🔊 해당 포스팅은 인프런의 널널한 개발자님의 독하게 시작하는 C 프로그래밍 강의를 듣고 개인적인 복습 목적 하에 작성된 글입니다. 해당 포스팅에 사용된 모든 자료는 필자가 직접 재구성하였음을 알립니다.

이번 포스팅에서는 C언어에서의 파일 입/출력에 대해 배워보도록 하자. C언어 포스팅 시리즈에서 초반에 문자열 입/출력을 다룬 적이 있었다. 하지만 그 이후로 학습을 진행하면서는 모두 주기억장치인 RAM, 엄밀히 말하면 각 프로세스 당 부여되는 가상 메모리를 다루는 것이었다. 이제는 주기억장치와는 다르게 컴퓨터 전원을 꺼도 휘발되지 않는 보조기억장치인 SSD, HDD에서 데이터를 읽고 쓰는 파일 입/출력에 대해서 배워보도록 하자.
참고로 RAM을 이용할 때의 데이터는 우리가 메모리를 동적할당할 때나 소스코드에서 미리 메모리 크기를 정의하는 식으로 데이터를 생성하기 전에 그 데이터가 담기는 크기를 미리 정했지만, 파일의 경우는 데이터가 생성된 뒤에 크기가 정해진다라는 차이점에 대해서도 알아두자.
1. 파일 입/출력의 주체는 프로세스(Prcocess)
파일을 입력, 출력하는 대표적인 예시를 들어보자. Python을 이용해서 csv 파일을 읽을 수 있다. '읽다' 는 곧 '입력'인 셈이다. 아니면 이전 포스팅에서 알아본 C언어로 짠 프로그램을 활용해서 키보드 입력을 받고, 그 입력을 받은 것을 콘솔에 출력시킬 수도 있다.
그러면 이렇게 파일을 입력 또는 출력하는 주체는 누구일까? 바로 프로세스이다. 앞서 들었던 예시로 다시 비유를 들자면, csv 파일을 읽어들이는 주체는 Python 프로그램이 실행되고 있는 프로세스이다. 또, 키보드로 입력을 받고, 출력시키는 주체는 C언어로 짠 프로그램이 실행되고 있는 프로세스다. 결국, 어떤 입력을 받거나 또는 어떤 출력을 내뱉는 것의 주체는 모두 프로세스가 된다.
그런데 만약 여러 개의 프로세스가 하나의 파일에 동시에 접근하게 되면 어떻게 될까? 예를 들어, A, B라는 2개의 프로세스가 있고 F.txt 라는 파일이 있다고 가정해보자. A 프로세스는 F.txt 파일에 어떤 내용을 수정하는 로직이 존재하고, B 프로세스는 F.txt 파일의 내용을 읽어들이는 로직이 존재한다. 이럴 경우, A, B 프로세스가 동시에 실행된다면 F.txt 파일의 내용은 꼬일 수 있는 가능성이 존재한다.

F.txt 파일을 읽는 B 프로세스 입장에서는 A 프로세스가 F.txt 파일에 수정한(write한) 내용이 반영되기 전인 원본을 원한다라고 한다면 B 프로세스는 의도치 않게 수정된 F.txt 파일의 내용을 얻게 될 것이다.
그래서 이러한 문제점을 막기 위해서 기본적으로는 OS가 파일에 대한 프로세스 접근을 배타적으로 통제한다. 배타적으로 통제한다라는 것의 의미는 "특정 파일에 대한 접근 권한을 하나의 프로세스만 허용한다"이다. 여기서 '파일에 대한 접근 권한'이라고 한다면 파일을 읽기(r), 쓰기(w), 실행(x)하는 권한을 의미한다.
이번에는 여기서 '파일' 이라고 부르는 것에 대한 종류에 대해서 알아볼 차례다. 여기서 '파일'이란 무엇을 의미할까? 보통 우리가 흔히 알고 있는 파일이라고 하면 확장자가 .txt 인 텍스트 파일, csv 파일, 엑셀 파일, C언어와 같은 프로그래밍 언어로 작성된 소스코드 파일 등이 있다. 여기서는 이러한 종류로 구분하기 보다는 "장치를 추상화한 파일" 과 "데이터가 담긴 파일"로 구분할 수 있다. 방금 언급한 csv 파일, 텍스트 파일 같은 것들은 "데이터가 담긴 파일"로 분류될 수 있다. 말 그대로 csv 파일 또는 텍스트 파일 내에 '데이터'가 존재하기 때문이다.

그러면 대체 '장치를 추상화한 파일'은 무엇일까? 이를 알아보기 위해서 이전에 실습해보았던 "키보드 입력을 통한 콘솔 프로그램 출력" 이라는 예시를 들어보자.

위 그림처럼 사람이 키보드를 통해 어떤 입력을 시킨다. 그리고 그 입력을 받은 콘솔 프로그램은 그대로 콘솔 화면에 출력을 표시한다. 여기서 '콘솔'은 일종의 장치이다. 우리가 보는 이른바 터미널 화면이라고 하는 것은 '콘솔 화면'이다. 위 과정을 컴퓨터의 3단계 구조로 표시하면 아래와 같다.
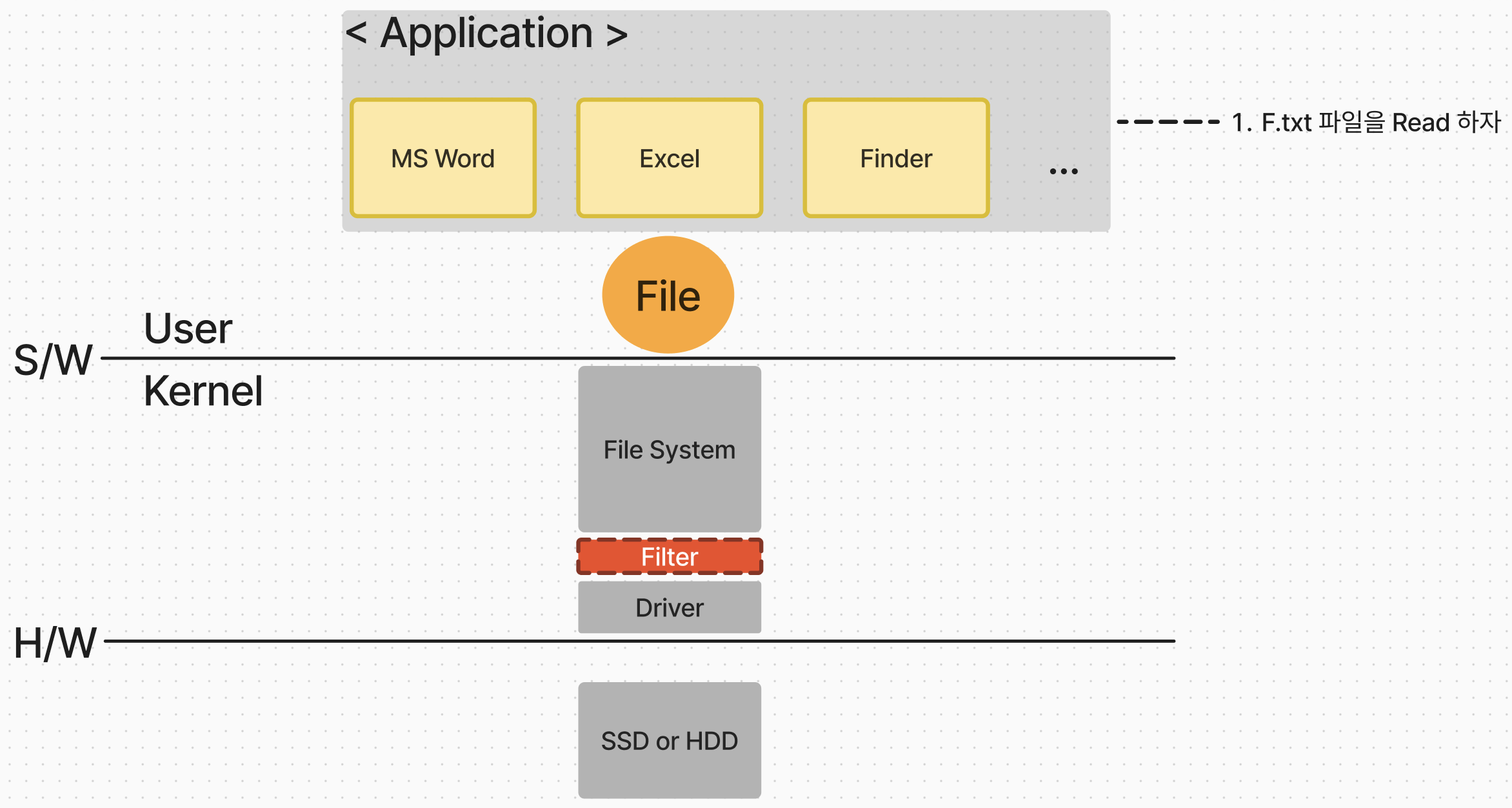
먼저 위 그림의 각 요소에 대해서 알아보자. 현재 우리는 보조기억 장치를 설명하고 있기 때문에 하드웨어 장치는 SSD 또는 HDD 장치가 된다. 그리고 이 장치와 상호작용을 하기 위한 어떤 Driver가 존재할 것이다. 그리고 그 위에 파일 시스템이 존재한다.
