🔊 해당 포스팅은 인프런의 널널한 개발자님의 독하게 시작하는 C 프로그래밍 강의를 듣고 개인적인 복습 목적 하에 작성된 글입니다. 해당 포스팅에 사용된 모든 자료는 필자가 직접 재구성하였음을 알립니다.

이번 포스팅에서는 구조체와 공용체에 대해서 알아보고 사용하는 방법에 대해 알아보자.
1. 구조체를 만들어보자!
우선 구조체랑 비교한다고 하면 이전에 배웠던 배열이 비교군이 될 수 있겠다. 구조체와 배열의 공통점이라고 한다면 여러 자료형을 모아 새로운 하나의 형식으로 기술할 수 있다는 것이다. 하지만 배열은 그 여러 자료형들이 반드시 같은 유형(ex. 정수, 실수, 문자)이어야 하는 반면 구조체는 서로 다른 유형의 자료형들이 모이는 것이 가능하다. 물론 구조체에서 배열처럼 같은 유형의 자료형이여도 상관은 없다.
구조체의 또 한가지 특징은 배열과 달리 인덱스가 없다. 따라서 구조체의 어떤 요소에 접근하려면 다른 방식을 사용해야 한다. 구조체 내에 존재하는 요소를 '멤버'라고 부르는데, 이 멤버에 접근하려면 멤버 접근 연산자를 사용해야 한다. 만약 구조체를 식별하는 식별자가 데이터라고 한다면 온점(.) 이라는 멤버접근 연산자를 사용하고, 만약 식별자가 포인터라면 -> 라는 멤버접근 연산자를 사용한다.
그리고 구조체는 typedef 라는 키워드를 같이 선언하는 것이 일반적이다. 그러면 이제 아래 예시코드를 살펴보면서 구조체를 선언하고 정의하는 방법에 대해서 알아보자.
먼저 구조체를 정의하는 방법인데 2가지가 존재한다. typdef를 같이 선언하지 않는 방법이다.
#include <stdio.h>
struct USERDATA {
int nAge;
char szName[32];
char szPhone[32];
};
int main(void) {
struct USERDATA user = { 0, "", "" };
return 0;
}
특징은 typedef를 같이 선언하지 않는다면 main 함수에서 USERDATA 라는 구조체를 선언할 때 반드시 struct 라는 키워드를 맨 앞에 붙여주어야 한다. 이렇게 되면 struct USERDATA 라는 2개의 키워드가 하나의 type 종류가 된다.
이번엔 typedef를 같이 선언하게 되는 코드를 살펴보자.
#include <stdio.h>
typedef struct USERDATA {
int nAge;
char szName[32];
char szPhone[32];
} USERDATA;
int main(void) {
USERDATA user = { 0, "", "" };
return 0;
}
차이점은 typedef 로 구조체를 선언할 때 마지막에 USERDATA를 선언해주어야 한다. 이렇게 함으로써 main 함수 내에서는 USERDATA 라는 키워드만 정의해서 만든 구조체를 선언하고 정의할 수 있다. 그리고 main 함수 내에서 'user' 라는 것을 '변수'라고 칭하기도 하지만 '인스턴스'라고 말하기도 한다. 참고로 알아두자.
그러면 다음으로는 구조체의 멤버에 멤버 연산자로 접근해서 값을 write 해보도록 하자.
#include <stdio.h>
#include <string.h>
typedef struct USERDATA {
int nAge;
char szName[32];
char szPhone[32];
} USERDATA;
int main(void) {
USERDATA user = { 0, "", "" };
user.nAge = 10;
strcpy(user.szName, "zedd");
strcpy(user.szPhone, "010-1234-5679");
printf("%d살, 이름: %s, 폰번호: %s", user.nAge, user.szName, user.szPhone);
return 0;
}
일단 구조체를 식별하는 식별자가 포인터가 아니기 때문에 구조체 내의 멤버에 접근할 때 멤버 접근 연산자로 온점(.)을 사용할 수 있다. 그리고 nAge는 정수이기 때문에 단순 대입 연산자(=)를 사용해서 write 할 수 있다. 하지만 szName, szPhone은 문자열이기 때문에 이전 포스팅에서 배운 strcpy() 함수를 사용해서 원하는 문자열을 write 해주자.
