🔊 이번 포스팅에는 최근에 Python으로 알고리즘을 공부하기 시작하면서 알게 된 여러 알고리즘의 원리와 Python으로 구현하는 방법에 대해 소개해보려 한다. 필자는 최근 알고리즘 공부를 '나동빈'님의 '이것이 취업을 위한 코딩 테스트다 with 파이썬'이라는 책과 백준 온라인 저지 사이트로 하고 있다. 이 중 '나동빈'님이 저자이신 책에서 가르쳐주는 내용을 기반으로 배운 내용을 정리해보려 한다.
이번 포스팅에서는 최소 신장 트리를 찾는 데 사용되는 알고리즘 중 하나인 크루스칼(Kruskal) 알고리즘에 대해 알아보려고 한다. 해당 알고리즘을 이해하기 위해서는 신장 트리라는 개념이 선행되어야 하므로 신장 트리에 대한 개념을 먼저 소개한 뒤 크루스칼 알고리즘에 대해 알아보고 Python으로 구현하는 소스코드도 살펴보자.

포스팅 본론에 들어가기에 앞서 최소 신장 트리를 찾는 크루스칼 알고리즘을 온전히 이해하기 위해서는 저번에 배웠던 서로소 집합 자료구조의 Find, Union 연산에 대해 필수적으로 알아야 한다. 따라서 해당 개념에 대해 아직 잘 모른다면 여기를 방문해 선 개념을 숙지하고 오도록 하자.
1. 신장 트리란?
신장 트리는 기본적으로 그래프 알고리즘 문제로 자주 출제되는 문제 유형이다. 신장 트리란, 하나의 그래프가 있을 때, 모든 노드를 포함하면서 즉, 모든 노드들 간에 서로 연결은 되어있되 사이클이 존재하지 않는 '부분' 그래프를 의미한다. 예를 들어, 다음과 같은 그래프 G가 있을 때, 이 G 그래프에서 가능한 신장 트리(Spanning Tree)는 아래와 같다.

즉, A, B, C 노드들 간에 서로 연결은 되어 있되, 자기 자신으로 돌아오는 간선이 있는 사이클이 존재해서는 안된다. 이럴 때 우리는 신장 트리라고 한다. 신장 트리들은 원본 그래프 G의 '부분' 그래프임을 잊지말자.
2. 최소 신장 트리? 크루스칼 알고리즘?
문두에서 크루스칼 알고리즘이 최소 신장 트리를 찾는 알고리즘이라고 했다. 우선 최소 신장 트리란 무엇일까? 아래와 같이 원본 그래프에서 가능한 신장 트리들이 다음과 같이 있다고 가정해보자.

위 그림을 보면 원본 그래프 Graph에서 나올 수 있는 신장 트리는 2가지이다. 파란색, 빨간색 점으로 각각 이루어진 그래프들이다. 이 때, 한 가지 추가적으로 주어져야 하는 정보가 있어야 하는데, 바로 노드들 간의 간선(edge) 비용이 있어야 한다. 여기서 조심스레 추측해볼 수 있는데, 최소 신장 트리의 '최소'가 바로 간선 비용이 '최소'가 되는 신장트리이다. 다시 말해, 원본 그래프인 Graph에서 신장 트리를 만들 수 있는 경우의 수들 중 최소의 간선 비용을 들여서 만들 수 있는 신장트리를 최소 신장 트리라고 한다.
위 그림을 예시로 들어보면, 파란색 점으로 이루어진 신장 트리를 만드는 데는 비용(Cost)이 13이 든다. 반면에, 빨간색 점으로 이루어진 신장 트리를 만드는 데는 비용이 7이 든다. 이 때, 7이 13보다 작으므로 빨간색 점으로 이루어진 신장 트리를 만드는 데 더 최소 비용이 들게 되고 결국 최소 신장 트리는 빨간색 점으로 이루어진 그래프라고 할 수 있다.
그리고 이렇게 최소 신장 트리를 효율적으로 찾아낼 수 있는 알고리즘 방법론들 중 하나가 바로 크루스칼 알고리즘이라는 것이다. 그렇다면 크루스칼 알고리즘은 어떻게 효율적으로 최소 신장 트리를 찾아낼 수 있을까?
3. 크루스칼 알고리즘의 동작 과정
크루스칼 알고리즘은 가장 적은 간선 비용으로 모든 노드를 연결할 수 있도록 하는데, 이런 측면에서 그리디 알고리즘으로 분류되기도 한다. 어쨌건 크루스칼 알고리즘의 동작 과정을 단계화시키면 다음과 같다.
- 주어진 모든 간선 정보에 대해 간선 비용이 낮은 순서(오름차순)로 정렬을 수행
- 정렬된 간선 정보를 하나씩 확인하면서 현재의 간선이 노드들 간의 사이클을 발생시키는지 확인
- 만약 사이클이 발생하지 않은 경우, 최소 신장 트리에 포함시키고 사이클이 발생한 경우, 최소 신장 트리에 포함시키지 않음
- 1번~3번의 과정을 모든 간선 정보에 대해 반복 수행
위 단계를 살펴보면 노드들 간의 사이클이 발생하는지 여부에 따라 최소 신장 트리로 포함시킬지 여부를 결정하는 것을 볼 수 있다. 노드들 간의 사이클이 발생하는지 여부는 노드들의 부모노드가 같다면 사이클이 발생, 같지 않다면 사이클이 발생하지 않음을 의미한다. 왜 그런지에 대해서는 문두에서 언급한 것처럼 서로소 집합 자료 구조 포스팅에서 배웠으므로 해당 포스팅에서는 다루지 않겠다.
이제 아래와 같이 그래프 정보가 주어졌다고 가정했을 때, 최소 신장 트리를 찾는 크루스칼 알고리즘 과정을 단계별로 도식화해서 살펴보자. 초기 단계는 주어진 간선 정보를 오름차순으로 정렬한 이후 상태라고 가정하겠다.(참고로 최종 결정된 최소 신장 트리에 포함되는 간선의 개수는 항상 노드의 총 개수 - 1($V-1$) 이라는 특징을 갖고 있다. 어쨌건 신장 트리도 일종의 트리 자료 구조이므로 동떨어져 있는 노드는 없을 것이라고 가정하기 때문이다.)