참고로 파일 시스템과 Driver 사이에 Filter 작용을 하는 프로그램이 존재하는데, 말 그대로 '필터' 즉, 어떤 파일을 버리고 어떤 파일은 통과시키는 역할을 한다. 여기서 어떤 기준으로 필터를 하냐라고 한다면 특정 파일이 악성 코드에 감염되지는 않았는지 필터링을 수행한다. 필자와 같은 세대(9x년대생..)의 어릴적에 사용하던 윈도우 컴퓨터에는 대부분 안랩에서 개발한 V3 백신 프로그램을 설치했을텐데, 이 V3 백신 프로그램이 바로 필터링 역할을 하는 프로그램이다.
이제 다시 돌아와서 상황을 설명해보자. 현재 여러 애플리케이션이 실행되고 있다. 그 중에 MS Word 프로그램을 실행시키고 있는 프로세스가 파일 시스템 내에 존재하는 F.txt 라는 텍스트 파일을 읽어들이고 싶어한다. 하지만 OS의 User 모드에서 실행시킬 MS Word 프로그램은 직접적으로 Kernel 모드에 존재하는 파일 시스템에 접근하지 못한다.
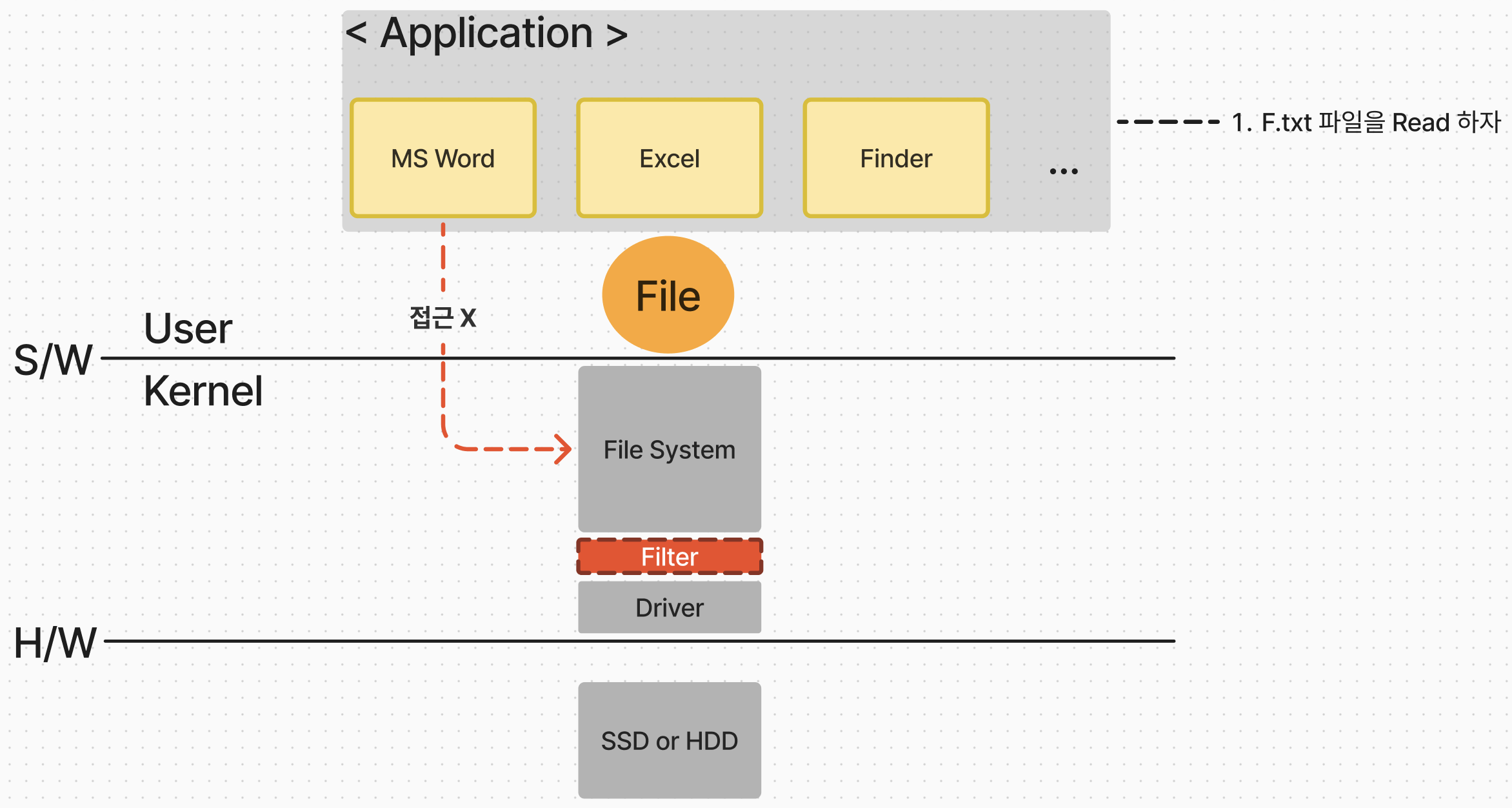
그러면 어떻게 애플리케이션은 파일 시스템에 접근할까? 이 때 바로 File(파일)이라는 인터페이스를 통해서 파일 시스템에 접근이 가능해진다.
