를 분류하는 문제를 해결할 때 인간이 직접 이 문제에 착수한다면 대략적으로 에러값은 1%내외일 것이다.(물론 이미지 데이터가 정말 형체를 알아볼 수 없을 정도로 손상된 이미지가 아니라고 한다면 말이다) 그리고 이 Human Error 보다 더 낮은 에러값을 Bayes Error(Optimal Error)라고 부른다. Bayes Error란, 보통 0%에 해당하는, 그야말로 '신의 영역에 해당하는 에러값'을 의미한다고 보면 된다. 마치 방금 예시를 들은 것처럼 형체를 알아볼 수 없을 정도로 손상된 이미지 데이터도 Bayes Error는 분류 정확도가 100%라는 것이다. 결국 Human Error는 항상 Bayes Error 보다 작거나 같은 값일 수 밖에 없다.
따라서 우리가 구축한 모델의 객관적인 성능을 파악하기 위해서는 Human Error를 파악해야 한다. 그리고 모델의 성능을 이 Human Error와 비교함으로써 정말 시중에 서비스화시킬 수 있는지 판단하는 기준점이 된다.
설명이 길었다. 이제 본격적으로 표를 살펴보자. 우선 A모델의 지표를 보자. Train Error가 Human Error와 비슷하게 나온 것으로 보아 학습 데이터에는 매우 예측을 잘하는 편이다. 그러나 저화질의 이미지 데이터가 조금 섞인 Train Dev Error를 보면 9%로 성능이 매우 저하된 것을 볼 수 있다. 이런 것으로 보아 해당 모델이 Train 데이터에만 너무 Overfitting 되었다는 문제를 발견할 수 있다.
다음 B모델을 살펴보자. A모델과 마찬가지로 Train Error가 Human Error와 비슷하게 나와 학습 데이터에는 매우 예측을 잘하는 편이다, 그리고 Train Dev Error도 비슷한 값으로 나왔기 때문에 "어? B모델이 어느정도 저화질의 이미지 데이터를 학습했나 보네!" 라고 추측한다.
그러나 저화질의 이미지 데이터가 더 많이 존재하는 Validation Error에서 갑자기 에러값이 매우 상승했다. 이러한 상황은 바로 'Data Mismatch' 문제를 의미한다. 즉, 학습 데이터(여기서는 Train, Train Dev 데이터셋)와 검증, 테스트 데이터 간의 분포가 다르다는 것을 의미한다. 따라서 이러한 문제를 해결하기 위해서 Train Dev 데이터셋을 자세히 살펴보고 검증, 테스트 데이터셋과 유사한 분포를 갖는 데이터 즉, 저화질의 이미지 데이터를 추가적으로 수집해 Train Dev에 넣어준다. 또는 인위적으로 합성한 데이터를 만들 수도 있다. 하지만 이 합성한 데이터는 어느정도 효과가 있지만 이 합성 데이터가 데이터의 대부분을 차지해서는 안 된다.
마지막으로 C모델을 살펴보자. A, B 모델과 달리 Train Error에서부터 Human Error와 큰 성능 차이를 보인다. 이는 결국 Bias 문제가 발생했음을 의미하며 곧 Underfitting을 의미한다. 따라서 모델을 재구축하거나 데이터를 더 수집하는 것이 바람직할 것이다.
# Error Analysis
이렇게 예시로 몇 가지 경우를 들어보면서 각 데이터셋의 에러값들을 비교해봄으로써 발생하는 문제를 추론해볼 수 있었다. 마지막으로 모델의 Error Analaysis(오류 분석)에 대해서 언급하고 글을 마무리하려고 한다.
Error Analysis는 주로 Validation 데이터 셋에서 애초에 잘못된 데이터 레이블링으로 인해 모델이 잘못 분류한 데이터들을 일일이 직접 관찰하는 것이다. 이러한 분석은 어떤 문제가 있는지 파악하고 이를 개선함으로써 전반적인 모델의 성능 개선 효과를 일으킬 수 있다.
오류 분석을 수행할 때는 FP(False Positive : 모델이 True라고 예측했을 때 실제 데이터가 False인 경우)와 FN(모델이 False라고 예측했을 때 실제 데이터가 True인 경우) 두 가지 경우 모두 찾고 무엇 때문에 오분류 되었는지 개수를 개수와 비율별로 직접 손수 계산을 한다.

오분류된 데이터를 손수 바로잡을지 판단하기 위해서는 다음과 같은 3가지 사항을 파악해보고 결정하자.
- Overall Validation set error : 검증 데이터에서 나온 에러값
- Errors due to incorrect labels : 애초에 데이터 레이블링이 잘못된 데이터로 인한 에러값
- Errors due to other causes : 모델이 오분류한 데이터들로 인한 에러값
만약 1번이 10%, 2번이 0.6%, 3번이 9.4%라고 한다면 잘못된 데이터 레이블링으로 인한 에러값이 매우 적은 비율을 차지하기 때문에 이 경우에는 오류 분석을 수행하는 경우보다 모델을 튜닝하는 방법이 시간을 절약할 것이다.
반면에 1번이 2%, 2번이 1.4%, 3번이 0.6%라고 한다면 이러한 경우에는 오류 분석을 수행해 잘못된 레이블링을 바로 잡는 작업이 모델 성능 향상에 큰 기여를 할 것이다.
그런데 후자의 경우처럼 검증 데이터에서 잘못된 데이터 레이블링을 수행했다면 테스트 데이터에서도 동일하게 잘못된 레이블링이 있는지 살펴보고 수정해주어야 한다. 즉, 검증과 테스트 데이터의 분포를 일치시켜주어야 한다. 참고로 학습 데이터는 검증, 테스트 데이터에 비해 상대적으로 잘못된 레이블링을 수정하는 것이 덜 중요하다고 여겨진다.(개인적으로 이유는 학습 데이터 개수가 매우 많기 때문이라고 생각한다. 혹여라도 학습 데이터가 잘못된 레이블링이 많다고 하면 그 데이터 자체를 수정하는 것보다 해당 데이터를 사용하지 않고 다른 데이터를 찾는 것이 바람직하다고 생각한다..)
'Data Science > Machine Learning' 카테고리의 다른 글
| [ML] Bayesian Optimization으로 파라미터 튜닝하기 (0) | 2021.01.02 |
|---|---|
| [ML] PCA, 주성분의 개수는 어떤 기준으로 설정할까? (6) | 2020.12.08 |
| [ML] 데이터를 복구하는 Auto Encoder? (0) | 2020.11.07 |
| [ML] Hyperparameter tuning & Optimization in DNN (0) | 2020.10.31 |
| [ML] How to improve Deep Neural Network? (2) | 2020.10.24 |