부모 테이블은 간선 정보를 받기 전에는 자기 자신을 부모노드로 하도록 값을 초기화시킨 상태다. 이제 정렬된 간선 정보에서 앞에 순서대로 하나씩 받아서 처리해보자.
3-1. 첫 번째 Union 연산
처음 간선 정보는 (3, 4)의 비용이 7이다. 부모 테이블로 가서 3번, 4번 노드의 부모노드를 각각 확인한다. 3번, 4번의 부모노드는 현재 각각 자기 자신인 3번, 4번이다. 두 부모노드가 서로 다르다. 사이클이 발생하지 않는다. 그러므로 최소 신장트리에 포함하기로 한다. 또한 노드 번호가 3 < 4 이기 때문에, 부모 테이블의 4번 노드의 부모노드 값을 3으로 바꿔준다. 업데이트 된 내용은 아래와 같다.
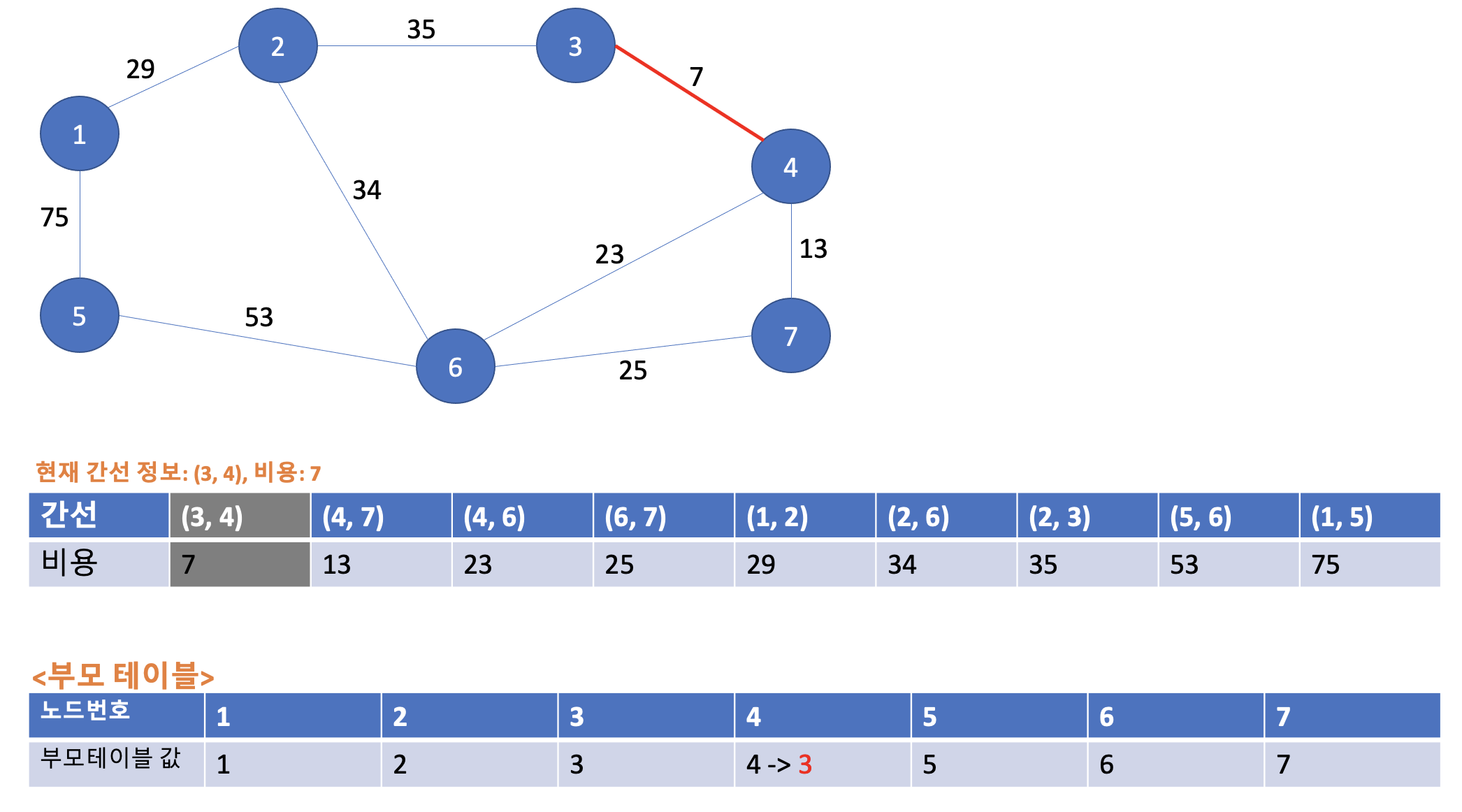
3-2. 두 번째 Union 연산
두 번째 간선 정보는 (4, 7)의 비용이 13이다. 부모 테이블로 가서 4번 노드의 부모노드는 3이고 7번 부모노드는 7이라는 걸 확인했다. 두 부모노드가 서로 다르므로 사이클이 발생하지 않는다. 그러므로 최소 신장 트리에 포함시켜준다. 또한 3 < 7 이므로 7번노드 -> 4번 노드로 연결해주고 부모테이블 7번 노드의 값을 3으로 아래와 같이 업데이트 해준다.
