이번 포스팅에서는 범주형 변수간의 상관관계를 분석하는 방법에 대해 알아보려고 한다. 우리가 그동안 자주 사용해왔던 Pearson Correlation, 즉, 상관관계 분석은 수치형 변수간의 관계를 분석하는 데만 사용이 된다.

물론 한 가지 예외 사항이 있다. 예를 들어 2개의 변수가 존재할 때, 한 변수는 연속적인 수치형 변수이고 다른 변수는 수치형의 binary값(0 또는 1로 one-hot encoding되어 있는 상태)으로 변환되어 있는 범주형 변수라고 하자. 이 때 범주형 변수가 어찌됬건 수치형 변수로 변환되어 있는 상태이기 때문에 두 변수간의 Pearson Correlation을 구해 두 변수간의 관계를 구할 수 있다.(근본적으로는 Point-biserial Correlation(점-이연 상관계수)라고 부른다)
이번 포스팅에서는 위와 같은 예외사항도 아닌 두 변수 모두 일정한 level 개수를 갖는 범주형 변수일 때 두 변수간의 관계를 구하는 방법에 대해 알아보려고 한다. 우선 범주형 변수들이 1개인지 2개인지에 따라 적합도 검정인지 독립성과 동질성 검정인지 나뉜다. 참고로 앞으로 소개할 3가지 방법은 모두 범주형 데이터가 오른쪽으로 Skewed된 모양의 카이제곱 분포를 따른다고 가정한다.

1. 적합도 검정
적합도 검정은 일변량 범주형 변수일 때 사용하는 검정 방법이다. 즉, 범주형 변수가 한 개일 때 이 변수가 갖는 여러가지 level 값들 빈도수 간의 관계를 살펴보자. 한개의 범주형 변수의 여러가지 level값들의 실제 관측 빈도수와 기대 빈도수의 차이를 검정하는 것이다.
적합도 검정의 귀무가설과 대립가설은 다음과 같다.
- 귀무가설 : 범주형 변수의 각 level 값들의 관찰빈도, 기대빈도 간의 차이가 없다.
- 대립가설 : 범주형 변수의 각 level 값들의 관찰빈도, 기대빈도가 적어도 1개 이상 다르다.
위 2개의 도수를 [관찰도수 - 기대도수] 빼기(-) 연산을 하여 차이값을 구해준다. 하지만 이 때 차이값이 음수의 값도 나오기 때문에 이로 인한 상쇄 문제를 방지하기 위해 제곱을해주고 상대적인 비중을 만들기 위해 기대도수값으로 나누어 준다.
이렇게 되면 각 level 값들마다 상대적인 비중을 갖는 [관찰도수 - 기대도수] 값이 계산되며 이 하나의 차이값을 하나의 Random Variable(확률변수)로 하여 따르는 분포가 바로 카이제곱 분포이다.
또한 각 level 마다 도출된 차이값들의 합이 카이제곱 검정 통계량이 되고 이 검정 통계량 값이 나올 확률을 P-value(유의확률)이라고 한다. 따라서 만약 P-value값이 디폴트 유의수준 0.05보다 작다면 귀무가설을 기각하며, 반대로 크다면 귀무가설을 채택하게 된다.
2. 동질성 검정
동질성 검정과 독립성 검정 모두 2개의 범주형 변수간의 관계를 파악할 때 사용하는 방법이다. 하지만 두 방법간에 차이점은 존재한다. 이 차이점에 대해서 정확하게 알아두고 앞으로 범주형 데이터간의 관계를 분석하면서 어떤 범주형 데이터에는 동질성 검정을, 또 어떤 데이터에는 독립성 검정을 사용해야하는지에 대해서 알아두자.
우선 동질성 검정과 독립성 검정에는 '모집단'에 관하여 차이가 존재한다. 모집단 차이란 어떤 것을 의미하는 걸까? 먼저 동질성 검정을 실시하는 예시를 살펴보면서 이해해보자.
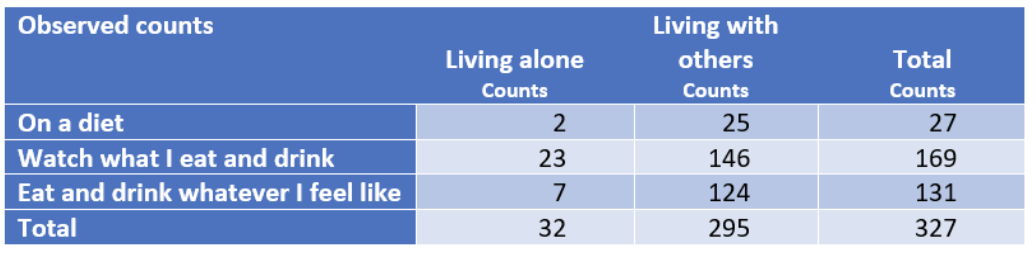
위 Pivot table 형태로 된 표는 식습관과 거주형태, 이 2가지 범주형 변수간의 빈도수를 나타낸 표이다. 여기서 식습관이라는 범주형 변수를 잠시 주목해보자. 식습관 범주형 변수의 level로는 다이어트 유형(On a diet), 자신이 먹고 마시는 것을 그래도 관리하고 신경쓰는 유형(Watch what I eat and drink), 먹고 싶은 것 다먹는 관리 안하는 유형(Eat and drink whatever I feel like) 총 3가지 이다.
이 때 이 3가지 유형의 집단(사람들)은 각각 독립적인 관계라는 점이 포인트다. 즉, 하나의 큰 모집단에서 실시한 것이 아닌 다이어트 식습관(On a diet)을 가진 하나의 집단에서 거주형태의 빈도수를 측정한 것이다. 그리고 다시 자신이 먹고 마시는 것을 그래도 관리하고 신경쓰는 유형(Watch what I eat and drink)을 가진 또 다른 하나의 집단에서 거주형태의 빈도수를 측정한 것이다. 나머지 먹고 싶은 것 다먹는 관리 안하는 유형(Eat and drink whatever I feel like)도 마찬가지이다.
이제 동질성 검정의 특징을 알아보았으니 위 테이블의 예시를 빌려 귀무가설과 대립가설에 대해 알아보자.
- 귀무가설 : 식습관 유형별로 거주형태 빈도 비율은 모두 동일하다. 즉, 차이가 없으며 관계가 없다.
- 대립가설: 식습관 유형별로 거주형태 빈도 비율에 차이가 존재한다. 즉, 두 변수간에 관계가 있다.
동질성 검정도 적합도 검정의 경우와 마찬가지로 검정통계량값이 나올 확률인 유의확률(P-value)를 구하여 유의수준 0.05보다 작으면 귀무가설을 기각하고 크다면 귀무가설을 채택한다.
3. 독립성 검정
다음은 독립성 검정이다. 독립성 검정은 동질성 검정과 달리 집단들 간에 독립적이지 않다. 다음 예시를 살펴보면서 자세히 이해해보자.