2. 구조체에 대해서 메모리 동적 할당받기
다음으로 알아볼 내용은 구조체에 대해서도 메모리를 동적으로 할당받는 방법이다. 구조체에서도 malloc() 함수를 사용해서 메모리를 동적할당 받는다. 단, 1번 목차에서 소개한 것처럼 메모리를 동적 할당 받으면 당연히 등장하는 것이 포인터 변수이고, 이 포인터 변수로 선언된 구조체에서는 접근 연산자가 온점(.)에서 -> 로 바뀌어야 한다. 아래 예시 소스코드를 살펴보자.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct USERDATA {
int nAge;
char szName[32];
char szPhone[32];
} USERDATA;
int main(void) {
USERDATA* pUser = NULL;
pUser = (USERDATA*)malloc(sizeof(USERDATA));
pUser -> nAge = 10;
strcpy(pUser -> szName, "zedd");
strcpy(pUser -> szPhone, "010-1234-5678");
printf("%d살, 이름: %s, 번호: %s", pUser->nAge, pUser->szName, pUser->szPhone);
free(pUser);
return 0;
}
1번 목차에서 살펴본 예시코드와 거의 비슷하되 main 함수에서 pUser 라는 변수를 정의할 때 직접 만든 USERDATA 라는 구조체 포인터 변수를 정의했다. 그리고 pUser 라는 구조체 포인터 변수에 malloc() 함수를 이용해 메모리를 동적 할당 받았다. 참고로 malloc() 함수는 메모리 주소를 반환하는데 자료 유형이 무엇인지 모르지만 어쨌건 메모리 주소를 담고 있다는 것을 의미하는 void* 타입을 반환하게 된다. 그래서 void* 타입에 (USERDATA*) 로 강제 형변환을 해준다. 이는 (char*) 이나 (int*), (double*) 형변환 모두 마찬가지이다. 또 참고할 점으로 malloc() 함수로 메모리를 할당할 때 인자로 넘겨준 구조체 메모리 크기보다 더 큰 메모리를 할당할 수도 있다는 점도 알아두자.
그리고 이제 pUser 라는 포인터 변수가 가리키는 구조체의 nAge 라는 멤버에 값 10을 write 하기 위해서 -> 라는 멤버접근 연산자를 사용한다. 그리고 szName, szPhone 멤버에 값을 write 하기 위해서 해당 멤버들은 문자열이기 때문에 strcpy() 함수를 사용하면 된다. 그리고 마지막에 꼭 동적 할당 받은 pUser 라는 포인터 변수를 OS에 반납함으로써 메모리를 반납해주는 과정까지 꼭 수행해주자.
구조체도 배열이나 정수, 실수, 문자와 마찬가지로 함수의 반환이나 매개변수로 사용이 가능하다는 특징이 있다. 다만, 이 때 잘 생각해주어야 하는 것은 만약 함수의 매개변수로 넣어줄 때 call by value 방식으로 할 것이냐 call by reference 방식으로 할 것이냐를 잘 생각해봐야 한다.
만약 call by value로 한다면 함수의 매개변수에 구조체가 들어간다. 하지만 이 때 인자로 넘겨준 구조체 크기가 크다면 함수로 넘겨줄 때 쓰레드의 스택 프레임 메모리에 그만큼 큰 구조체가 저장될 것이다. 만약 극단적으로 구조체 크기가 1MB가 초과된다면 스택 프레임 메모리는 해당 구조체를 저장하다가 스택 오버플로우가 발생하게 될 것이다. 따라서 구조체를 함수로 전달할 때는 포인터 변수를 이용하는 call by reference 방식이 권장된다. 아래 예시 소스코드를 보자.
