※해당 게시물에 사용된 일부 자료는 순천향대학교 빅데이터공학과 정영섭 교수님의 머신러닝 전공수업 자료에 기반하였음을 알려드립니다.
이번 포스팅에서는 저번 포스팅에서 다루었던 주제인 Perceptron(퍼셉트론)의 종류 중 다층 퍼셉트론(MLP=Multi-Layer Perceptron)이라고 할 수 있는 ANN(Artificial Neural Network)인 '인공신경망'에 대해 다룰 예정이다. 목차는 다음과 같다.
0. 왜 ANN과 딥러닝을 쓰는가?
1. ANN의 특성
2. ANN의 활성함수(Activation Function)
3. ANN의 학습
4. ANN의 Parameter Optimization(학습방법)
5. ANN 전처리(초기값 부여)
6. ANN의 Overfitting을 막기위한 방법
0. 왜 ANN과 딥러닝을 쓰는가?
그동안 다양한 머신러닝 모델에 관한 포스팅을 진행해왔다. 그런데 이러한 여러가지 머신러닝 모델을 납두고 굳이 ANN과 딥러닝을 쓰는 이유는 무엇일까? 이에 관한 답변은 가장 처음 포스팅했던 '머신러닝의 종류와 용어' 글에서 언급했었다. ANN이나 딥러닝을 사용하는 이유는 대표적으로 2가지 이다.
-
성능이 다른 머신러닝모델에 비해 정말 좋은 편이다.
-
Feature 정의가 필요하지 않다. 즉, 최적의 Feature를 모델이 알아서 찾아준다. 머신러닝은 우리가 Feature를 정의해야할 필요가 있고 가장 최적의 Feature를 정의해주려면 머신러닝 모델을 적용하려는 해당 분야의 도메인 전문지식이 갖추어져 있는 상태여야 가능할 것이다. 하지만 ANN, 딥러닝은 이러한 수고를 덜어준다. 다시 말해서, 딥러닝과 ANN은 추후에 이야기하겠지만 Weight와 Bias값을 알아서 학습하여 최적의 W,b값을 찾아준다.
1. ANN의 특성

위 그림을 참고하면서 ANN의 특성을 하나씩 알아가보자.
-
Feed-forwarding : 그림처럼 ANN모델은 왼쪽(input)에서 오른쪽(output)으로 한쪽 방향으로 흐름이 진행되는 특성을 갖고 있다.
-
'Input layer + 최소 1개이상의 hidden layer + output layer' 로 구성되어 있다. 이 때 hidden-layer가 많아질수록 'Deep'하다고 하며 결국 Deep하게 되면 우리가 흔히 알고 있는 '딥러닝' 모델이라고 부를 수 있다. 현재 이론상으로 hidden-layer이 많을수록 모델의 성능이 좋음을 가정하고 있다.
-
hidden-layer의 특징 : input값들을 집약해주는 역할을 한다. 이 hidden-layer이 많아지고 오른쪽으로(output쪽으로) 흐름이 진행될수록 더 고도화된 정보를 갖게 된다.(image로 치면 더 상위의 개념으로 가게 된다 ex. 선->도형->...)
-
Bi-partitie graph(이분 그래프) : 그림속 분홍색 선을 본다면 각 Layer들끼리 모두 연결(full-connected)되어있지만 같은 Layer의 노드(각 perceptron=neuron)끼리는 서로 독립적이다.
-
그림에서 각 Layer의 초록색으로 칠해진 동그라미 부분은 Bias값이다.

2. ANN의 활성함수(Activation function)
Perceptron 포스팅에서 배웠던 것처럼 input을 순입력함수로 집계한 후 그 값들을 활성함수에 넣게 된다. 그렇다면 활성함수에는 어떤 함수가 들어가야 할까? 단층 퍼셉트론에서는 선형문제를 해결할 수 있었다. 그렇다면 단층 퍼셉트론으로 비선형문제도 해결할 수 있을까? 결론은 "할 수 없다"이다. 왜냐하면 단층 퍼셉트론에서 만들어지는 선형함수를 아무리 합하더라도 여전히 선형함수이기 때문이다.