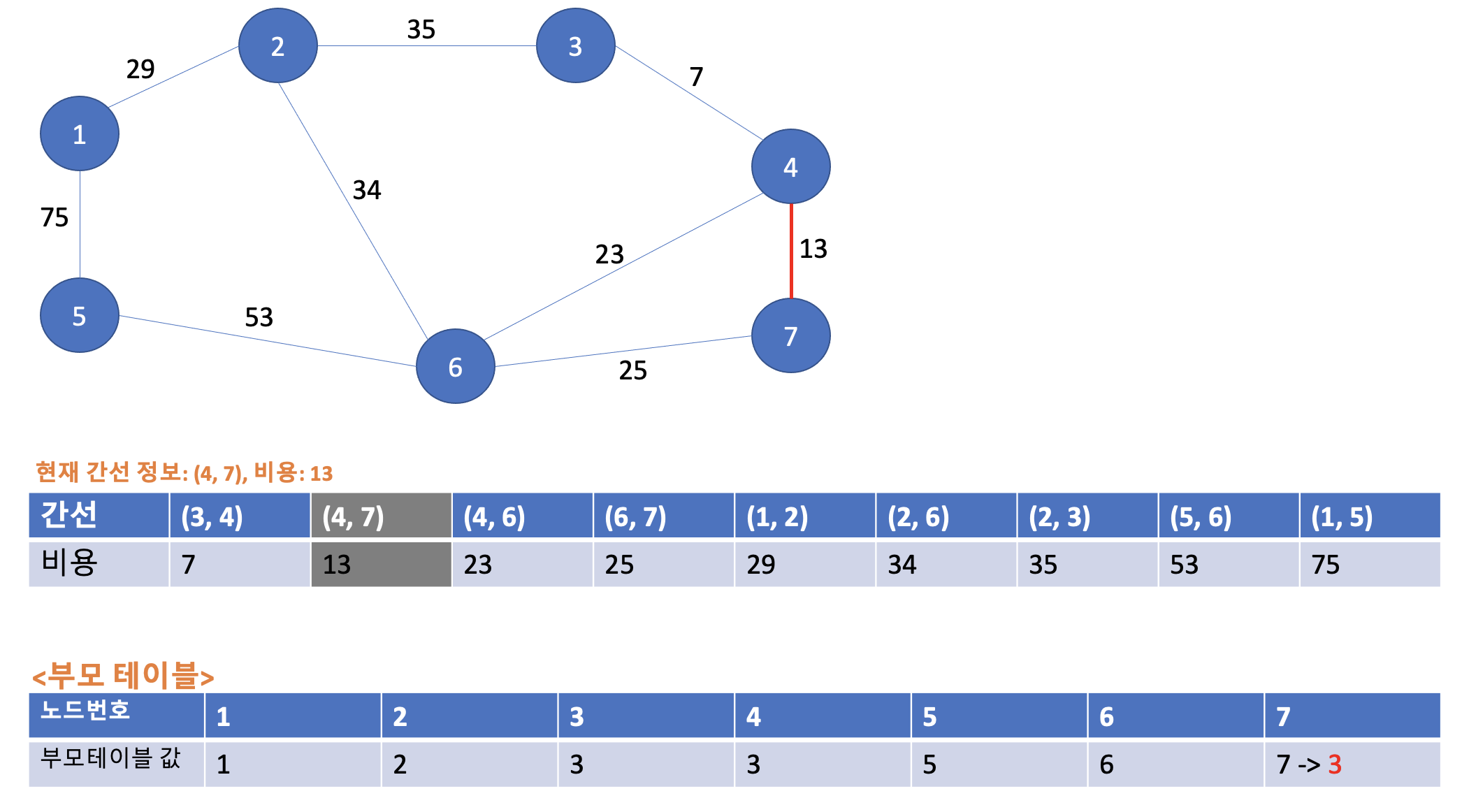
3-3. 세 번째 Union 연산
다음은 (4, 6)의 23이다. 4번, 6번 부모노드 값은 각각 3, 6이다. 두 부모노드가 서로 다르니 사이클이 발생하지 않는다. 그러므로 최소 신장 트리에 포함시킨다. 또한 각 부모노드 값이 3, 6인데 3 < 6 이므로 6번 노드 -> 4번 노드로 연결을 해준다. 부모테이블 6번 노드의 값을 3으로 다음과 같이 업데이트 해준다.
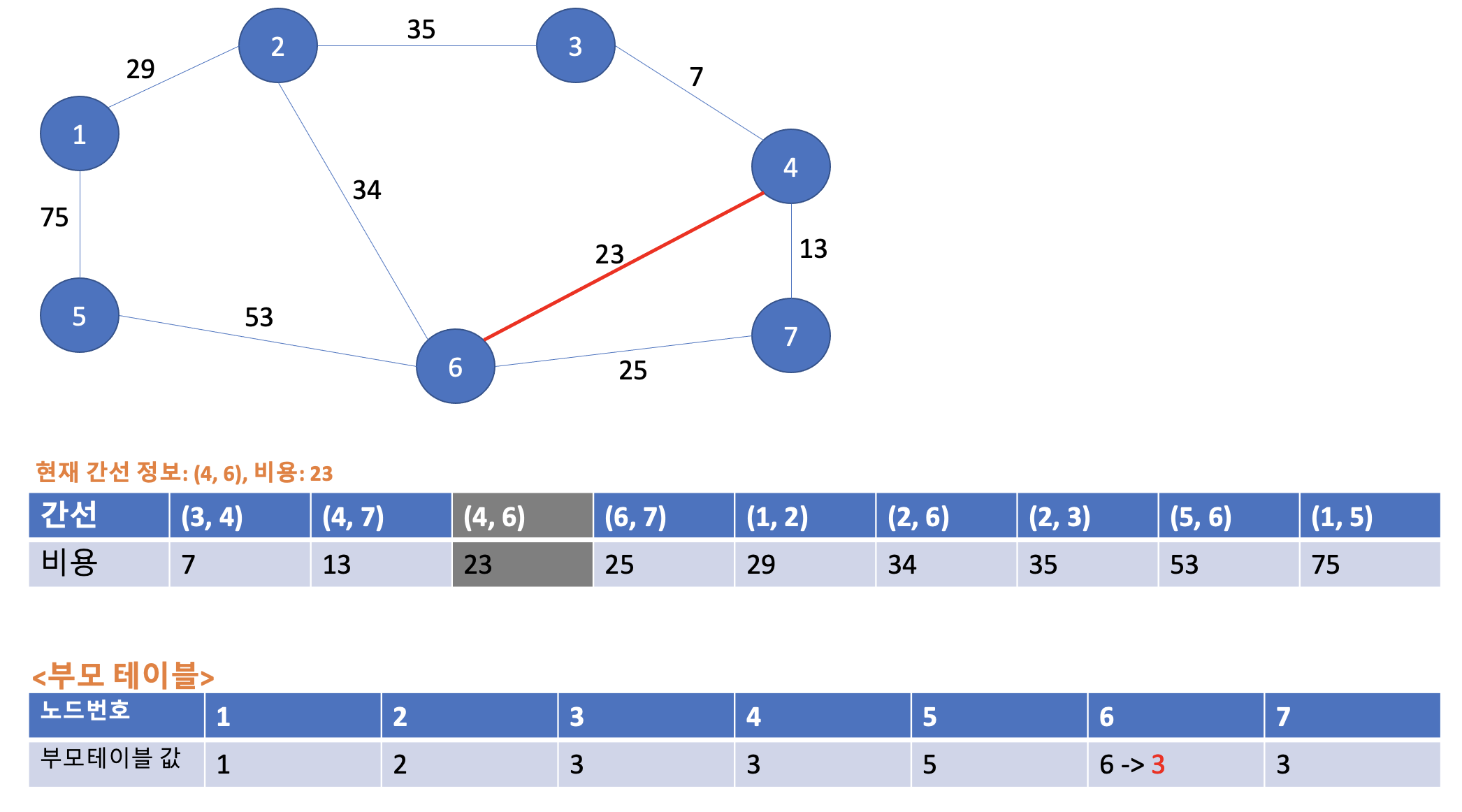
3-4. 네 번째 Union 연산
다음은 (6, 7)의 25이다. 6번, 7번의 각 부모노드를 부모 테이블에서 찾아보면 3, 3으로 부모 노드가 같다. 따라서 사이클이 발생했다. 그러므로 해당 간선은 최소 신장트리에 포함시키지 않고 부모 테이블도 업데이트 해줄 필요가 없다. 여기서 잠깐 중간점검을 해보자. 네 번째 Union 연산까지 진행하면서 최소 신장트리에 포함시킨 간선을 보라색으로 표현하면 다음과 같다. 참고로 파선은 사이클이 발생해 무시한 간선이다.