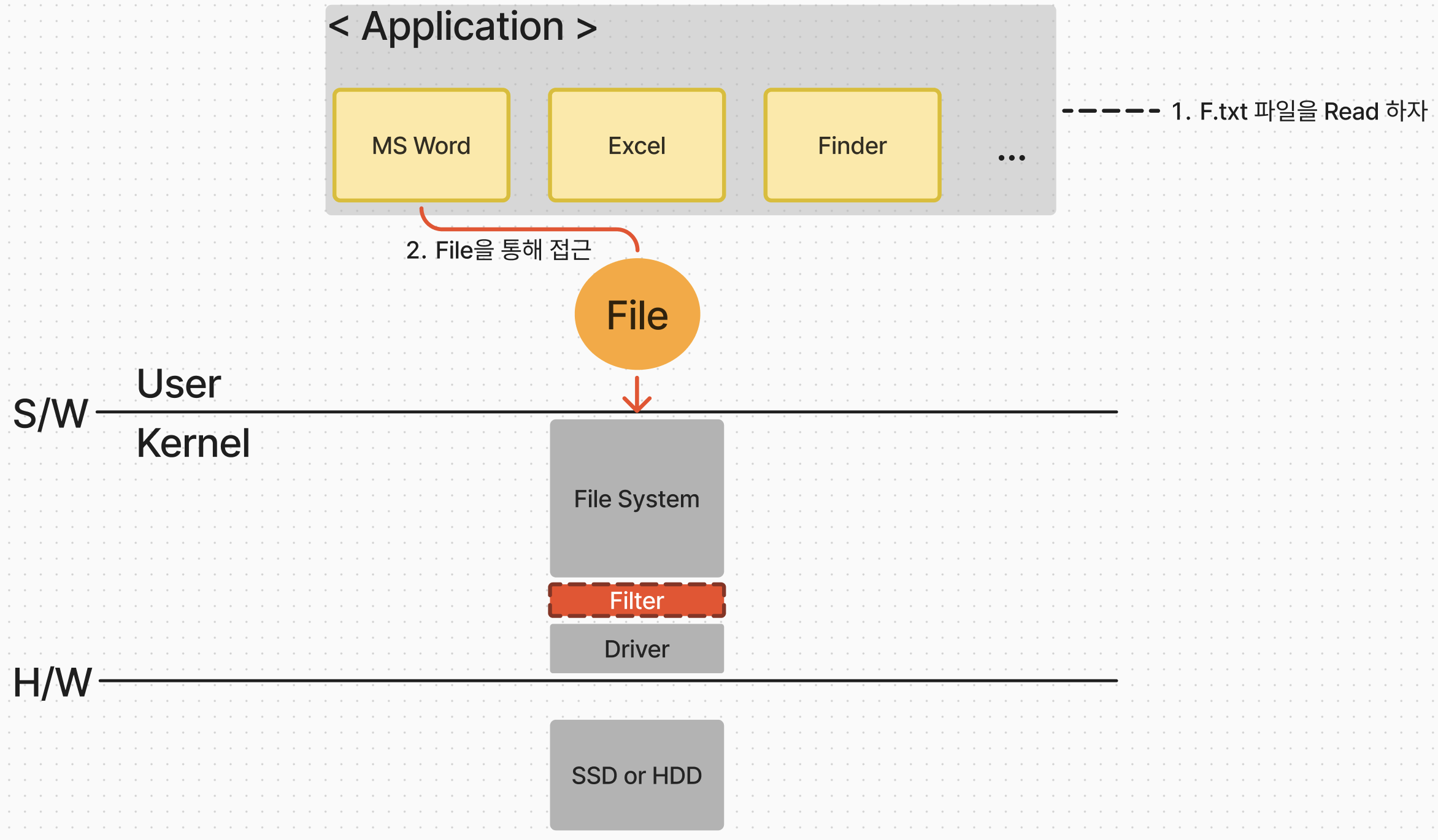
위와 같은 경우에 사용되는 파일을 바로 "장치를 추상화한 파일" 이라고 부른다. 그리고 우리는 예시를 콘솔 프로그램의 입/출력 예시를 들었으므로, 여기에서의 파일은 "콘솔 장치를 추상화한 파일"이라고 하는 것이다.
2. 비트 스트림과 파일 스트림
다음으로 알아볼 내용은 파일 스트림(File Stream)이다. 우선 '스트림'이라는 것이 무엇인지 개념적으로 짚고 넘어가보자. 스트림이라는 용어는 현대인에게 익숙한 개념이다. 유투브에서 라이브를 진행하는 유투버의 영상을 보고 있는 것을 라이브 스트리밍이라고 한다. 또 넷플릭스나 쿠팡 플레이와 같은 OTT 서비스에서 영상을 보는 것을 비디오 스트리밍이라고 한다. 이렇게 스트림이라는 용어는 우리 주변에서 흔히 접할 수 있는 개념이다. 이러한 스트림이라는 개념을 텍스트로 특징화시킨 다면 2가지 특성을 갖는다.
첫 번째는 1차원의 선형적인 구조를 갖는다는 점, 두 번째는 빈틈없이 연속적이라는 점이다. 다시 넷플릭스로 비유를 들어보자. 넷플릭스에서 보여주는 동영상은 엄밀히 말하면 수많은 사진이 연속으로 이어붙힌 것을 순차대로 보여주는 것과 같다. 즉, 사진이라는 어떤 단위가 끊이지 않고 연속적으로 나오는 것을 의미한다.
이제 스트림이라는 개념에 대해 알아보았으니, 비트 스트림에 대해서 알아보자. 여기서 비트는 우리가 이전에 배웠던 값이 1 또는 0으로 이루어진 bit를 의미한다. 그리고 이러한 비트가 계속 끊임없이 등장하는 것을 의미한다.
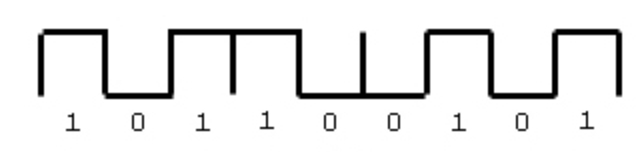
그러면 파일 스트림은 무엇일까? 말 그대로 파일이 '어떤 단위'로 하여 끊이지 않고 연속적으로 나오는 것을 의미한다. 그런데 파일은 사실 수많은 바이트(byte)로 구성되어 있다. 흔히 우리는 "이 파일의 용량은 몇 킬로바이트야 또는 몇 메가 바이트야" 라고 말하는 문장 안에는 파일이라는 것이 바이트로 구성되어 있다는 사실이 전제되어 있는 셈이다.

그런데 1 바이트는 8비트이라는 사실은 우리는 알고 있다. 그렇다면 바이트는 비트로 구성된다. 따라서 결국에는 파일 스트림은 비트 스트림인 셈이 된다.

참고로 우리가 문자열 입/출력 포스팅에서 배웠던 Buffered I/O도 비트 스트림으로 구현되어 있다는 점도 알아두자.
3. 텍스트 파일과 바이너리 파일
1번 목차에서 파일의 종류를 소개할 때, "데이터가 담겨 있는 파일" 과 "장치를 추상화시킨 파일" 두 종류로 나뉜다라고 했다. 이번에는 파일을 다른 관점으로 두 가지로 나눌 수 있다. 파일에 담긴 내용이 어떤 형태로 되어있는지를 기준으로 분류할 수 있는데, 텍스트 파일과 바이너리 파일이다. 텍스트 파일은 '문자열로 해석이 가능한 바이너리만 담겨 있는 파일'을 의미한다. 결국, 두 개념 간의 관계는 아래처럼 도식화할 수 있다.
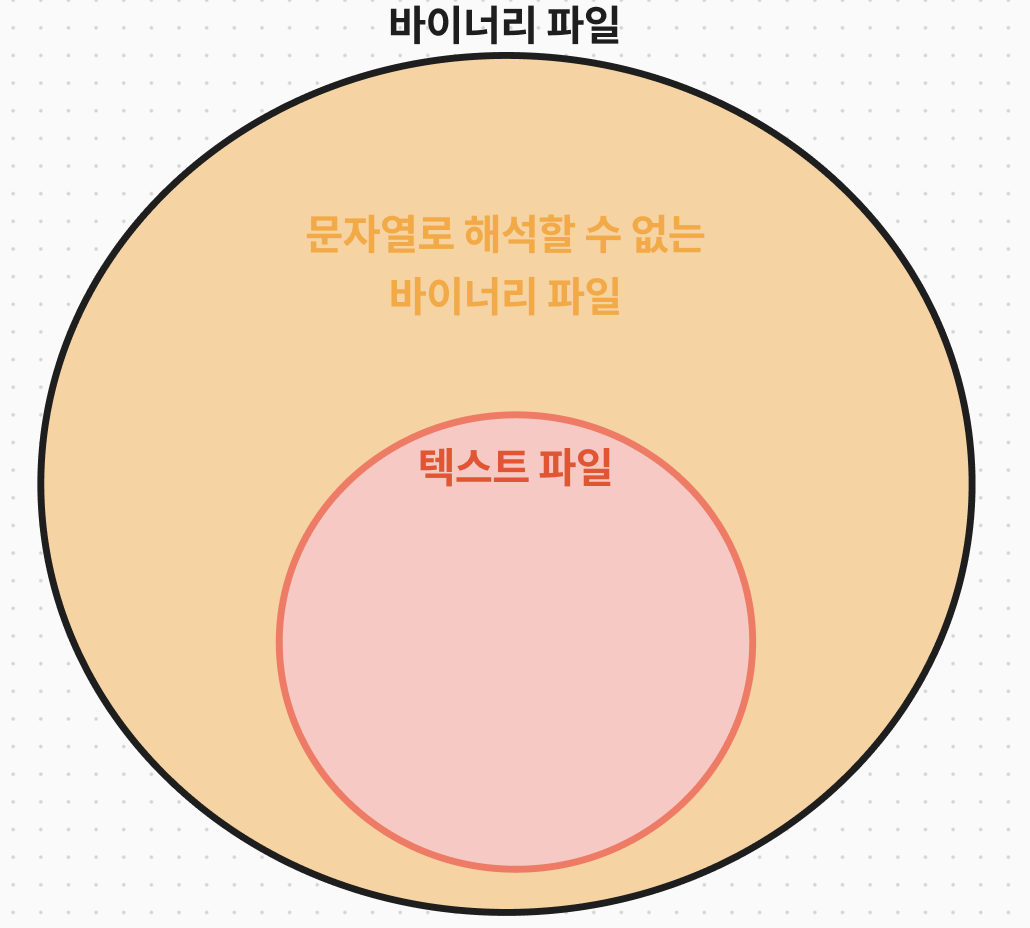
4. 파일 생성, 개방, 폐쇄
이번 목차부터 실전적으로 C언어에서 파일을 입/출력해보는 방법에 대해서 알아보도록 하자. C언어에서는 어떤 파일을 생성 또는 개방할 때 fopen() 이라는 함수를 사용한다. 그런데, 소스코드를 보기 전에 fopen() 함수에서 '접근 모드' 라는 것을 인자로 넣어주어야 하는데, 이 접근 모드의 종류를 의미하는 문자가 여러가지 존재한다. 아래 표를 보자.