그렇다면 해결책은 무엇일까? 바로 활성함수에 '비선형 함수'를 넣어보는 것이다. 그럼으로써 우리는 비선형문제를 해결할 수 있다.

ANN의 활성함수는 hidden-layer과 ouput-layer에 각각 존재한다. 각 layer에 맞는 활성함수를 알아보자.
2-1. hidden-layer에서의 활성함수
hidden-layer에서 활성함수는 대표적으로 Sigmoid 함수를 사용한다. 왜냐하면 파라미터를 최적화하기 위해서는 활성함수가 미분이 가능해야 하기 때문이다.

위 그림의 왼쪽 함수는 미분이 불가능한 반면, 오른쪽의 시그모이드 함수는 미분이 가능하다.
2-2. output-layer에서의 활성함수
output-layer에서 사용하는 활성함수는 크게 3가지가 있으며 해결해야할 문제가 어떤 문제인지에 따라 다른 함수를 사용한다.
-
Identical function( f(x)=x ) : 수식 그대로 f(x)는 output, x는 hidden-layer에서 입력된 값이라고 생각하면 된다. 즉, hidden-layer에서 입력된 값을 아무런 변환(연산)을 거치지 않고 그대로 output으로 사용한다는 것을 의미한다. 이러한 활성함수는 보통 연속적인 값을 예측하는 Regression(회귀분석)에 사용된다.
-
Softmax function : 주로 Classification(분류)문제에 사용된다. ouput출력 값이 0과 1사이의 값이며 모든 output값들을 합하면 반드시 1이 된다. 즉, 출력을 확률값으로 대응할 수 있는 것이다. Softmax function은 특히 Multi-class Classification에 사용된다.(Multi-class Classification은 하나의 데이터가 반드시 하나의 Class(label)만 가져야 하는 분류모델이다.)
-
Sigmoid function : hidden-layer에서 주로 사용되는 활성함수로 Softmax function와 마찬가지로 Classification에 사용된다. 하지만 Softmax function과는 달리 하나의 데이터가 1개 이상의 Class(label)를 동시에 가질 수 있는 Multi-label Classfication에 사용된다.
output-layer에서 언제 Softmax function이 사용되고 언제 Sigmoid function이 사용되는지 차이점을 헷갈리지 말고 잘 알아두자.
3. ANN의 학습
다음은 ANN이 데이터를 입력하면서 학습해나가는 과정을 관찰해보자.

기본적으로 ANN의 학습 프로세스 그림은 위와 같고 input layer에서 바로 다음의 Layer로 넘어갈 때 Weight Matrix가 생기게 된다. 위 그림 속에서 각 Layer의 마지막 노드(동그라미 +1인 부분)는 Bias값이므로 Bias를 제외하고 input-layer과 그 다음의 Layer과의 Weight Matrix를 나타내면 밑의 그림과 같아진다.

참고로, input layer(그림 속 Layer L1) 다음의 Layer부터 각 Bias term을 알 수가 있는데 각 Layer의 Bias 노드갯수를 뺀 노드 갯수가 Bias term값이라고 생각하면 된다. 위 그림상에서 Layer L2은 Bias term이 3이되고 Layer L3와 Layer L4는 Bias term이 2가 된다.
이렇게 ANN은 지금까지 언급했던 과정을 거치면서 데이터를 학습해나가게 된다. 하지만 우리가 위에서 작성했던 Weight Matrix를 작성하기 위해서는 Layer들 간의 연결되는 노드 쌍 사이의 관계 정도를 알아야 하고 이를 알기 위해서는 co-occurence한 빈도수를 알아야 한다. 하지만 ANN은 hidden-layer에서 발생하는 일을 우리가 직접 눈으로 관찰할 수 없다. 그러므로 이를 해결하기 위해 Weight와 Bias값을 알아서 학습하는 알고리즘이 있어야 한다.