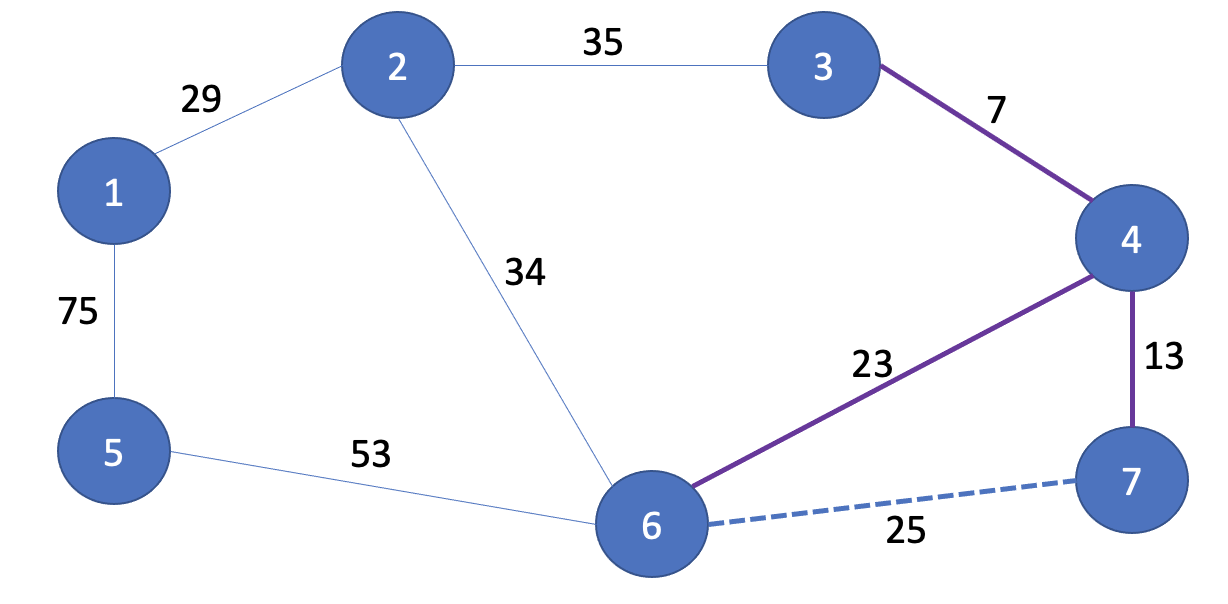
3-5. 다섯 번째 Union 연산
이제 다섯 번째 연산은 (1, 2)의 29이다. 1번, 2번의 각 부모노드는 1, 2이다. 부모노드가 서로 다르므로 사이클이 발생하지 않는다. 그러므로 해당 간선은 최소 신장트리에 포함시킨다. 또한 부모노드 값이 1 < 2 이므로 2번 노드 -> 1번 노드 연결하면 아래와 같이 부모 테이블 값이 업데이트 된다.