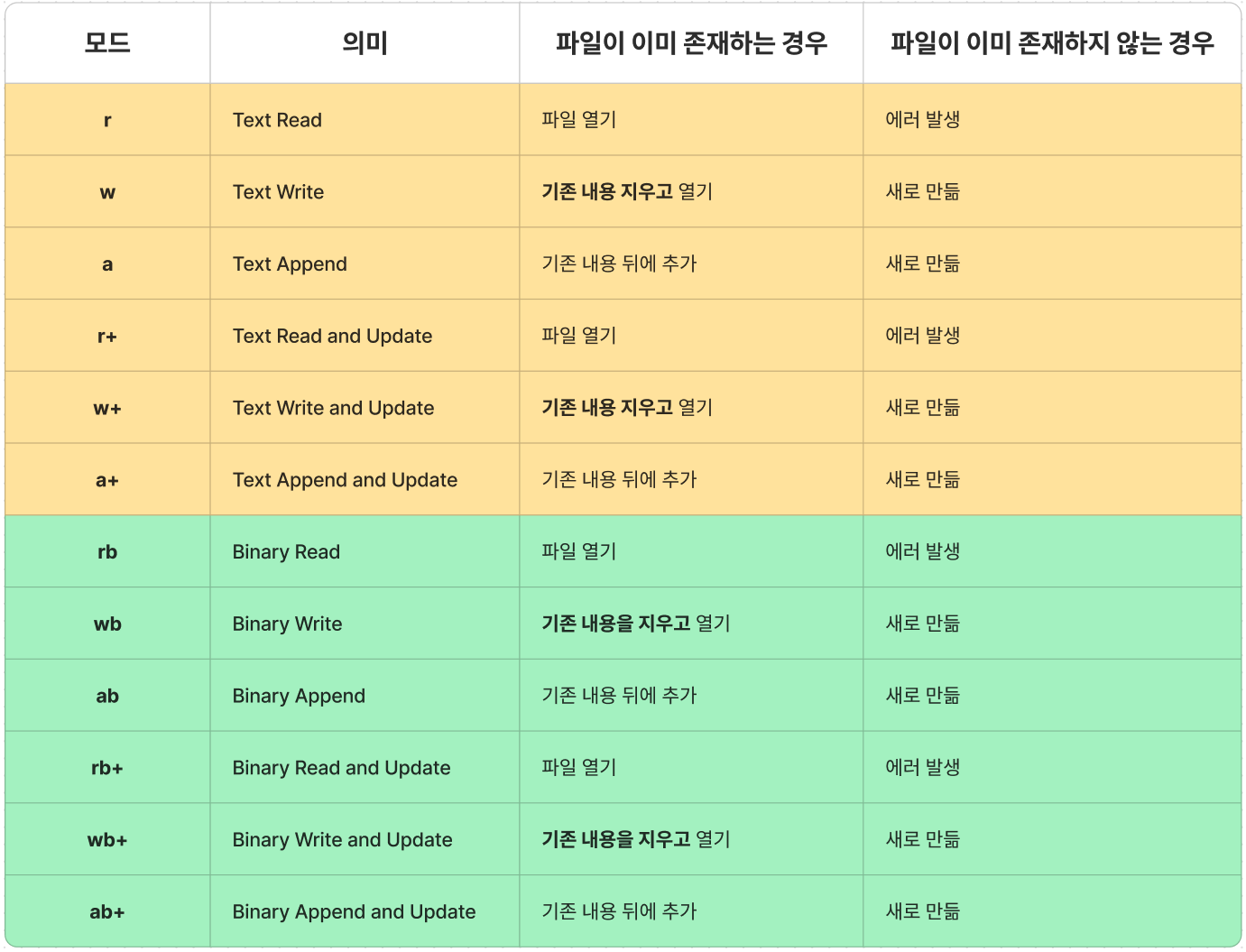
크게 모드는 r 이라는 읽기, w 라는 쓰기, a 라는 쓰기 모드가 있다. 다만 주의할 점은 w는 기존에 파일 내용이 있다면 해당 내용을 지우고 쓰기를 한다는 점에 주의해야 한다. 반면에 a 모드는 기존에 있던 파일 내용 끝에다가 새로운 내용을 추가하는 모드이다. w와 a 간의 차이점은 I/O가 일어나는 시점이 어디냐에 따라 다른 것이다.

그러면 이제 소스코드를 통해 직접 확인해보자.
#include <stdio.h>
int main(void) {
FILE* fp = NULL;
fp = fopen("../zedd.txt", "w");
if (fp == NULL) {
puts("Error: Failed to open file");
return -1;
}
fprintf(fp, "Hello");
fclose(fp);
return 0;
}
위 소스코드에서 FILE 이라는 키워드는 C언어에서 빌트인으로 제공하는 파일 구조체를 의미한다. 그리고 fopen() 함수에는 개방할 파일 명과 접근 모드를 인자로 넣어주고, 해당 함수는 마치 메모리를 동적할당 받을 때 사용하던 malloc() 함수처럼 주소가 담긴 포인터를 반환한다. fopen()에서는 반환하는 값 즉, 구조체 포인터 변수에 NULL 값이 들어있다면 파일을 읽거나 개방할 때 무엇인가 에러가 발생했음을 의미한다. 그리고 반드시 마지막에는 fclose() 함수로 개방한 파일을 닫아주는 것도 잊지말자.
그리고 난 뒤 Hex Fiend 프로그램을 이용해서 zedd.txt 라는 파일을 열어보자.