우선 일반적으로 다른 모델들이 파라미터를 최적화(모델이 학습)하는 방법을 관찰해보자.

위 그림을 천천히 읽어보면 마치 미지수가 2개로 이루어진 연립방정식이 있고 해가 주어진 상태에서 해결하는 것처럼 쉽게 파라미터값(미지수값)들을 알아낼 수 있다. 그렇다면 ANN도 이러한 학습방법이 통할까?
아쉽게도 ANN에서는 저런 학습방법으로 파라미터를 최적화할 수가 없다. 그래서 이러한 문제를 해결하기 위해 뛰어난 과학자, 수학자들이 고안해낸 방법은 역전파(Backpropagation)방법이다.
4. ANN의 Parameter Optimization(학습방법)
ANN은 파라미터를 최적화(Optimization)하기 위해서 역전파 방법을 쓴다고 했다. 역전파에 대한 정의부터 알아보자.
역전파란, 예측값과 실제값을 비교해 나온 차이(error=loss)의 크기에 따라 다시 input-layer 방향으로 역으로 파라미터를 최적화해주는 방법이다. 다음의 시각적 자료를 보면서 더욱 더 확실히 이해해보자.
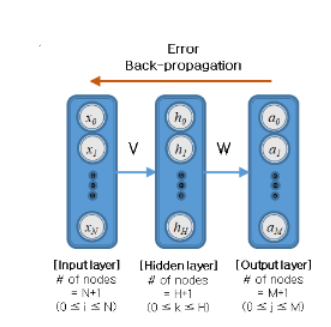
자, 우선 ANN모델이 train data로 output layer까지 우선 도달했다고 가정해보자. 그리고 output-layer에서 Error(실제값과 예측값과의 차이)와 Cost function을 얻었다. 이 때 Cost function의 종류로는 보통 MSE(Mean Squared Error)나 Cross-entropy를 사용한다. 이제 파라미터를 조정하기 위해서 역전파방법을 사용하기 시작한다. 가장 먼저 할 단계는 W라고 써져 있는 부분을 역전파하는 것인데, output-layer의 Cost function을 미분하면서 W에 대한 파라미터 업데이트 수식을 얻는 것이다. 그런 다음에는 V에 대한 파라미터 업데이트 수식을 구하기 위해서 ouput-layer의 Loss와 W파라미터에 기반한다.
하지만 hidden-layer가 너무 많아진다면 역전파 효과가 약해진다고 한다. 이러한 현상을 'Gradient Vanish' 라는 용어로도 불리운다.
#Cross-entropy는 MSE와는 달리 '정답'의 데이터에만 초점을 맞춘다. 즉, 정답이 아닌 label은 0을 곱함으로써 무조건 없어지게 만든다. 이에 대한 자료는 밑의 예시를 보면서 이해해보자.

방금까지 알아보았던 파라미터를 최적화하기 위한 ANN의 역전파 방법을 1. input-layer , output-layer만 있을 경우, 2.input-hidden-output layer이 있는 경우로 나누어서 필자의 필기 그림을 통해 자세히 살펴보자.