#include <stdio.h>
typedef struct USERDATA {
int nAge;
char szName[32];
char szPhone[32];
} USERDATA;
void GetUserData(USERDATA* pUser) {
printf("나이를 입력하세요 :");
scanf("%d%*c", &pUser->nAge);
printf("이름을 입력하세요 :");
fgets(pUser->szName, sizeof(pUser->szName), stdin);
printf("번호를 입력하세요 :");
fgets(pUser->szPhone, sizeof(pUser->szPhone), stdin);
}
int main(void) {
USERDATA user = { 0 };
GetUserData(&user);
printf("%d살, 이름: %s, 번호: %s", user.nAge, user.szName, user.szPhone);
return 0;
}
GetUserData 함수를 보면 pUser 라는 매개변수가 있고, 이는 USERDATA 타입을 갖는 구조체 포인터 변수를 의미한다. 그리고 해당 함수 내에서 나이와 이름, 번호를 입력을 받아서 구조체 포인터 변수의 멤버에 접근하여 값을 write 한다. 그리고 main 함수에서는 단순히 구조체로 정의한 user 변수에 주소 연산(&)을 취하여 GetUserData 변수로 넘겨준다. 그렇게 되면 &user 는 곧 USERDATA 타입을 갖는 구조체 포인터 변수가 된다.
3. 구조체를 멤버로 하는 구조체
이번에는 구조체의 멤버가 또 다른 구조체일 경우를 알아보자. 두 개의 경우가 있는데, 첫 번째는 구조체의 멤버가 구조체인 경우, 두 번재는 구조체의 멤버가 구조체 포인터 변수일 때이다. 우선 첫 번째 경우에 대한 예시 소스코드를 살펴보자.
#include <stdio.h>
typedef struct DataBody {
int nHeight;
int nWeight;
} DataBody;
typedef struct UserData {
char szName[32];
char szPhone[32];
DataBody body;
} UserData;
int main(void) {
UserData user = {
"zedd",
"010-1234-5678",
{ 180, 77}
};
printf("이름: %s, 번호: %s, 키: %d, 몸무게: %d",
user.szName, user.szPhone, user.body.nHeight, user.body.nWeight);
}
사실 이전 목차에서 살펴본 예시 소스코드와 크게 다르지 않다. 특징은 UserData 라는 구조체의 body라는 멤버가 DataBody 라는 또 다른 구조체인 점이다. 그래서 해당 멤버에 접근하려면 온점 2개를 사용해서 user.body.nHeight 방식으로 멤버 접근을 수행하면 된다.
우리가 주목할 부분은 다음으로 알아볼 구조체 멤버가 구조체 포인터 변수일 때이다. 보통 이러한 형태는 연결 리스트라는 선형 자료구조를 만들 때 가장 흔하게 사용된다. 연결 리스트를 만들기 위해서 구조체 안의 멤버로 또 자기 자신 구조체를 정의한다. 먼저 일부 소스코드만 보자.
typedef struct DataBody {
int nHeight;
int nWeight;
struct DataBody* pNext;
} DataBody;
구조체를 정의했는데, 멤버로 또 DataBody 라는 구조체를 정의했다. 그런데 구조체 안에서 자기 자신의 구조체를 정의할 때는 위처럼 struct 키워드를 써주어야 한다. 이전에 배운 것처럼 struct 키워드를 사용하지 않으려면 위 소스코드의 맨 끝까지가 실행되어야 DataBody 라는 새로운 형이 정의되는 것이기 때문에 자기 사진의 구조체를 멤버로 정의할 때는 아직 해당 구문이 실행된 것이 아니기 때문에 struct 키워드를 넣어주어 정의를 해주어야 한다는 점을 잊지 말자.
이제 소스코드 전문을 보자.