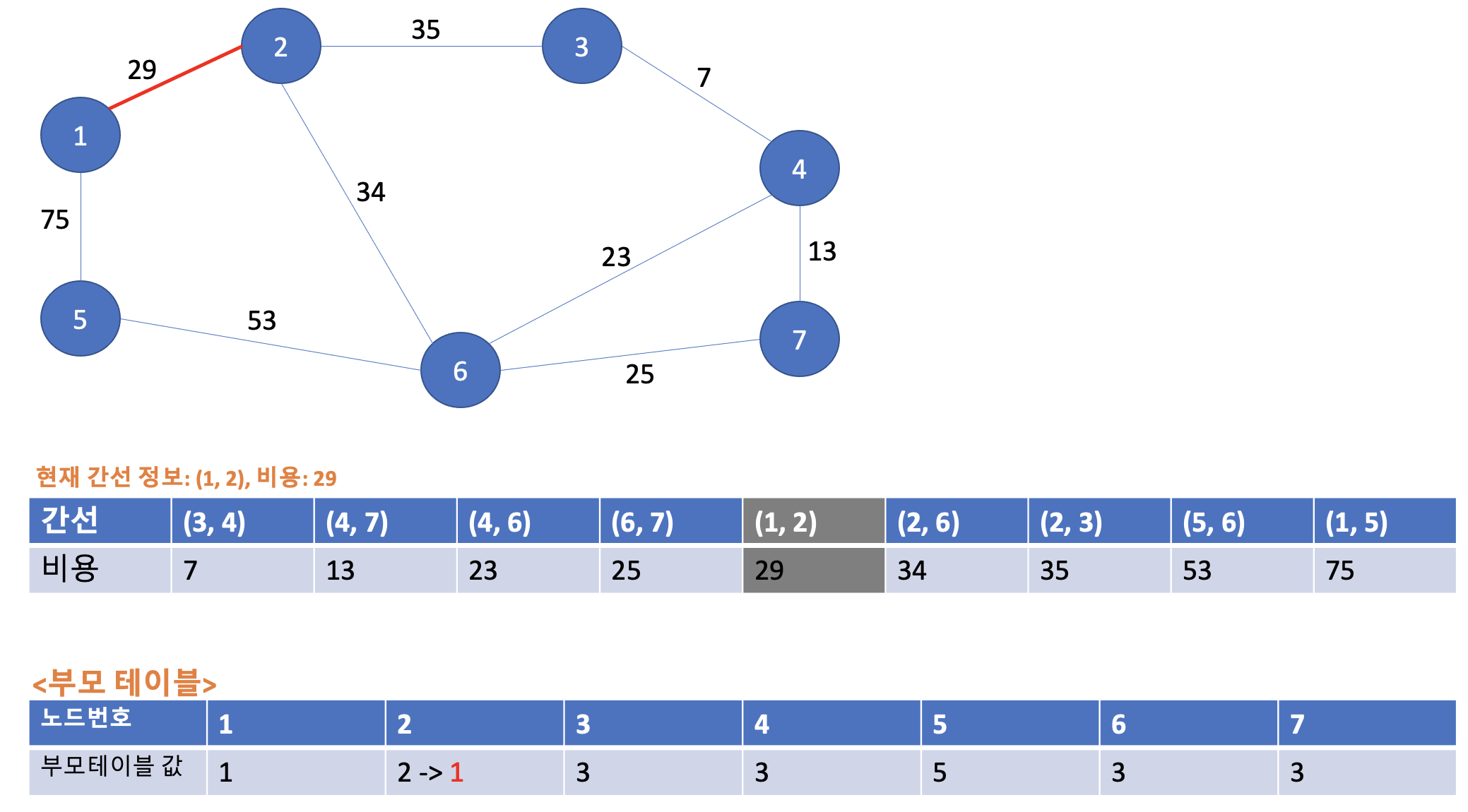
3-6. 여섯 번째 Union 연산
다음 연산은 (2, 6)의 34이다. 2번, 6번 노드의 부모노드는 각각 1, 3이다. 부모노드가 서로 다르므로 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 포함시킨다. 또한 부모노드 값이 1 < 3 이므로 6번 노드 -> 2번 노드 연결을 해준다. 부모 테이블의 값은 아래와 같이 업데이트 된다. 참고로 6번 노드의 부모노드가 3에서 1로 바뀌었으므로 연쇄적으로 부모 노드를 3으로 가리키던 3,4,7번의 부모노드가 1로 바뀌게 되는 점을 기억하자!(오류 댓글 피드백 덕분에 배워갑니다. 감사합니다 :) )
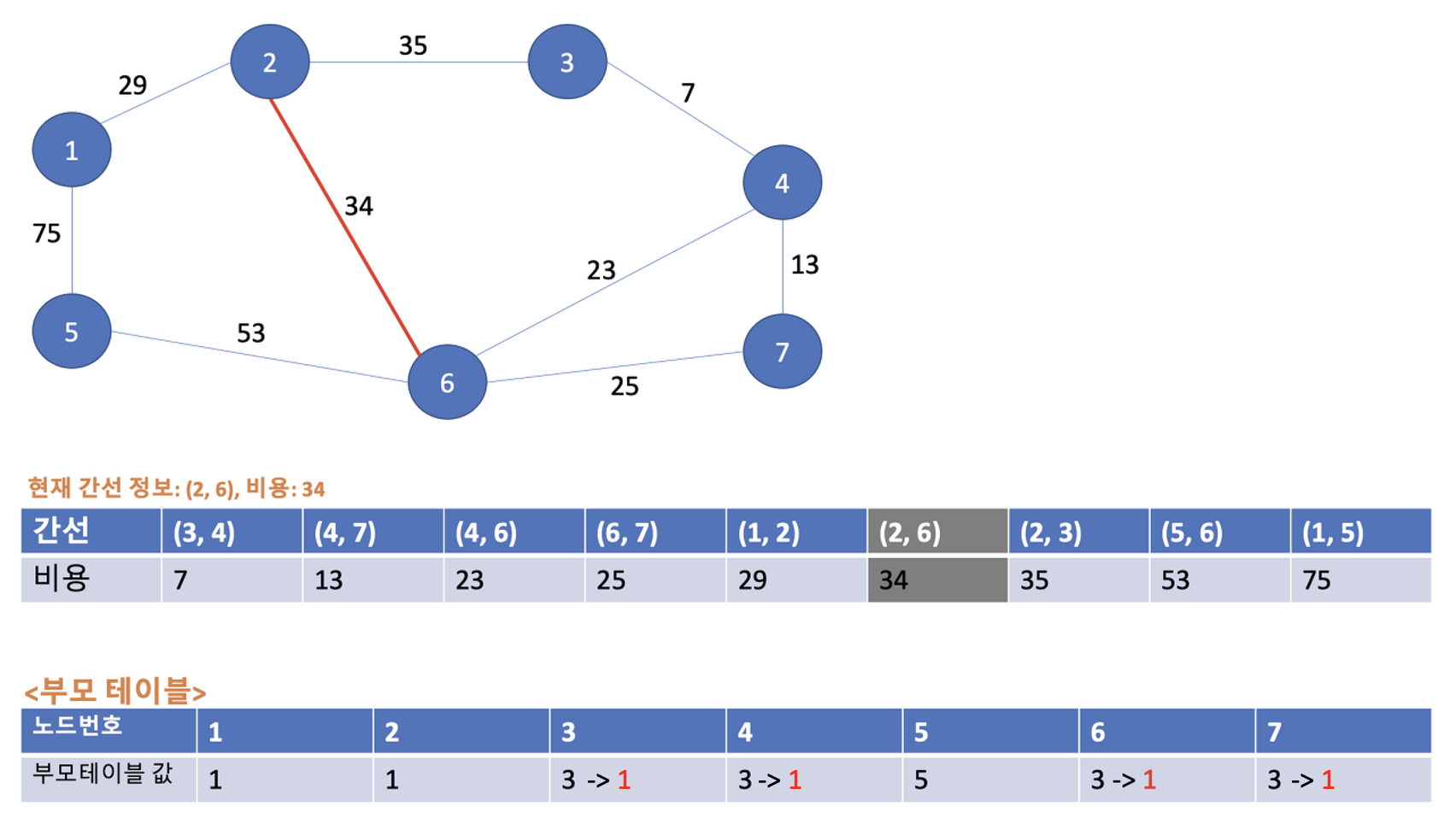
3-7. 일곱 번째 Union 연산
다음은 (2, 3)의 비용 35이다. 2번, 3번 노드의 각 부모노드 값은 1로 동일하다. 부모노드들이 동일하므로 사이클이 발생하기 때문에 최소 신장 트리에 포함시키지 않는다.