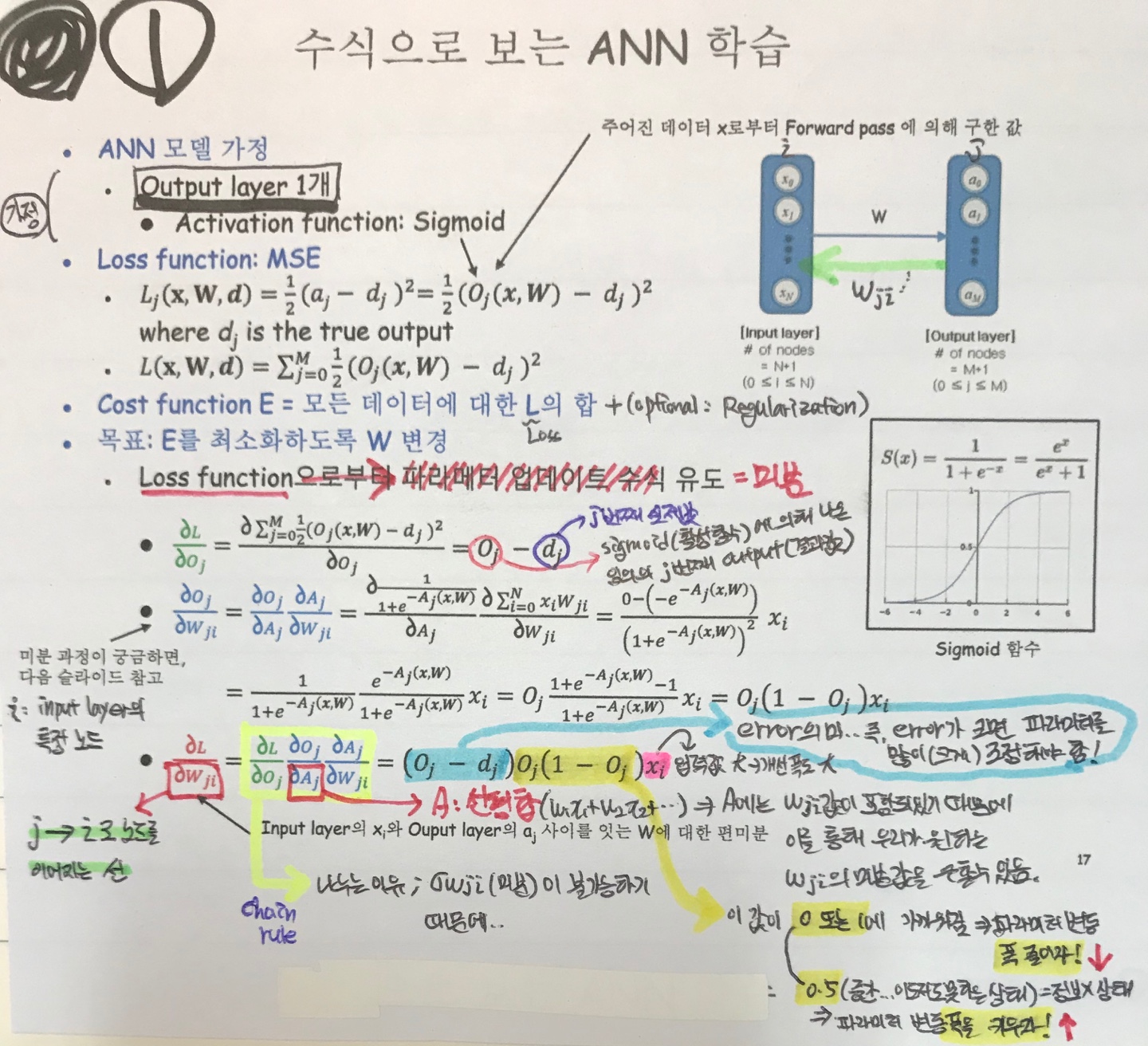
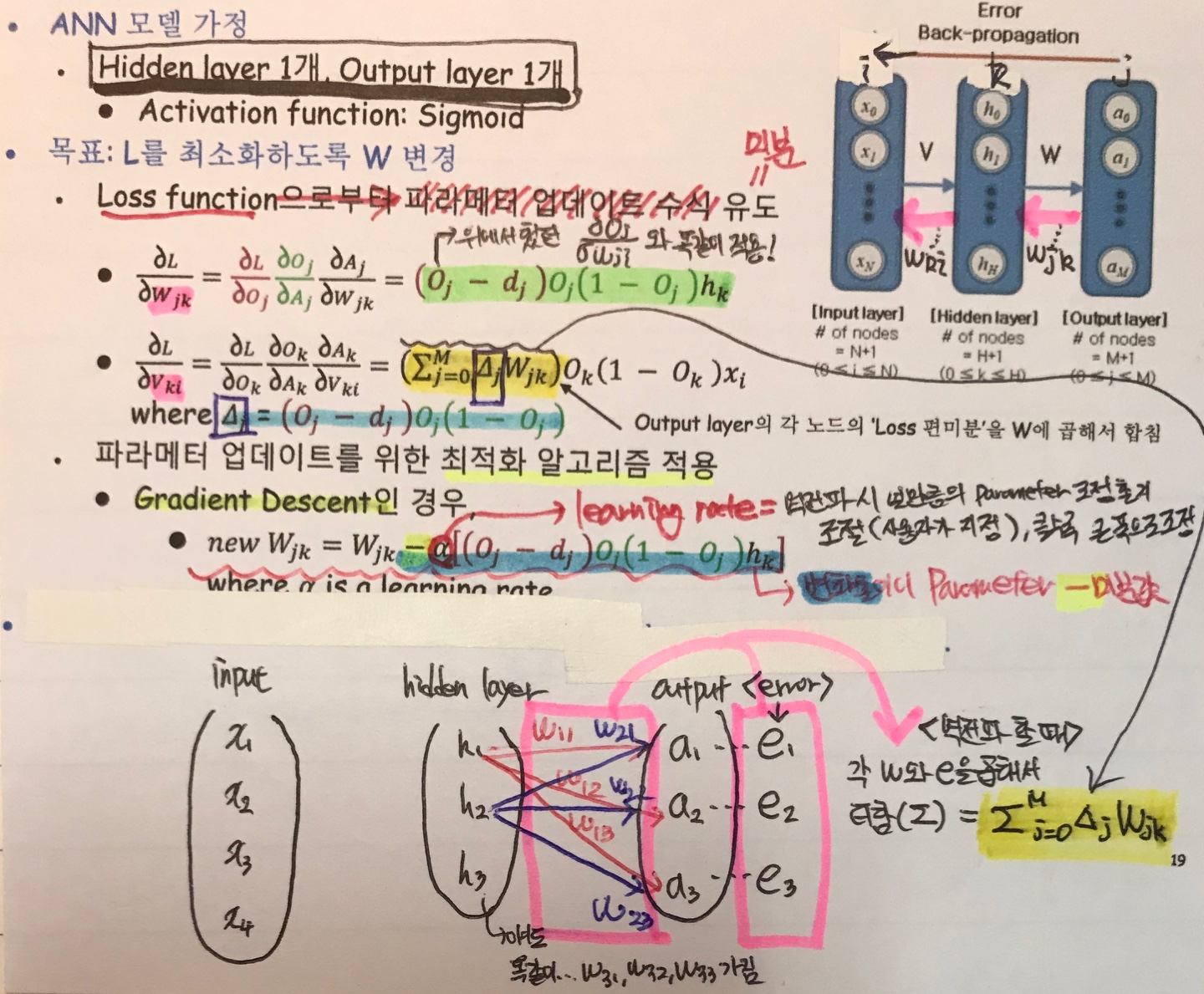
이렇게 역전파를 진행하면서 얻은 파라미터 업데이트 수식을 기반으로 해서 파라미터를 최적화하는 알고리즘이 여러가지 존재한다. 대표적인 방법으로는 이전에 Cost function을 최소화하는 방법으로 항상 사용해왔던 'Gradient Descent' 방법이다. 이 방법은 정말 머신러닝 포스팅의 여러부분에서도 언급했으므로 여기서는 따로 글로 설명하지 않으며 그림과 수식으로만 표현하겠다.
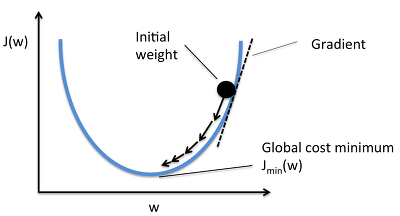
Gradient Descent방법을 사용하고 사용자가 임의로 정의해줄 수 있는(하이퍼파라미터) 학습률(learning rate)을 설정해주고 기존의 파라미터값에서 빼준다.

Gradient Descent(GD)방법에도 종류가 3개가 있는데 이에 대해 알아보자.