#include <stdio.h>
typedef struct DataBody {
char szName[32];
char szPhone[32];
struct DataBody* pNext;
} DataBody;
int main(void) {
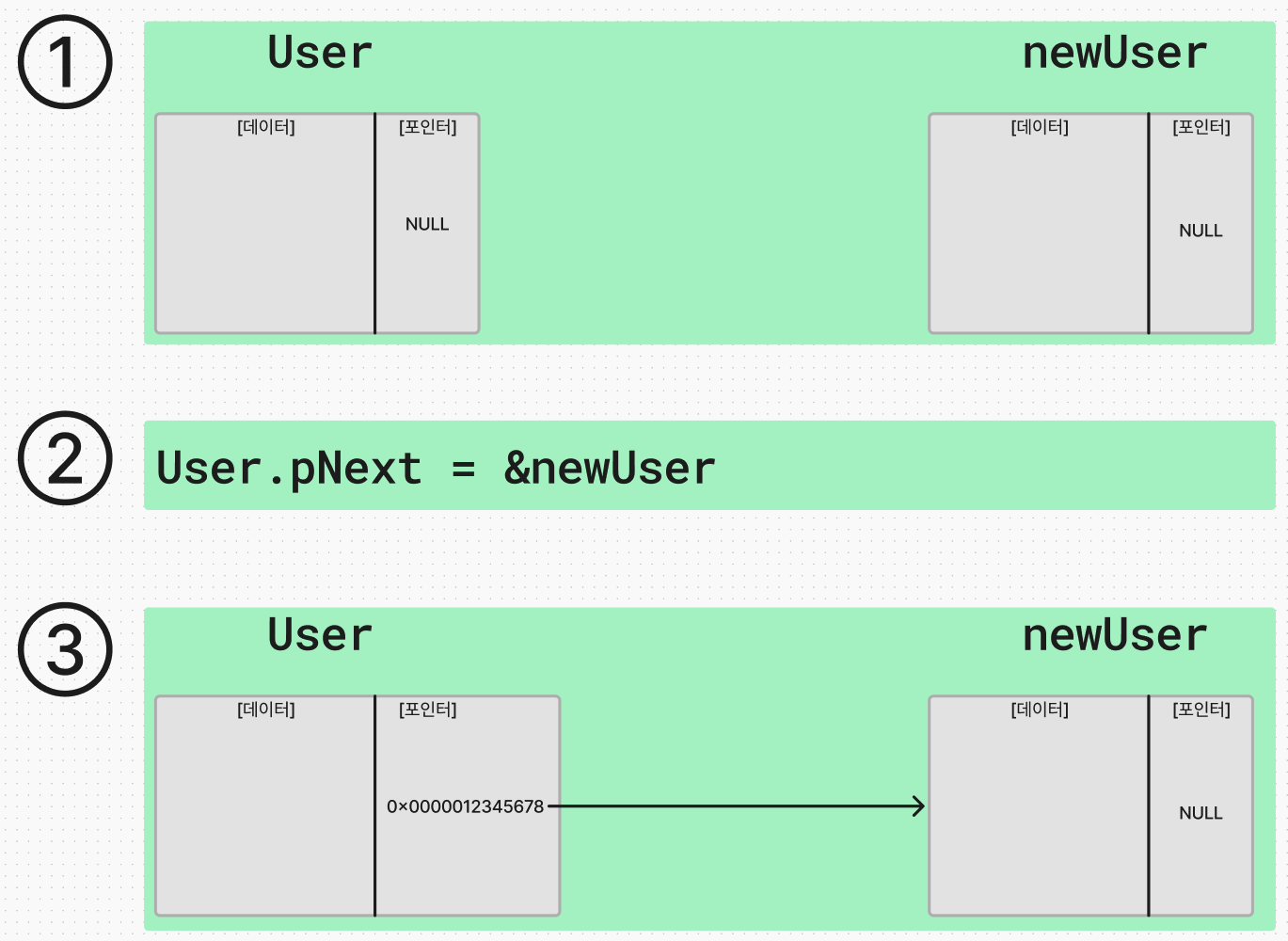
DataBody User = { "zedd", "010-1234-5678", NULL};
DataBody newUser = {"tom", "010-5555-5555", NULL};
User.pNext = &newUser;
printf("이름: %s, 번호: %s\n", User.szName, User.szPhone);
printf("이름: %s, 번호: %s\n", newUser.szName, newUser.szPhone);
}
처음에 User, newUser 라는 구조체를 정의할 때 마지막 멤버의 포인터 변수는 NULL로 정의를 했다. 그리고 User 라는 구조체의 pNext 라는 구조체 포인터 변수에다가 newUser 라는 구조체에 주소 연산(&)를 적용해서 할당했다. 따라서, 아래와 같은 단계가 진행된 것이다.
