이번 포스팅에서는 저번 시간에 계속적으로 배웠던 '가우스 소거법(Gauss Elimination)' (줄여서 'GE'라고 부르기도 한다.)에서 이끌어낼 수 있는 LU 분할에 대해서 알아보려고 한다. 기본적으로 가우스 소거법의 계산과정을 알아야 LU분할이라는 개념이 이해가 되기 때문에 가우스 소거법을 모른다면 이전 포스팅을 참고하자.
(가우스 소거법을 알고 싶다면? https://techblog-history-younghunjo1.tistory.com/67)
앞으로 소개할 목차는 다음과 같다.
1. LU Decomposition (LU분할)
2. Triangular Factors
3. Pivoting을 고려한 LU분할
1. LU Decomposition
사람에 따라 LU Factorization이라고도 부르기도 한다. LU분할 개념에 대해서 말로 설명할 수 없는 부분이라고 생각해서 이전에 가우스 소거법 포스팅에서 들었던 똑같은 3개 미지수(변수)에 대한 연립방정식의 예시를 들면서 살펴보자.

먼저 왼쪽 위의 RAW라고 된 부분 처럼 3개의 연립방정식이 존재한다. 각 식을 1,2,3번의 식이라고 정의해두고 이전에 배웠던 가우스 소거법을 통해 [ 2번식 - (1번식*2) ] 를 해주어 미지수 u에 대한 계수를 0으로 만들어 주었다. 우리는 이를 행렬을 통해서 표현할 수 있다. 즉, 어떤 행렬(E21 이라고 적혀있는 행렬)를 주어진 행렬(RAW를 A행렬이라고 하자.) A에다가 곱했을 때 나오는 값이 가우스 소거법을 통해서 나오게 되는 행렬과 똑같아 진다.
이 때 우리는 어떤 행렬(E21)을 구하게 된다. 그리고 E21이라고 표현한 이유는 1번식을 이용해 2번식을 계산하는 행렬이기 때문이다. 똑같은 과정을 거쳐 1번식을 이용해 3번식을 계산하는 E31 행렬을 구해준다.
그리고 미지수 v를 소거해주기 위해서 2번식을 이용해 3번식을 계산하는 E32행렬에 방금 전에 구했던 'E31*E21*A' 행렬을 곱해주어 구해주게 된다. 그러면 우리가 본질적으로 구하려고 했던 U(Upper triangular Matrix)가 나오게 되며 미지수의 값들을 구할 수 있게 된다.
또 하나 우리가 눈여겨보야할 점은 우리가 그동안 구했던 E라는 행렬에 대한 것이다. E는 Elementary Matrix의 E를 의미한다.(고등학교 시절 배웠던 항등원 행렬 E는 선형대수에서는 I라고 나타낸다. 이전 포스팅에서도 언급했다.) 밑의 그림을 보자.

우리가 구했던 E32, E31, E21을 일반화시키게 되면 노란색으로 칠해진 요소가 속해있는 행렬처럼 나타낼 수 있다. 또한 모든 E 행렬(Elementary Matirx)의 역행렬을 구할 수 있다. 예를들어 이전에 수행했던 가우스 소거법 계산과정에서 2번식을 계산하기 위해 1번식에 특정 실수값을 곱했을 때의 그 실수값의 부호만 바꾸어서 취해주면 되는 것이다.(초록색으로 칠해져있는 요소가 들어있는 행렬 참고)
따라서 우리는 위와 같이 E 행렬의 역행렬을 구할 수 있게 됬고 이제 기존에 주어진 A라는 행렬을 여러 E 행렬들의 역행렬들과 U(Upper triangular Matrix)의 곱으로 나타낼 수 있다. 그리고 여러 E 행렬들의 역행렬들끼리만 연산하게 되면 파란색으로 세모를 그린 부분의 행렬이 나오게 된다. 우리는 그러한 행렬을 대각 행렬 1을 기준으로 밑에가 0이 아닌 부분이라고 해서 Lower Triangular Matrix 라고 부르게 되며 결국 행렬 A = LU 로 분할을 할 수 있게 된다.
2. Triangular Factors
Traingular Factors는 삼각형 인수라고 할 수 있다. 즉, 여기서는 우리가 앞에서 구했던 LU 행렬의 형태가 Triangular Factors라고 할 수 있다. 우리는 A라는 연립방정식에서 x라는 미지수(앞의 예시에서 u,v,w 값들)를 곱했을 때 새로운 실수 b가 나온다는 것을 보았다. 이 때 A라는 행렬은 LU분할을 취해줄 수 있다.
그렇다면 이러한 LU 분할은 대체 무슨의미를 갖는걸까? 시스템에서 예시를 들어보자. 밑의 그림과 같이 A라는 시스템이 존재한다. 우리는 A라는 시스템에 미지수 u,v,w를 input으로 넣어주고 b1,b2,b3라는 결과값을 얻게 된다. b1,b2,b3라는 결과값을 얻게 해주는 것은 바로 u,v,w의 계수가 파라미터 역할을 해주는 것이다. 그런데 이러한 파라미터의 최적의 값을 찾아주기 위해서는 LU 분할을 이용하는 것이다.