-
Batch GD : 학습 데이터가 N개 잇을 때, N개 전체에 대한 gradient를 적용하는 방법이다.
-
Stochastic GD : 학습 데이터 N개 각각에 대해 gradient를 적용하는 방법이다.
-
Mini-batch GD : 학습 데이터 N개를 작은 Mini-batch로 쪼개서 gradient를 적용하는 방법이다.
이 중에서는 주로 사용하는 최적화 알고리즘은 Mini-batch GD와 Adam's Optimizer이다.
참고로, Batch개수와 Learning rate를 헷갈릴 수도 있는데 두 개는 분명히 다르다는 것을 인지하자. Learning rate는 실제값과 예측값의 차이인 Error에 기반하여 역전파를 시행할 때 파라미터를 '얼만큼' 조정할 것인지에 대한 척도이다.
Adam's Optimizer에 대해서는 하단 링크에서 공부해보자.. 필자도 잠깐 내용을 봤지만 어려운 느낌이다...ㅜㅜ 우선 Adam Optimizer의 장점은 이렇다고 한다.
#Adam method의 의 주요 장점은 stepsize가 gradient의 rescaling에 영향 받지 않는다는 것이다. gradient가 커져도 stepsize는 bound되어 있어서 어떠한 objective function을 사용한다 하더라도 안정적으로 최적화를 위한 하강이 가능하다. 게다가 stepsize를 과거의 gradient 크기를 참고하여 adapted시킬 수 있다.
출처 : https://dalpo0814.tistory.com/29
Adam Optimizer 논문 요약/정리
Adam Optimization 논문 요약/정리 Adam Optimization 논문 요약/정리 우와… 좀더 쉽게 티스토리에 포스팅을 하기 위해 귀찮지만 노력을 들여서 evernote와 marxico, markdown의 세계에 입문하였다. 근데 marxico..
dalpo0814.tistory.com
5. ANN 전처리(초기값 부여)
ANN 전처리란, ANN 모델에 input으로 들어갈 데이터 입력의 초기값을 어떻게 설정할지에 대한 문제이다. 우선 데이터의 각 Feature를 Scaling하는 방법이있는데, Scaling하는 방법으로서는 0~1로 변환하는 정규화(Normalization), 정규분포로 변환하는 표준화(Standardization) 방법이 존재한다.
다음은 파라미터의 초기값을 설정하는 방법이다.
#활성함수가 Sigmoid function일 경우, 초기 파라미터값들이 평균이 0이고 표준편차가 1이라면 결과값들이 0과 1에 치우친 현상이 발생해 Gradient가 0이 되며 결국 'Gradient Vanish' 문제가 발생한다.
-
0으로 초기화하는 방법이다. 하지만 역전파 사용시 모두 같은 양만큼 gradient를 계산하는 문제가 발생한다.
-
정규분포로 변환한다. 하지만 표준편차가 너무 작아지거나 커진다면 활성함수(Activation)값의 편차가 작아지면서 Weight값이 작아지고 결국 활성함수(Activation)이 사라지는 현상이 발생한다.
-
Layer, 노드 개수를 고려하는 Xaiver 초기화 방법이 있다. 하지만 활성함수 종류에 따라 성능 차이가 심하며 ReLU함수의 경우 출력값이 0으로 수렴, 평균과 표준편차가 0으로 수렴함으로써 Gradient Vanish문제가 발생한다.
-
He 초기화 방법 : Xaiver 초기화방법과 비슷하지만 input개수의 절반의 제곱근으로 나누어준다는 차이점이 있다. He방법은 ReLU함수도 적용이 된다. 현재 가장 많이 쓰이는 방법이다.
따라서 Sigmoid함수를 사용할 때는 Xaiver 초기화 방법을 쓰며 ReLU함수 사용의 경우에는 He 초기화 방법을 사용하면 Gradient Vanish 문제를 방지할 수 있을 것이다.
6. ANN Overfitting을 막기 위한 방법
ANN도 Overfitting(과적합)이 발생한다. 이를 막기 위해서는 크게 4가지 방법이 존재한다.