4. 고정된 메모리 크기 안에서 서로 다르게 해석하자: 공용체
다음으로 알아볼 내용은 또 다른 형식의 종류로 구조체와는 다른 특성을 갖는 공용체에 대해서 알아보자. 공용체란, 고정된 메모리 크기 내에서 서로 다른 자료형으로 해석하는 것을 말한다. 예를 들어서, 아래와 같이 8바이트의 메모리가 있다고 했을 때, char(문자) 자료형으로는 8개가 들어갈 수 있고, short 자료형으로는 4개, int 자료형으로는 2개가 들어갈 수 있다.
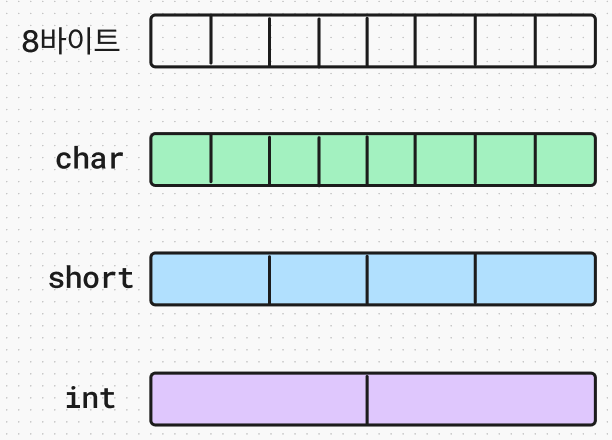
위 그림처럼 8바이트라는 고정 길이에서 자료형이 char 인지, short 인지, int 인지에 따라 해석 방법이 달라진다는 것이다. 공용체를 정의하는 예시 소스코드를 살펴보자.
typedef union _IP_ADDR {
int nAddress;
short awData[2];
unsigned char addr[4];
} _IP_ADDR;
공용체는 선언하고 정의하는 방식이 구조체와 동일하다. 다만 키워드가 union 으로만 바뀐 것 뿐이다. 위처럼 _IP_ADDR 이라는 변수를 구조체로 정의했을 때랑 공용체로 정의했을 때랑 차이점을 메모리 도식화로 표현하면 아래와 같다.
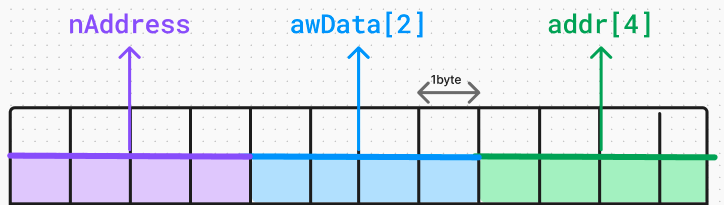
만약 _IP_ADDR을 구조체로 정의했다면 위처럼 메모리 크기가 할당되었을 것이다. 즉, nAddress, awData[2], addr[4] 각각에 필요한 4바이트 3개를 모두 할당해서 총 12바이트 메모리 크기가 할당된다. 반면에 공용체로 정의했다면 아래와 같이 변한다.
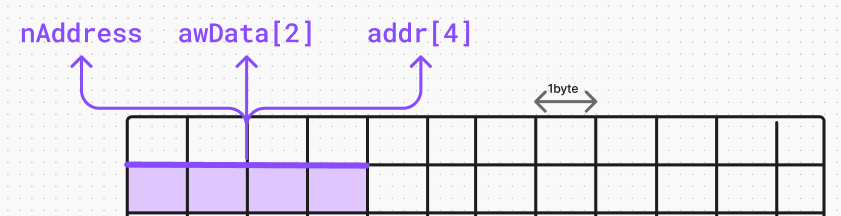
즉 고정된 4바이트 길이 안에서 언제는 nAddress로 해석되고, 언제는 awData[2]로 해석되고, 언제는 addr[4]로 해석된다는 것이다. 이렇게 여러 데이터가 하나의 고정된 메모리 크기를 일종의 '공용'으로 사용한다고 해석할 수 있다.
공용체도 멤버에 접근하는 연산자는 구조체와 동일하다. 예시는 아래와 같다.