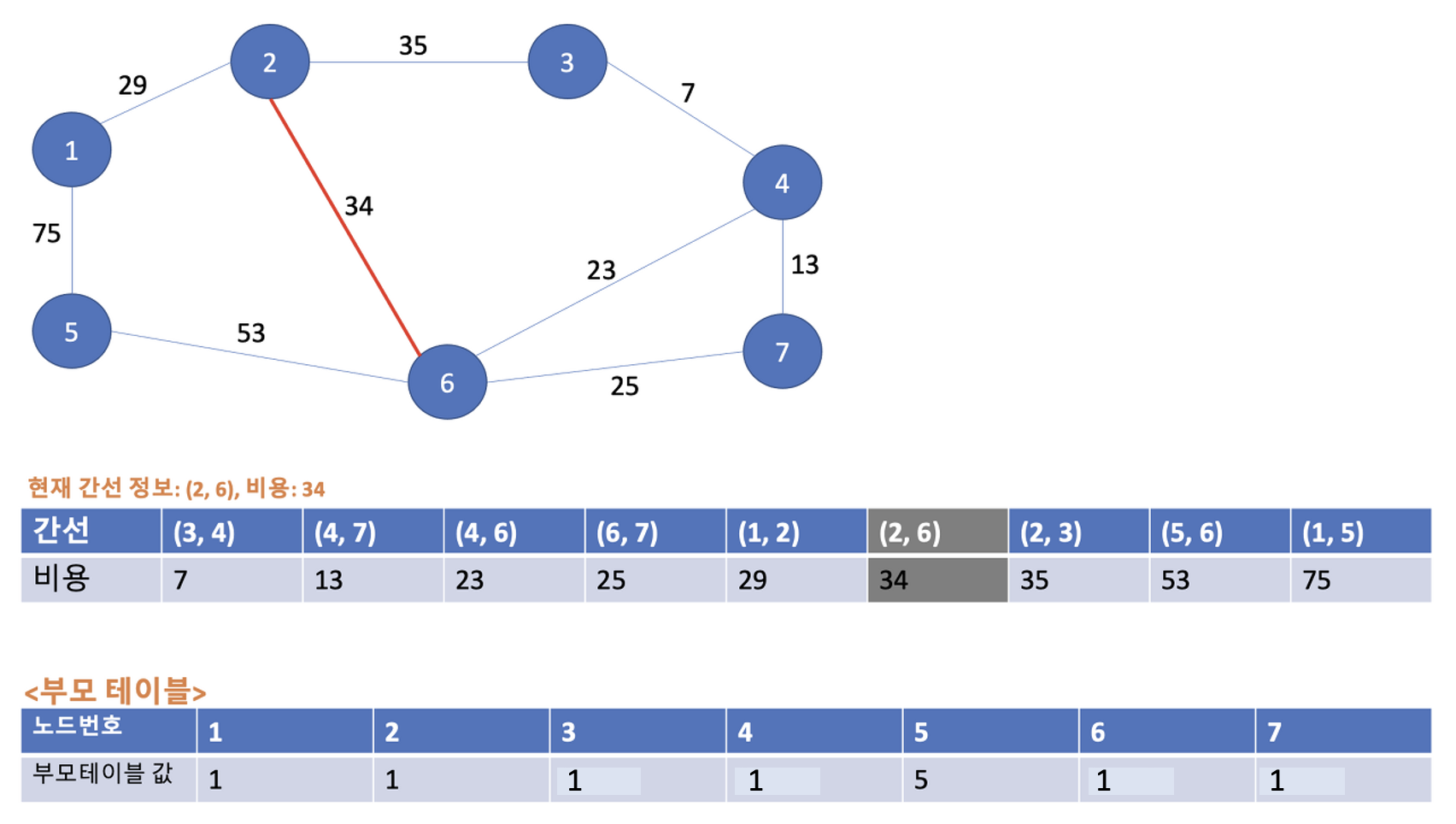
3-8. 여덞번째 Union 연산
다음은 (5, 6)의 53이다. 5번 노드와 6번 노드의 부모 노드들은 각각 5와 1이다. 부모노드들이 서로 다르므로 사이클이 발생하지 않는다. 그래서 최소 신장 트리에 포함시켜준다. 또한 부모노드 값이 5 < 1 이므로, 부모노드 값이 1인 5번 노드 -> 부모노드 값이 1인 6번 노드로 연결해주며 부모 테이블은 아래와 같이 업데이트 된다.