위 Pivot table은 소년과 소녀 즉, 성별에 따른 색깔 선호 빈도수를 나타낸 표이다. 여기서 성별(소년과 소녀) 변수에 주목해보자. 여기서 성별은 각각 개별적인 독립적인 집단에서 측정한 것이 아닌 하나의 모집단 즉, 소년+소녀로 이루어져 있는 모집단에서 성별에 따라 측정한 것이다. 따라서 이렇게 집단간의 관계가 독립적이지 않을 때 독립성 검정을 하는 것이다.
그렇다면 독립성 검정의 귀무가설과 대립가설에 대해서도 위 예시를 빌려 알아보자.
- 귀무가설: 성별과 선호하는 색깔간의 관계가 없다. 즉, 성별에 따라 선호하는 색깔 빈도 비율은 모두 동일하다
- 대립가설: 성별과 선호하는 색깔간의 관계가 존재한다. 즉, 성별에 따라 선호하는 색깔 빈도 비율이 차이가 존재한다.
독립성 검정 이전 검정방법들과 마찬가지로 검정통계량값이 나올 확률인 유의확률(P-value)를 구하여 유의수준 0.05보다 작으면 귀무가설을 기각하고 크다면 귀무가설을 채택한다.
'Data Science > Machine Learning' 카테고리의 다른 글
| [ML] Recurrent Neural Network(RNN) (0) | 2020.10.16 |
|---|---|
| [ML] Class imbalance 해결을 위한 다양한 Sampling 기법 (0) | 2020.09.20 |
| [ML] Multivariate regression(다변량 회귀분석) 프로세스 (0) | 2020.09.08 |
| [ML] Mean Shift, DBSCAN, and Silhouette metric (0) | 2020.08.14 |
| [ML] How to encode categorical variables (3) | 2020.07.19 |