#include <stdio.h>
typedef union _IP_ADDR {
int nAddress;
short awData[2];
unsigned char addr[4];
} _IP_ADDR;
int main(void) {
_IP_ADDR Data = { 0 };
Data.nAddress = 0x41424344;
printf("%c%c%c%c\n", Data.addr[0], Data.addr[1], Data.addr[2], Data.addr[3]);
}5. 구조체를 멤버 맞춤하기
마지막으로 구조체에서 멤버 맞춤이라는 것에 대해서 배워보자. 이전 목차에서 구조체와 공용체의 차이를 살펴보면서 만약 구조체를 정의한다면 아래와 같이 메모리 크기가 할당된다고 했다.
그런데 사실 이것은 엄밀히 조건이 존재해야 한다. 바로 구조체를 멤버 맞춤하는 것이 1바이트 기준으로 되어야 한다는 조건이다. 이게 무슨말일까? 이를 이해하기 위해서 기본적으로 구조체의 멤버들을 메모리에 할당할 때는 멤버들의 메모리가 연속적으로 접해있지는 않다. 우선 예시 소스코드를 살펴보자.
#include <stdio.h>
typedef struct USERDATA {
char ch;
int nAge;
char szName[5];
} USERDATA;
int main(void) {
USERDATA user = { 'A', 10, "zedd"};
printf("%d\n", sizeof(USERDATA));
}