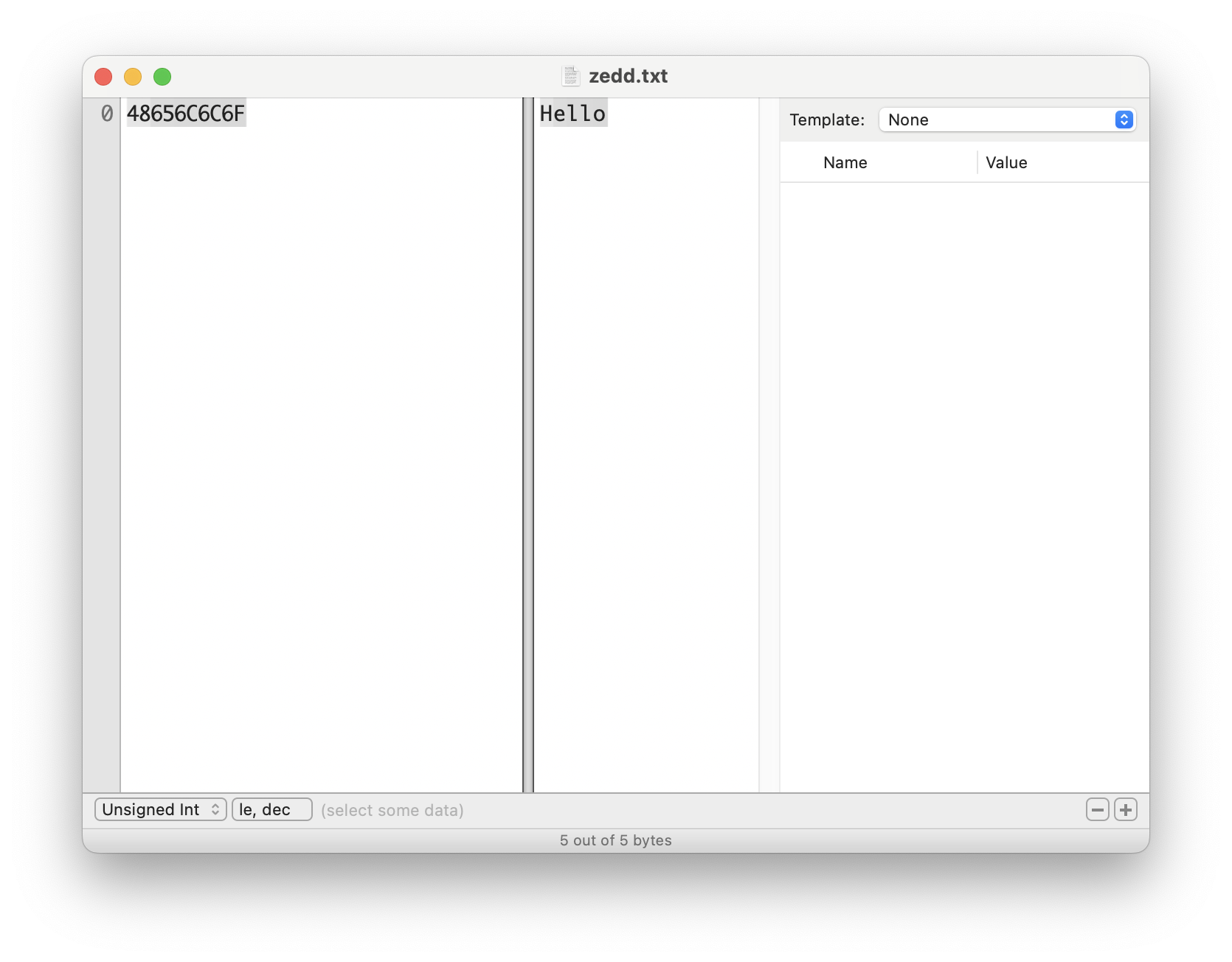
왼쪽 화면은 16진수의 숫자로 나타내어져 있고, 오른쪽은 그 16진수의 숫자를 ASCII 코드표에 의해 변환된 문자를 의미한다.
5. 텍스트 파일 입/출력
다음은 텍스트 파일의 입/출력에 대해서 알아보자. 소스코드 자체는 4번 목차에서 살펴본 것과 크게 다르지 않다.
#include <stdio.h>
int main(void) {
FILE* fp = NULL;
char ch;
fp = fopen("../zedd.txt", "w");
fputs("Zedd String!", fp);
fclose(fp);
fp = fopen("../zedd.txt", "r");
if (fp == NULL)
return -1;
while ((ch = fgetc(fp)) != EOF)
putchar(ch);
fclose(fp);
return 0;
}
로직은 간단하다. zedd.txt 라는 이름의 파일을 생성하고 Zedd String! 이라는 문자열을 쓴다. 그리고 다시 해당 파일을 개방해서 파일 속에 있는 내용을 문자 하나씩 읽어들인다. 여기서 주목할 부분은 EOF 라는 키워드이다. EOF는 End Of File의 줄임말로, 말 그대로 파일 내용의 마지막(끝)을 의미한다. 파일 내용을 한 문자씩 추출하다가 EOF 라는 키워드가 등장하면 파일의 내용이 끝이 났다라는 것을 의미한다.
다음으로 아래 소스코드를 보자. 아래 소스코드는 단지 zedd.txt 라는 파일에 여러 문자열을 write 하고, 해당 파일을 읽는데, 문자열 단위로 읽는 코드이다.
#include <stdio.h>
#include <string.h>
int main(void) {
FILE* fp = NULL;
char szBuffer[512] = { 0 };
fp = fopen("../zedd.txt", "w");
fputs("Test", fp);
fputs("HelloWorld", fp);
fputs("TestString", fp);
fclose(fp);
fp = fopen("../zedd.txt", "r");
if (fp == NULL)
return -1;
while (fgets(szBuffer, sizeof(szBuffer), fp)) {
printf("%s", szBuffer);
memset(szBuffer, 0, sizeof(szBuffer));
}
fclose(fp);
return 0;
}
그런데 위 소스코드에서 while 문 조건식에 적혀있는 fgets() 함수에 대해 살펴보자. 사실 fgets() 함수는 예전에 문자열 입/출력할 때 이미 우리가 배운 함수였다. 그 때의 포스팅에서 사용된 예시 소스코드를 잠깐 가져와보자.
#include <stdio.h>
int main(void) {
char szName[32] = { 0 };
printf("입력하세요: ");
fgets(szName, sizeof(szName), stdin);
printf("결괴: ");
puts(szName);
return 0;
}
보면 fgets() 함수의 인자에는 출력할 데이터가 담길 메모리 주소가 들어가고, 그 메모리의 크기, 마지막으로 stdin 이라는 것을 넣어주었다. 그런데 이번에는 stdin 이 아닌 fp 라는 FILE 구조체 포인터 변수를 넣어준 것 밖에 차이가 없는 것을 볼 수 있다.
사실 stdin는 파일의 이름을 의미하고, 이 파일은 장치를 추상화한 파일이다. 바로 콘솔 장치를 추상화한 파일이다. 물론 요즘에는 여기서 말하는 콘솔 장치가 물리적으로 존재하는 것이 아닌 가상화(소프트웨어화)시킨 장치이긴 하지만 어쨌건 그 장치를 추상화한 파일이 stdin 인 것이다. 그러면 stdout도 콘솔 장치를 추상화한 것일까? 맞다. 차이점은 stdin은 입력 시, stdout은 출력 시 사용하는 파일이다. 그래서 아래의 소스코드를 실행하면 정상적으로 출력된다.
#include <stdio.h>
int main(void) {
fputs("Hello World in fputs\n", stdout);
puts("Hello World in puts");
return 0;
}
참고로 윈도우 OS에서는 fopen() 함수를 이용해서 콘솔 입/출력을 수행할 수도 있긴 하다. 그 때 fopen 함수에서 읽어들이는 파일 이름은 CON 이다. 이 부분은 강의 내용을 참조하자. 필자는 MacOS라서 생략하겠다.
입력에 대한 예시는 아래와 같다.
#include <stdio.h>
int main(void) {
FILE* fp = NULL;
fp = stdin;
char szBuffer[32] = { 0 };
fgets(szBuffer, sizeof(szBuffer), fp);
fputs(szBuffer, stdout);
fclose(fp);
return 0;
}
위와 같은 과정을 통해서 우리가 뒤늦게 이해해볼 수 있는 부분은 우리가 앞서 콘솔을 통한 문자열 입/출력 등과 같은 행동을 수행했을 때, 내부적으로는 모두 파일의 입/출력이 수행된 것임을 알 수 있다.
6. Buffered I/O 와 파일 플러싱(Flushing)
이번에는 Buffered I/O 와 파일 플러싱에 대해서 알아보자. Buffered I/O에 대한 기초적인 설명은 문자열 입/출력 포스팅에서 언급했으니, 여기서는 파일 플러싱을 설명하면서 부가적으로 설명하는 정도만 언급하고 넘어간다.