따라서 우리는 A라는 시스템을 A자체로 설계하는 것이 아닌 LU분할로 나누어 설계하는게 좋다.
그리고 Diagonal Matrix 에 대해서 잠시 알아보자. 기본적으로 정의는 대각행렬이라는 뜻이며 대각행렬은 기본적으로 대각 행렬의 값 빼고 나머지 값들은 모두 0이다. 밑의 그림을 살펴보자.
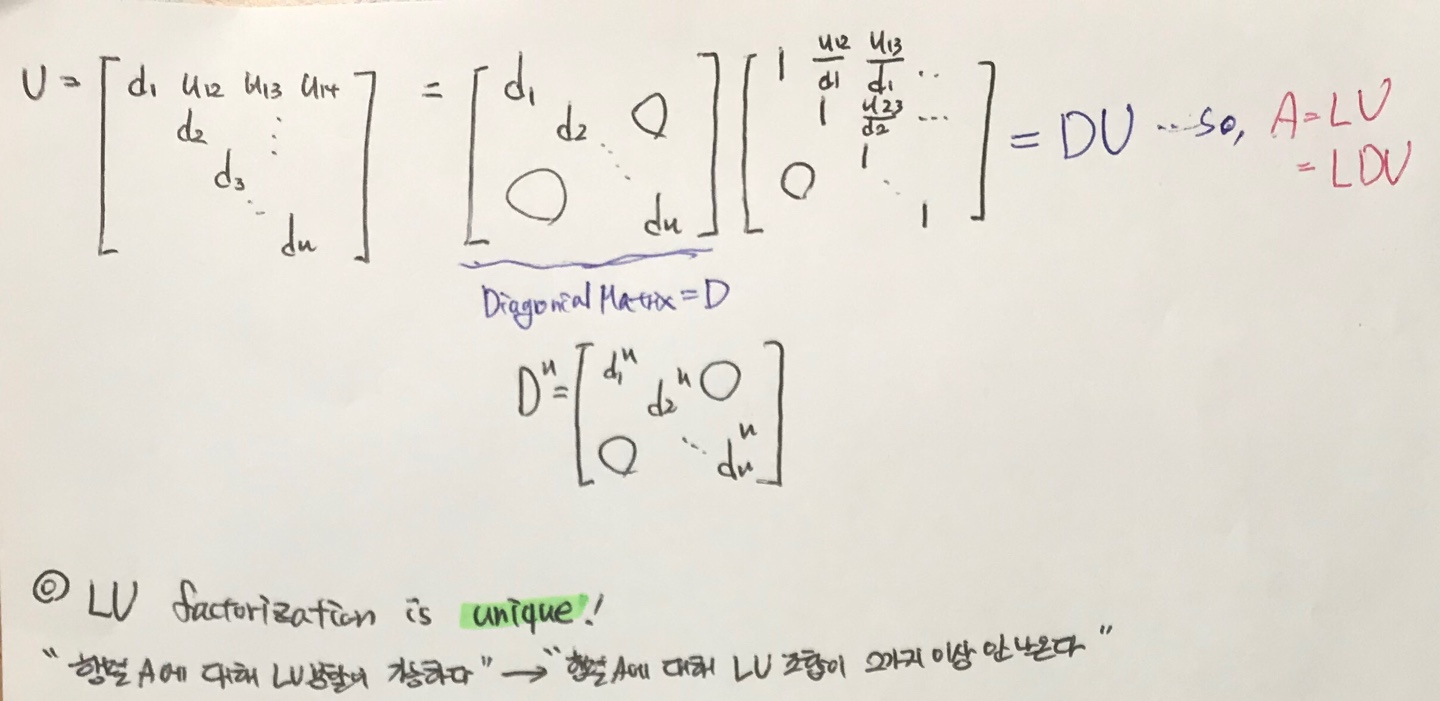
Upper Martix인 U 행렬이 다음과 같이 주어졌다고 가정하자. 이는 우리가 대각행렬(Diagonal Matrix)를 이용해서 풀어줄 수가 있게 된다. 따라서 U행렬은 D(대각행렬)과 또 하나의 Upper Matrix(대각행렬이 1인 U와 대각행렬인 d1~dn인 행렬과는 다른 U이다.) 와의 곱으로 나타내줄 수 있고 결국 A = LDU 라는 식이 도출되게 된다.
또한 임의의 행렬 A가 LU분할이 가능하다는 것은 행렬 A에 대한 LU분할 조합이 2가지 이상이 아닌 unique하다는 것을 의미한다.
3. Pivoting을 고려한 LU분할
지금까지 우리는 Pivoting을 고려하지 않은 상태로 계산해왔다. Pivoting이란 미지수를 소거하기 위해서 연립방정식의 순서를 올바르게 바꿔주는 것을 말한다.
#Pivoting 개념에 대해서 자세하게 알고 싶다면? : https://techblog-history-younghunjo1.tistory.com/67

여기서 등장하는 또하나의 개념 Permutation Matrix 라는 'P' 행렬이다. P 행렬은 항등원 행렬인 'I'행렬과 같은 열들을 가지며 1의 값이 열과 행에 1번씩은 무조건 나오게 된다. 위의 예시 속 P21이라는 것은 2번,1번 연립방정식의 나열 위치를 서로 바꾼 것을 의미한다.
'P'행렬의 중요한 특징은 "P행렬의 역행렬 = P행렬의 Transpose 행렬" 이 같다는 것이다. 따라서 이로 인해 우리는 Pivoting을 고려했을 때 A = P^T*L*U 가 되게 된다.(단, P행렬의 교환법칙은 성립하지 않는다.)
# P^T : P행렬의 Transpose 행렬
'Data Science > 선형대수' 카테고리의 다른 글
| 영벡터공간(Null Space)과 해집합 (0) | 2020.05.19 |
|---|---|
| 벡터공간(Vector space)과 열벡터공간 (0) | 2020.05.18 |
| Inverse Matrix(역행렬)&Transpose Matrix(전치행렬) (0) | 2020.05.17 |
| 1차 연립방정식과 가우스 소거법(Gauss Elimination) (0) | 2020.04.26 |
| 선형성(Linearity) 정의 및 1차연립방정식의 의미 (0) | 2020.04.25 |