위 소스코드는 구조체를 할당하고 그 구조체의 메모리 크기를 출력하도록 되어 있다. 출력값은 무엇일까? ch는 char이므로 1바이트, nAge는 정수 1개이기 때문에 4바이트, szName은 5개의 문자로 이루어진 문자열이니까 5바이트. 그래서 총 합산해서 10바이트가 나올 것 같다. 하지만 결과는 16바이트가 나온다. 대체 왜그럴까? 바로 구조체 멤버 맞춤 즉, 멤버 간의 메모리가 연속해서 접해있지 않기 때문이다.
실제로 확인하기 위해 아래처럼 break point를 찍어서 디버그 모드로 실행한 뒤 메모리 뷰를 살펴보자.
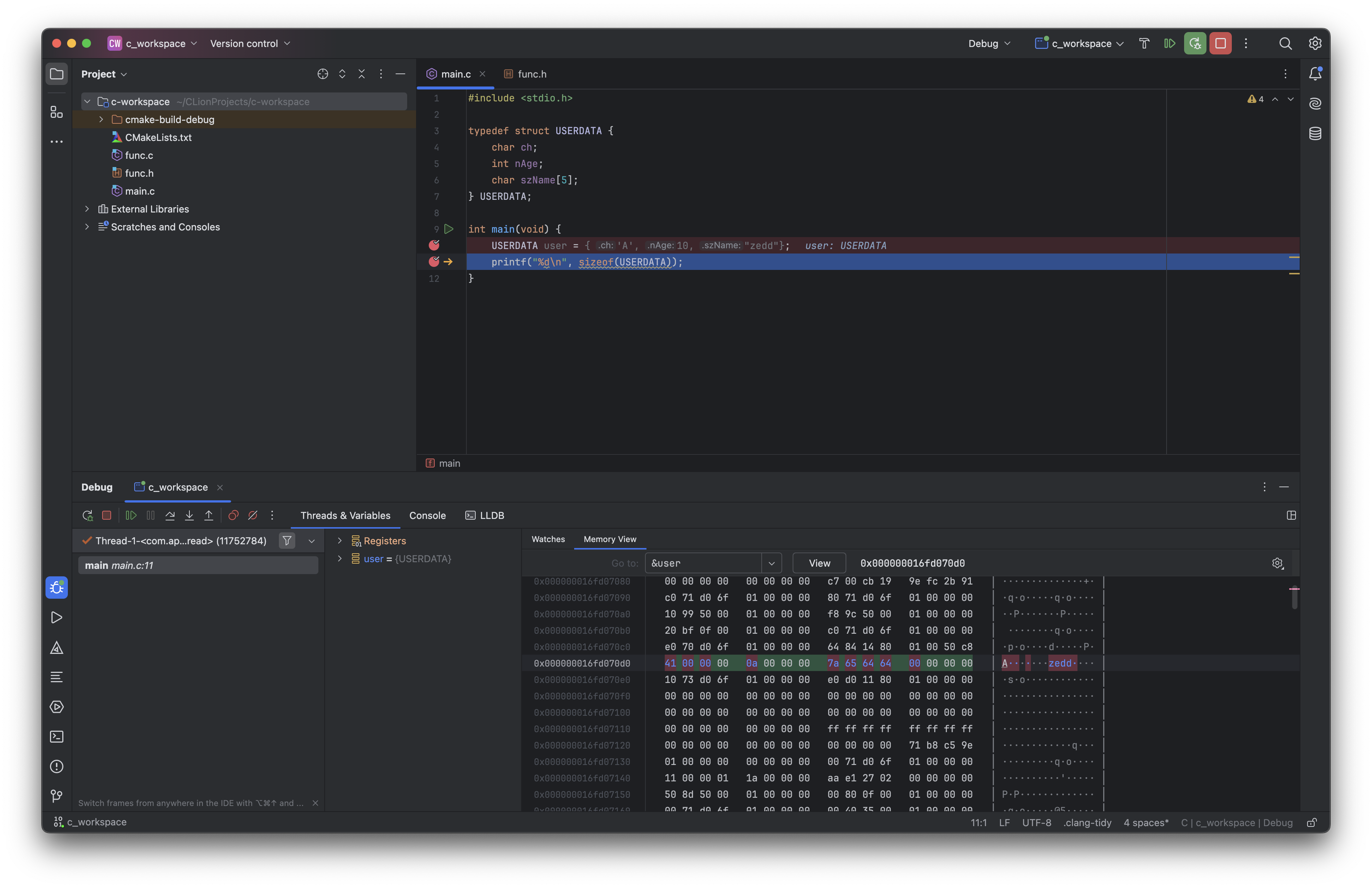
메모리 뷰에 구조체를 할당한 변수 user에 주소 연산(&)을 찍어서 살펴보았더니 초록색 빨간색 영역을 보면 총 16바이트가 할당된 것을 볼 수 있다. 위 사진 속 빨간색 영역을 실질적으로 데이터가 차지하는 메모리 영역이고, 빨간색 영역 간에 존재하는 초록색 공간이 바로 구조체의 멤버들 간에 메모리의 공백을 의미한다. 어떻게 보면 메모리가 쓸데없이 낭비되는 것이라고 볼 수 있다.
이렇게 구조체의 멤버 간에 메모리 공백을 없애고 연속적으로 하게 만들려면 pragma 라는 전처리기를 이용할 수 있다. 예시코드는 아래와 같다.
#include <stdio.h>
#pragma pack(push, 1)
typedef struct USERDATA {
char ch;
int nAge;
char szName[5];
} USERDATA;
#pragma pack(pop)
int main(void) {