파일 플러싱에서 플러싱(Flushing)은 무엇일까? 우선 플러싱의 사전적 정의는 "화장실에서 변기의 물을 내려서 변기 안의 내용물(?)을 비우고 다시 물로 채우는 것"을 의미한다. 사전적인 의미로 짐작해보았을 때는 "어떤 내용물을 비우는" 행위라고 볼 수 있겠다. 그러면 파일 플러싱에서는 어떤 내용물을 비우는 걸까? 여기서 Buffered I/O가 등장한다.
우선 쉬운 이해를 돕기 위해 콘솔 입/출력 프로그램을 예시로 들어, 사용자가 키보드로 입력을 하면 콘솔에 출력시키는 프로그램을 실행시킨다고 가정해보자.
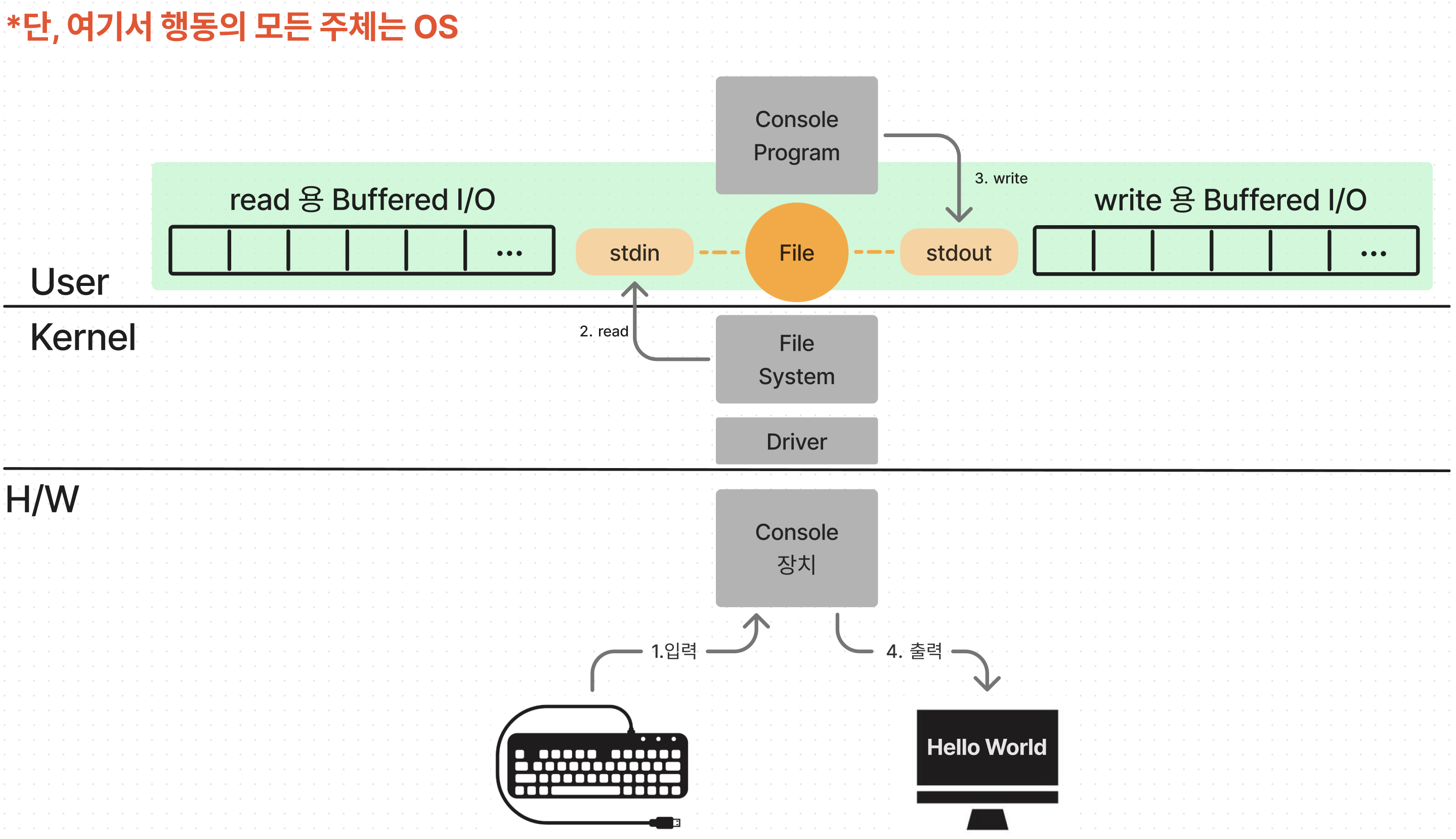
위 그림에서는 콘솔 장치를 물리적인 하드웨어라고 가정했다.(요즘엔 모두 콘솔을 가상화시킴) 첫 번째로 사용자가 키보드로 입력을 시키면 콘솔 장치를 추상화한 File 중 입력을 받는 용도의 파일은 stdin 파일을 통해 입력된 데이터를 읽어들이고 콘솔 프로그램에 전달한다. 이 때, stdin 파일을 통해 입력된 데이터를 읽어들일 때 Buffered I/O 라는 곳에 입력 데이터를 저장시킨다. 그리고 난 뒤 Buffered I/O에서 꺼내어 콘솔 프로그램에 전달 한다.
출력시에도 마찬가지로 먼저 Buffred I/O에 출력할 데이터를 저장해둔다. 그리고 난 뒤, Buffered I/O에서 꺼내어 콘솔 장치로 전달한 뒤 최종적으로 사람의 눈에 보이는 모니터로까지 이어진다. 앞서 소개한 행동들의 주체는 모두 OS이다.
위 과정 중에 파일 플러싱이라는 것은 Buffered I/O에 데이터가 담겨 있을 때 수행할 수 있다. 상황을 가정해보자. Buffered I/O에 데이터가 차고 있는 데, OS는 2가지 선택을 할 수 있다. 첫번째는 Buffered I/O에 현재 담겨 있는 데이터를 바로 꺼내기, 두번째는 Buffered I/O에 다른 데이터가 찰 때까지 조금만 더 기다린 뒤 데이터를 한 번에 다 꺼내기. 두번째 선택지를 고려하는 이유는 OS가 데이터를 가져갈 때마다 Buffered I/O에 매번 방문해야 하는데, 이 매번 방문하는 것이 시간이 걸릴 것을 대비해 효율성 측면에서 조금만 기다리다가 나중에 올 데이터까지 한 번에 가져와서 두, 세번 방문한 것을 한 번만 방문하도록 하는 것이다. 물론 이 과정에서 효율성은 개선되겠지만 반응성이 느려지는 것은 일부 감수해야 할 수 있다.
파일 플러싱은 두번째 방법을 채택하고 있다가 첫번째 방법으로의 전환 즉, 그때 그때 빨리빨리 Buffered I/O에서 데이터를 꺼내기 위해서 마치 인위적으로 Buffered I/O 공간을 비우도록 해서 데이터를 다 꺼내는 방식이다. C언어에서는 fflush() 함수를 사용해서 플러싱을 할 수 있다.
물론 파일 플러싱을 사용하지 않고, Non-Buffered I/O로 가게 되면 그때 바로바로 데이터를 출력에 전달할 수 있긴 하다. 하지만 이는 사용자 편의성 입장에서는 그리 좋지 않다. 단적인 예로, 우리가 지하철이나 버스를 타고 이동하면서 넷플릭스 같은 OTT 서비스나 유투브 영상을 시청하고는 한다. 그럴 때마다 우리는 영상 Progress bar에 회색 바 형태로 현재 영상 위치보다 더 긴 바가 위치해있는 것을 볼 수 있다.
바로 저게 Buffered I/O 라고 말할 수 있는데, 저것이 적용되어야 우리가 이동하면서 기지국 정보가 달라지거나 하는 다양한 원인으로 인해 영상 끊김이나 정지 현상을 막을 수 있는 것이다. 만약 저게 없다면 사용자 입장에서는 이동하면서 매번 영상에 버퍼링이 걸리는 현상이 계속 발생할 것이다.