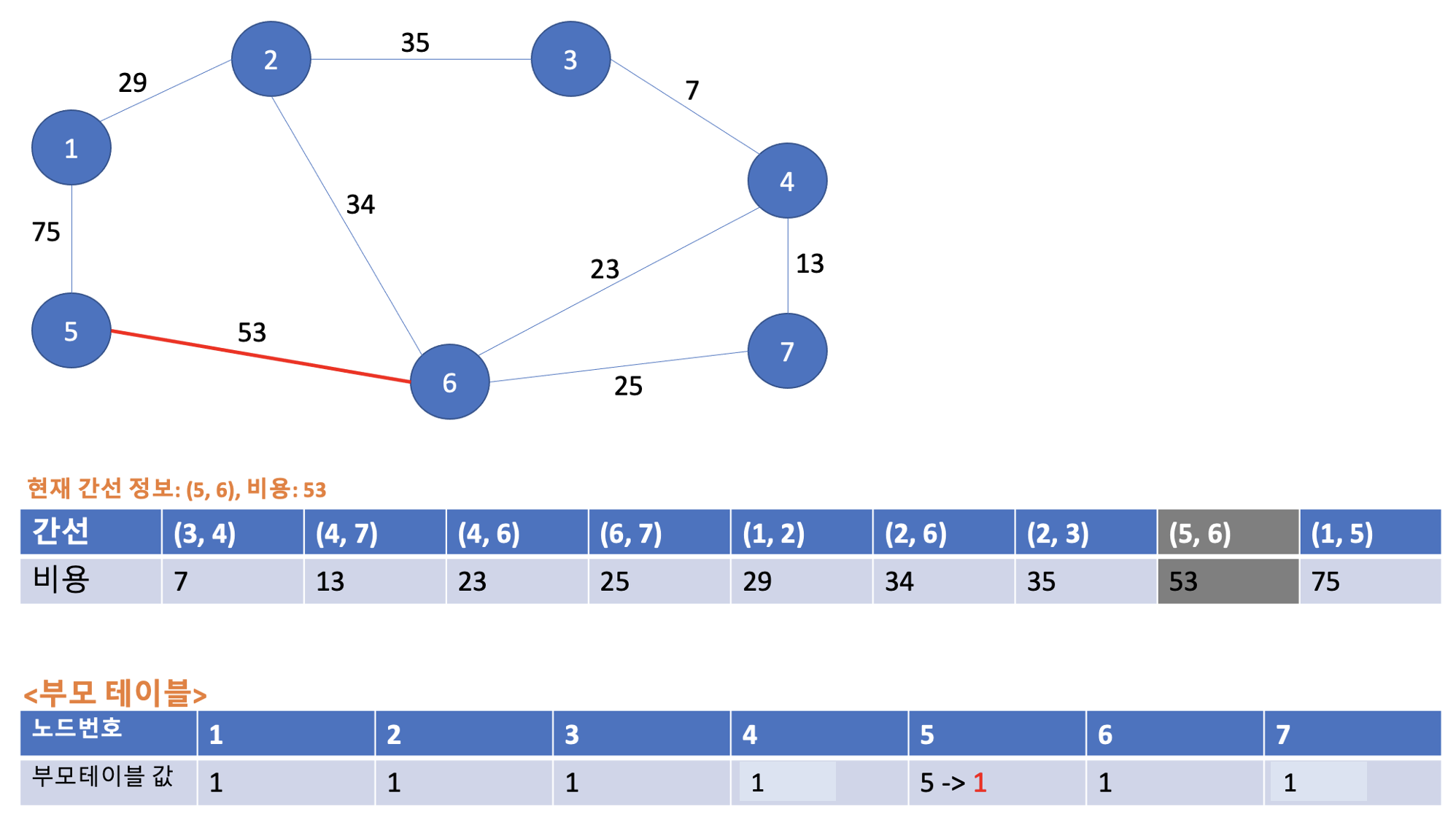
3-9. 아홉번째 Union 연산
드디어 마지막 연산인 (1, 5)의 75이다. 1번 노드, 5번 노드의 각 부모노드는 모두 1로 동일하다. 따라서 사이클이 발생하며 최소 신장 트리에 포함시키지 않는다. 또한 부모테이블 값도 업데이트 하지 않는다.
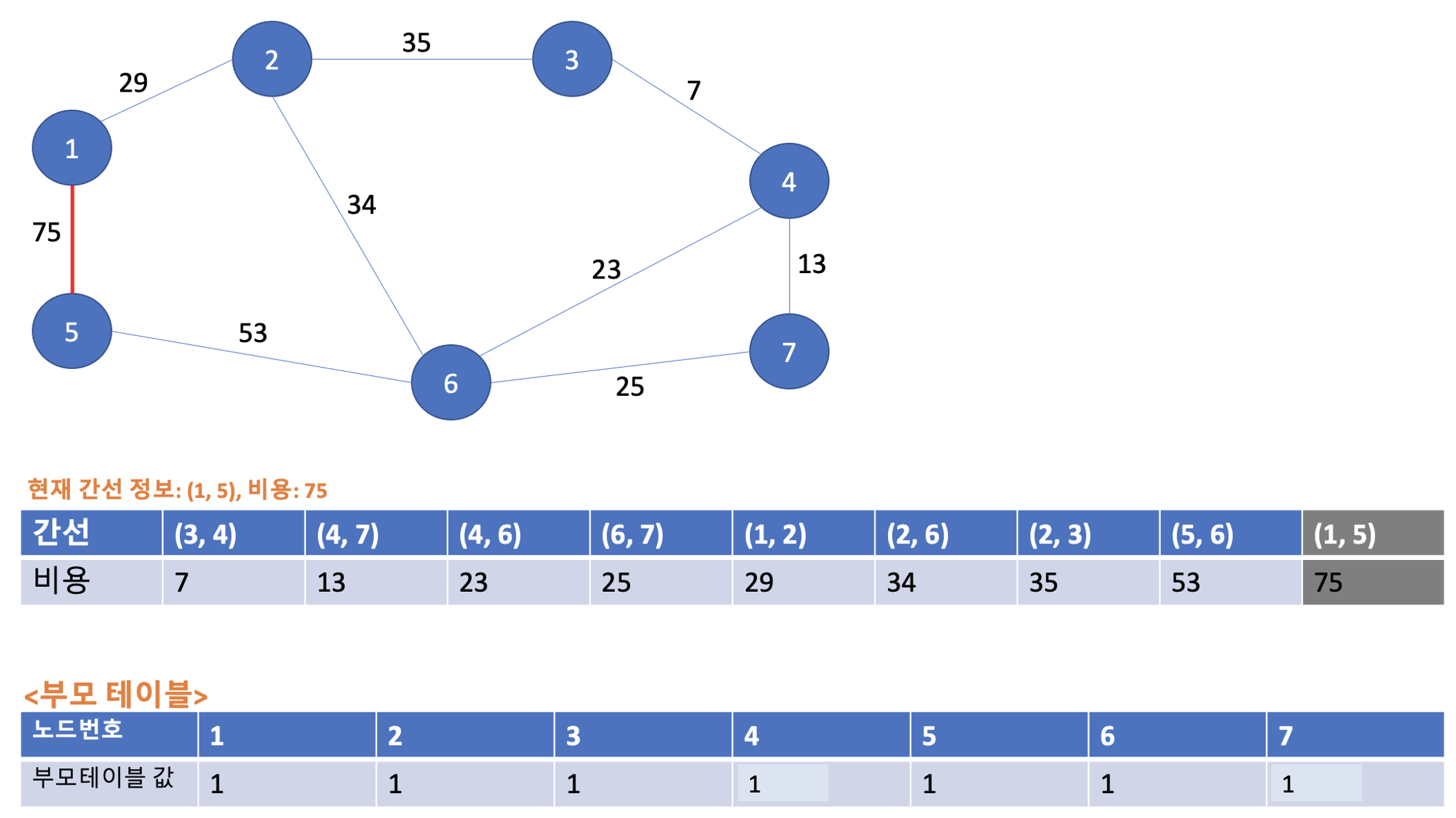
모든 주어진 Union 연산들이 완료되었다. 이제 최소 신장트리에 포함되었던 간선만을 보라색으로 칠하게 되면 다음과 같은 최소 신장 트리가 도출된다.