USERDATA user = { 'A', 10, "zedd"};
printf("%d\n", sizeof(USERDATA));
}
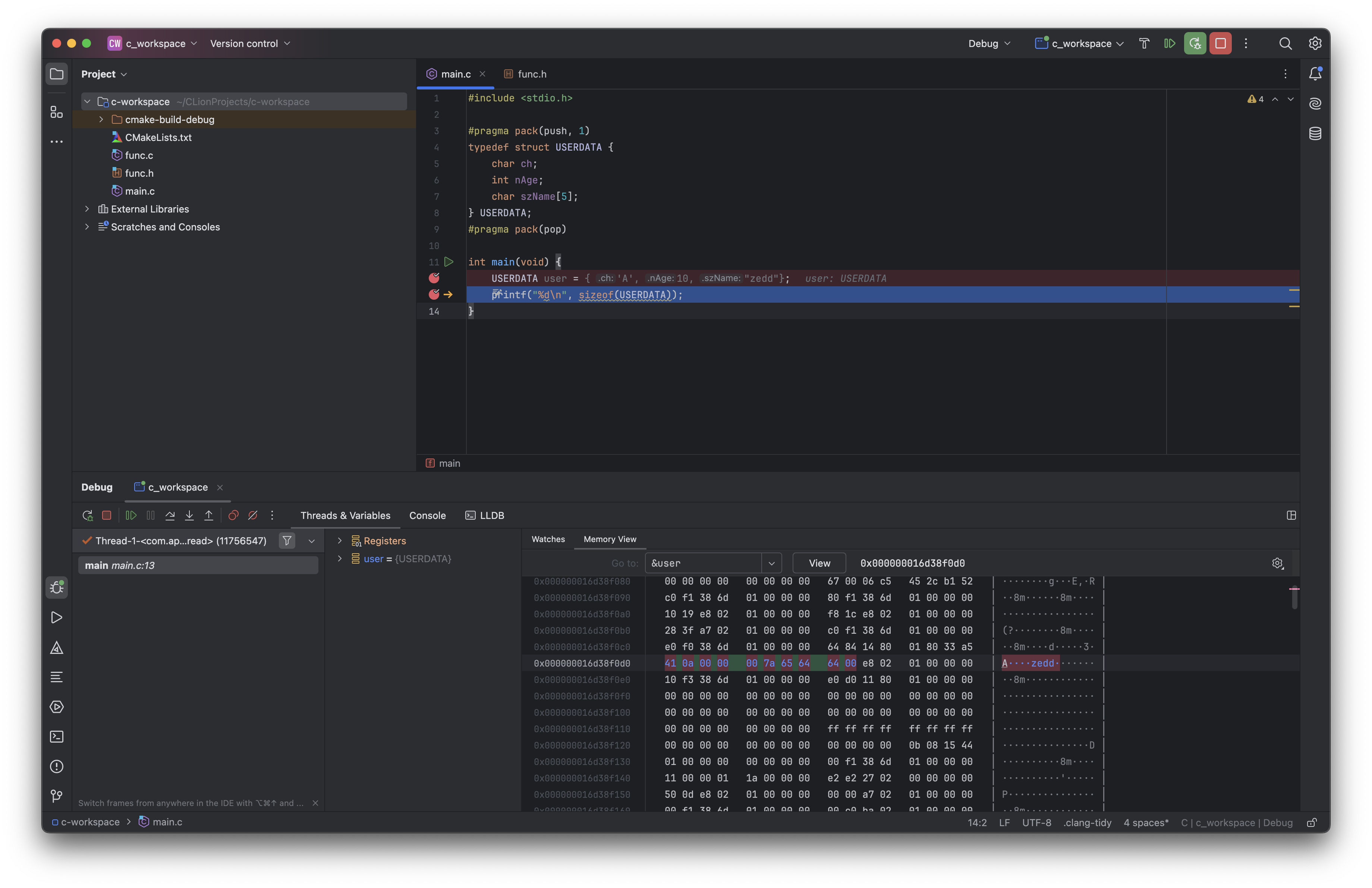
전처리기 중 pragma의 pack() 을 사용해서 할 수 있다. pack(push, 1)은 기본적으로 세팅되어 있는 구조체 멤버 맞춤 즉, 멤버 간의 빈 메모리 간격이 세팅되어 있는 값을 잠시 1로 대체하라는 것을 의미한다. 그리고 pack(pop)에서 방금 push한 구조체 멤버 맞춤 값을 다시 삭제하고 디폴트로 설정되어 있던 값으로 복구하라는 뜻이다.
참고로 위처럼 전처리기를 구조체 앞뒤에 사용하면 해당 구조체에서만 구조체 맞춤 간격을 1로 조정하게 된다. 전처리기 밖에 다른 구조체들이 정의되어 있다면 그 구조체들은 기본적으로 설정되어 있는 구조체 멤버 맞춤 값을 사용하게 된다.
위 코드에 대해서 똑같이 break point를 설정한 뒤 메모리 뷰를 보면 이전과 달리 멤버 간의 메모리가 연속적으로 접해있는 것을 볼 수 있다.
'C > 기초와 문법' 카테고리의 다른 글
| [C] 변수와 상수 고급 이론 (4) | 2024.08.21 |
|---|---|
| [C] 파일 입/출력 (0) | 2024.08.17 |
| [C] 함수 응용 (0) | 2024.08.13 |
| [C] 메모리와 포인터 (0) | 2024.08.09 |
| [C] 제어문과 반복문, 그리고 배열과 함수 (0) | 2024.08.04 |