7. 바이너리 파일 입/출력
다음으로는 문자열로 해석할 수 없는 내용이 담겨있는 바이너리 파일을 입/출력하는 방법에 대해 알아보자. 바이너리 파일 입/출력에는 fwrite() 와 fread() 함수가 사용된다. 아래 예시코드부터 살펴보자.
#include <stdio.h>
typedef struct USERDATA {
char szName[32];
char szPhone[32];
} USERDATA;
int main(void) {
FILE* fp = NULL;
USERDATA userData[2] = {{ "zedd-ai", "010-1234-5678" },{"zedd-ai", "010-5678-1234"}};
fp = fopen("../zedd.dat", "wb");
if (fp == NULL)
return -1;
fwrite(&userData, sizeof(USERDATA), 2, fp);
fclose(fp);
return 0;
}
구조체 배열을 위처럼 정의하고 fopen 함수와 fwrite 함수를 사용해서 바이너리 파일로 write를 수행했다. 참고로 fwrite 함수의 첫번째 인자에는 해당 구조체 배열의 메모리 주소를 전달해주어야 한다. 실행 결과로 생성된 zedd.dat 라는 바이너리 파일을 Hex Fiend 프로그램을 통해서 열어보면 아래와 같다.
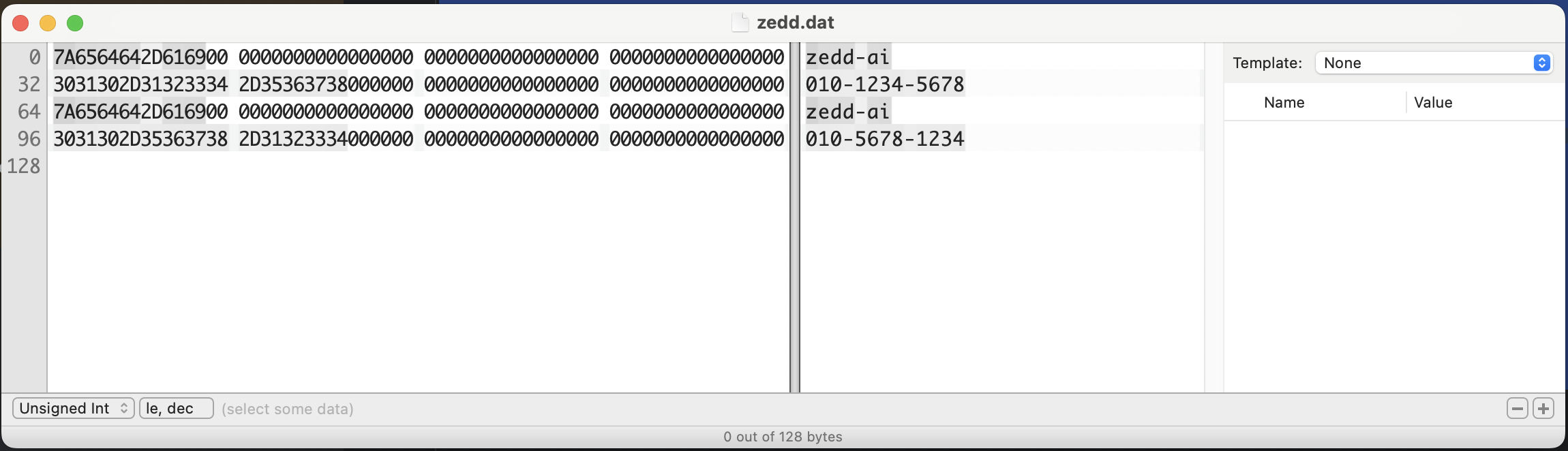
구조체의 멤버 하나 당 32비트로 정의했다. 그리고 배열의 요소 개수가 2개이기 때문에 위처럼 나란히 구조체 데이터가 write된 것을 볼 수 있다. 그리고 위에서 사진에서 볼 수 있듯이 실질적으로 구조체 멤버가 차지하는 데이터는 32비트보다 훨씬 적다. 그리고 나머지 부분은 모두 0으로 채워져있음을 볼 수 있다. 이렇게 보면 데이터 크기에 비해 메모리 크기가 비효율적으로 낭비되고 있다고 할 수 있다. 하지만 이렇게 고정된 비트 수(여기에서는 32비트)로 하면 데이터를 read 하거나 write 할 때 매우 편해진다.
이제 그러면 write한 바이너리 파일을 read 해보자.
#include <stdio.h>
typedef struct USERDATA {
char szName[32];
char szPhone[32];
} USERDATA;
int main(void) {
int size = 0;
FILE* fp = NULL;
USERDATA userData[2] = { {0}, {0}};
fp = fopen("../zedd.dat", "rb");
if (fp == NULL)
return -1;
size = fread(&userData, sizeof(USERDATA), 2, fp);
puts(userData[0].szName);
puts(userData[1].szName);
puts(userData[0].szPhone);
puts(userData[1].szPhone);
return 0;
}
현재 zedd.dat 에는 2개의 구조체가 들어가 있으니, read 한 뒤 반환되는 것은 구조체 배열이다. 구조체 배열은 일반 배열처럼 배열 연산자를 사용해서 특정 구조체에 접근하면 된다. 참고로 fread() 함수를 호출할 때 넣어주는 인자 즉, 위 소스코드 기준으로는 userData의 자료형이 어떤 것인지는 상관없다. void 자료형의 포인터로 인자를 받기 때문이다. 실제로 fread 함수 인자의 설명 부분을 보면 알 수 있다.

8. 파일 포인터 위치 제어
여기서 말하는 파일 포인터는 위에서 살펴본 포인터와 같은 개념은 아니고, I/O가 일어나는 위치를 의미한다. 예를 들어, 아래와 같이 I/O 시점이라고 하는 부분이 파일 포인터라고 하며 파일 구조체 포인터와 구분하기 위해서는 앞으로 파일 I/O 포인터라고 용어를 칭하도록 하자.

그런데 이러한 파일 I/O 포인터의 위치를 커스텀하게 옮기고 싶어야할 때가 있다. 그러기 위해 존재하는 함수가 fseek()이다. 일단 아래 소스코드를 살펴보자.
#include <stdio.h>
int main(void) {
FILE* fp = NULL;
char* pszData = "0123456789012345678901234567890123456789";
fp = fopen("../Test.dat", "wb");
if (fp == NULL)
return -1;
fwrite(pszData, 32, 1, fp);
fclose(fp);
return 0;
}
긴 문자열인 pszData를 Test.dat 라는 바이너리 파일로 생성했다. 해당 파일의 내용을 Hex Fiend로 보면 아래와 같다.