-
데이터 개수 늘리기
-
모델 복잡도(Complexity) 줄이기. 즉, 노드의 개수나 Layer의 개수 줄이기
-
Regularization(정규화=일반화) 시키기. ex) L2 norm, L1 norm, Maximum norm
-
Hyperparameter(사람이 사전에 정의할 수 있는 값 ex.노드개수, 층개수, 학습률)를 결정함으로써 모델 복잡도를 설정. 적절하게 설정하면 Overfitting 방지할 수 있다. 그렇다면 어떻게 적절한 하이퍼파라미터값을 찾을까?
-
Grid-search : 처음부터 끝까지 다 해보는 방법
-
Random search : 랜덤으로 설정하는 방법
-
NAS(Neural Architecture Search) : 하이퍼파라미터 조차도 모델 스스로 설정하는 방법. 이에 대한 방법은 연구가 진행중이라고 한다.
-
- 너무 많은 Epoch 시행도 Overfitting 발생을 시킬 수도 있기 때문에 Epoch 시행이 많다면 줄여주는 것도 하나의 해결책이 된다.
#더 공부하기
1) Learning rate decay : 하이퍼파라미터 중 하나로 설정하는 Learning rate(학습률)을 처음에는 높게 잡다가 점차 학습이 진행될수록 학습률을 낮게 설정하는 것을 의미한다.
2) Weight decay : W,b (파라미터)값들을 최적화하는 알고리즘을 사용할 때 Regularization(예를들어, L2 norm, L1 norm)방법을 사용해 파라미터값들이 커지는 것을 제한함을 의미한다.
3) Incremental Learning : Online Learning이라고도 불리며 데이터를 추가로 학습시킬 때 기존에 학습시킨 데이터에 추가 데이터만 학습시키는 방식이다. 단, Incremental Learning이 적용이 안되는 머신러닝 모델도 있지만 ANN은 가능하다.
(참고로 Incremental Learning에 대한 주제는 이전 포스팅에서 다루었었다. 자세히 알고싶다면?
https://techblog-history-younghunjo1.tistory.com/35?category=863123)
4) Transfer Learning : Incremental Learning이 가능함으로써 적용할 수 있는 학습 방법이다. 새로운 모델을 만들 때 기존 모델과의 성격(?)이 비슷하다면 새로운 모델을 학습할 때 기존 모델에서 학습했던 지식을 사용하는 방법이다.
5) Early Stopping : ANN의 역전파 방법을 사용해 파라미터 값을 최적화할 때 Epoch를 시행하면서 일정 Cost값 보다 낮아지면(임의의 Cost값 threshold(임계치)를 설정) 또는 이전보다 Cost값이 갑자기 증가하는 순간 Epoch 시행을 멈추는 것을 의미한다.
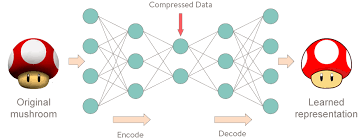
6) Auto Encoder : input 값과 output 값이 같다. 따라서 label이 필요가 없기에 Unsupervised learning에 속한다. 밑의 그림에서 가운데 layer은 input 차원을 축소시키고 다시 output에 출력할 때 차원을 확장시킨다. Auto Encoder의 용도로는 이미지 데이터를 압축하거나 딥러닝에서 입력 벡터 차원을 축소, 은닉층의 학습에 사용된다.
'Data Science > Machine Learning' 카테고리의 다른 글
| [ML] SVM(Support Vector Machine)서포트 벡터 머신 (0) | 2020.05.26 |
|---|---|
| [ML] Class imbalance(클래스 불균형)이란? (2) | 2020.05.13 |
| [ML] Perceptron(퍼셉트론)의 이해와 종류 (0) | 2020.05.08 |
| [ML] 데이터 학습방법으로서 MLE, MAP (0) | 2020.04.29 |
| [ML] PCA(주성분분석), SVD, LDA by Fisher (0) | 2020.04.25 |