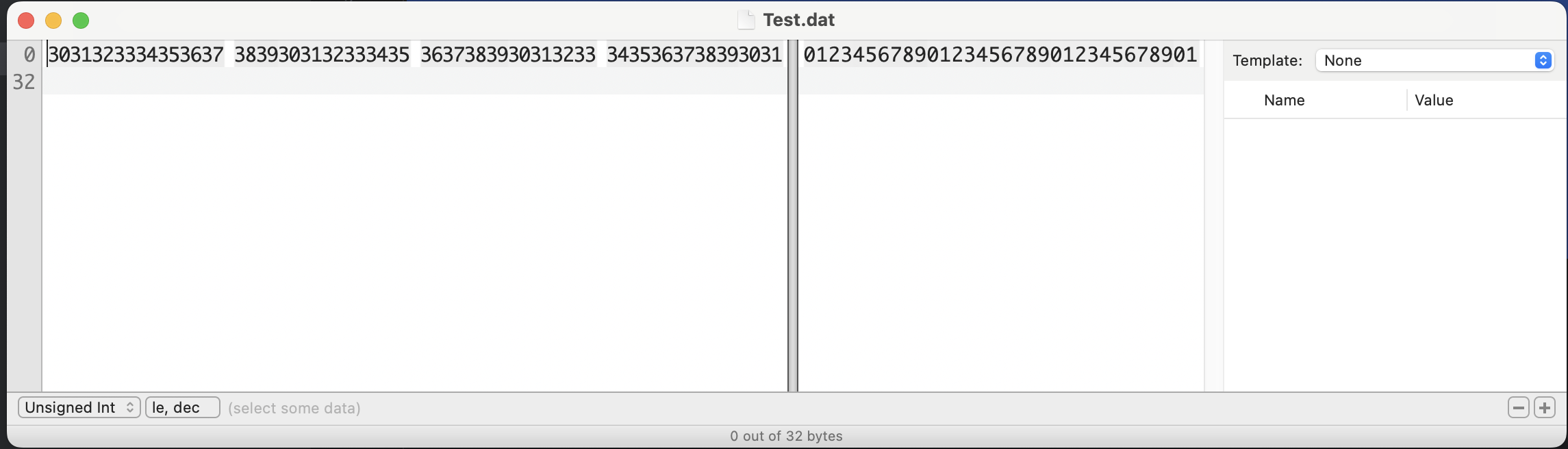
이제 fseek() 함수를 사용해서 파일 I/O 포인터를 옮겨보도록 하자. 우선 파일 I/O 포인터를 옮기는 위치를 의미하는 일종의 상수 값이 존재하는데, 종류는 아래와 같다.
| SEEK_CUR | 파일 I/O 포인터의 현재 위치 |
| SEEK_END | 파일 I/O 포인터의 끝 위치 |
| SEEK_SET | 파일 I/O 포인터의 시작 위치 |
fseek() 함수는 3가지 인자를 받는데, 첫 번째는 파일 구조체 포인터 변수, 두 번째는 offset 값, 세 번째는 방금 알아본 파일 I/O 포인터의 위치 상수값. 여기서 offset은 파일 I/O 포인터 위치 기준에서의 상대적인 위치 값이다. 예를 들어 아래와 같다.
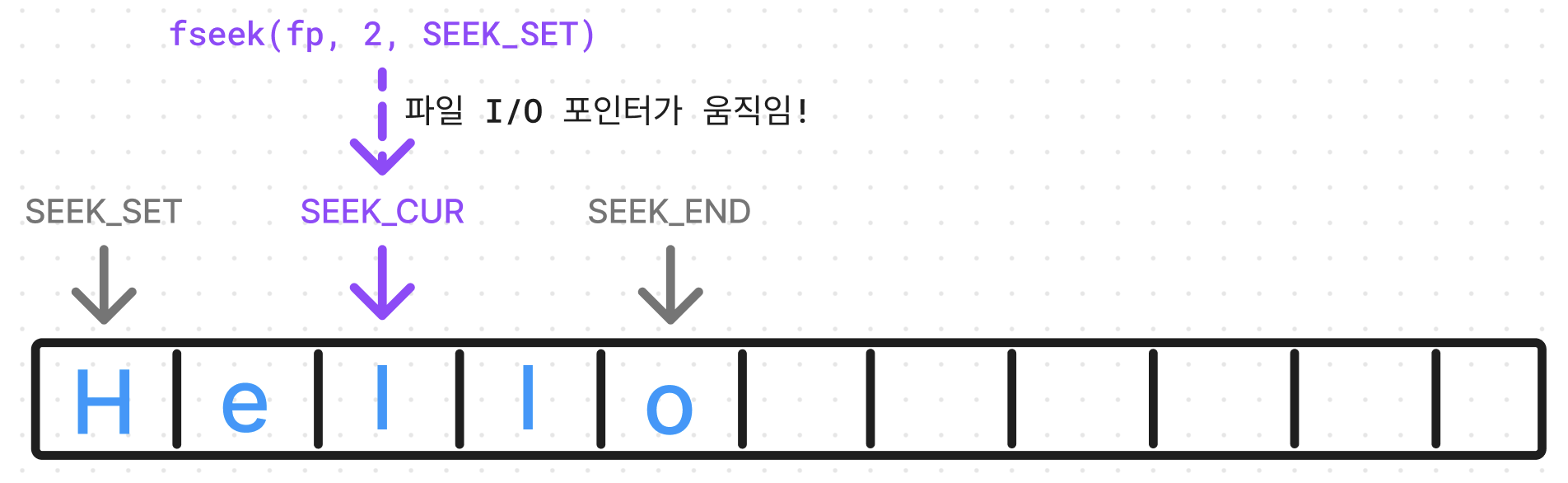
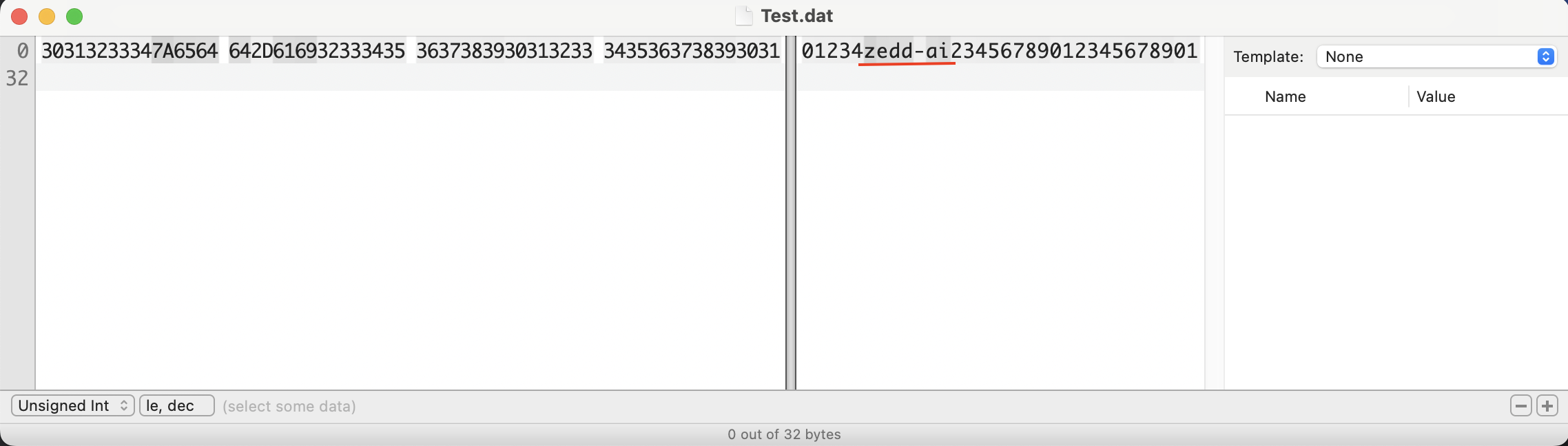
이제 fseek() 함수를 실전에 사용해보자. 위에서 소개한 zedd.dat 파일에 파일 I/O 포인터를 시작점에서 5칸 만큼 떨어진 위치로 옮긴 뒤 다른 문자열을 overwrite를 시켜보자.
#include <stdio.h>
int main(void) {
FILE* fp = NULL;
char* pszData = "0123456789012345678901234567890123456789";
fp = fopen("../Test.dat", "wb");
if (fp == NULL)
return -1;
fwrite(pszData, 32, 1, fp);
fseek(fp, 5, SEEK_SET);
fwrite("zedd-ai", 7, 1, fp);
fclose(fp);
return 0;
}
생성된 Test.dat 파일 내용을 보면 zedd-ai 라는 단어가 파일 I/O의 시작점으로부터 5칸 떨어진 지점부터 overwrite 된 것을 볼 수 있다.
'C > 기초와 문법' 카테고리의 다른 글
| [C] 컴파일 전처리기 (0) | 2024.08.23 |
|---|---|
| [C] 변수와 상수 고급 이론 (4) | 2024.08.21 |
| [C] 서로 다른 유형의 자료형을 모을 수 있는 구조체와 공용체 (0) | 2024.08.14 |
| [C] 함수 응용 (0) | 2024.08.13 |
| [C] 메모리와 포인터 (0) | 2024.08.09 |