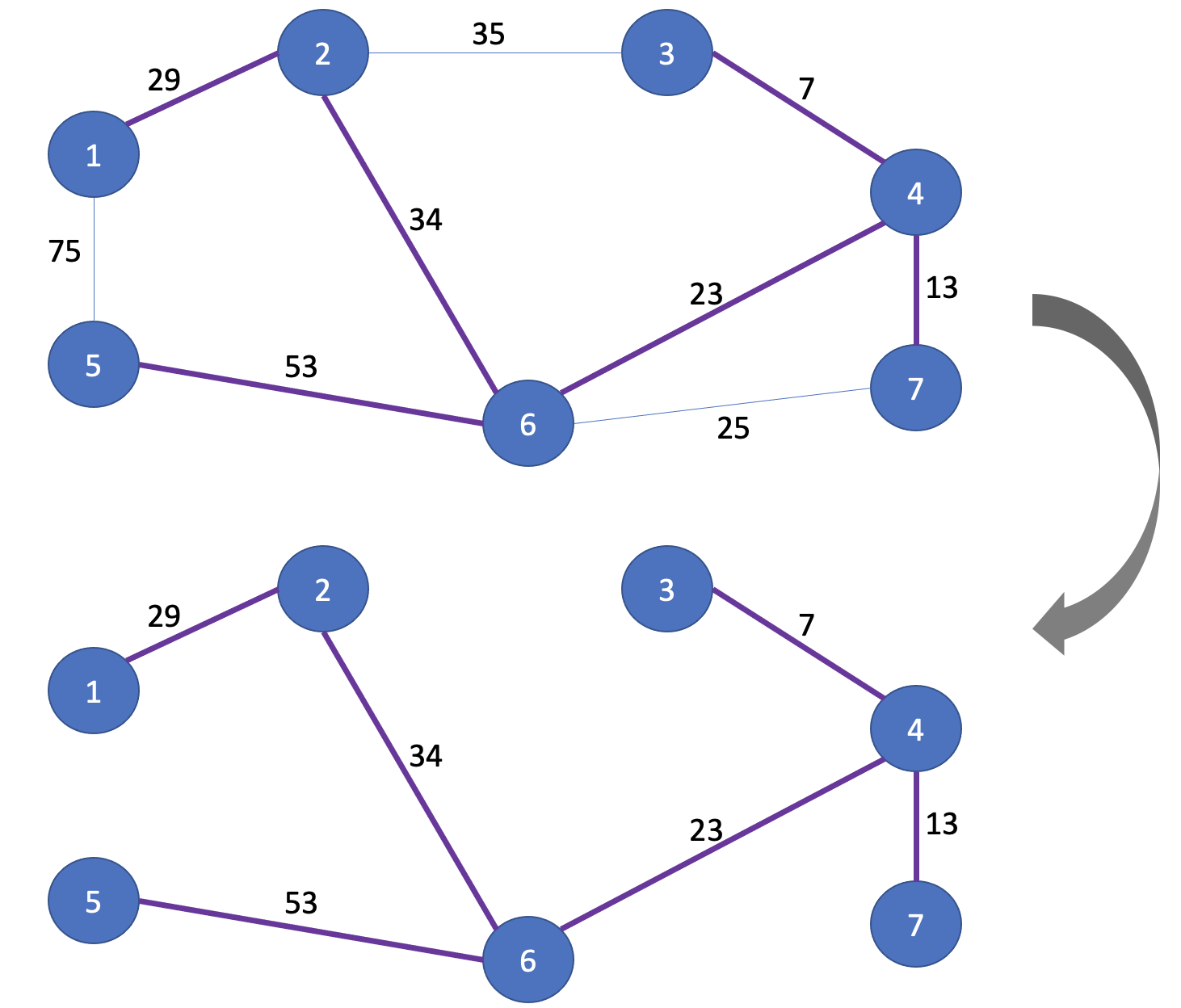
위와 같이 최소 신장트리가 완성되었다. 이제 최소 신장트리에 포함되어 있는 간선 비용들만 합치면 그 값이 최소 신장 트리를 만드는 데 드는 총 비용을 의미한다. 이제 크루스칼 알고리즘 개념에 대해 알아보았으니 Python으로 구현하는 코드를 살펴보자.
4. 크루스칼 알고리즘을 Python으로 구현하기
크루스칼 알고리즘 소스코드는 서로소 집합 자료구조를 공부할 때 활용한 Union, Find 연산, 사이클 판별 로직을 활용하면 생각보다 간단하게 구현할 수 있다.
import sys
v, e = map(int, input().split())
# 부모 테이블 초기화
parent = [0] * (v+1)
for i in range(1, v+1):
parent[i] = i
# find 연산
def find_parent(parent, x):
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
# union 연산
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
# 간선 정보 담을 리스트와 최소 신장 트리 계산 변수 정의
edges = []
total_cost = 0
# 간선 정보 주어지고 비용을 기준으로 정렬
for _ in range(e):
a, b, cost = map(int, input().split())
edges.append((cost, a, b))
# 간선 정보 비용 기준으로 오름차순 정렬
edges.sort()
# 간선 정보 하나씩 확인하면서 크루스칼 알고리즘 수행
for i in range(e):
cost, a, b = edges[i]
# find 연산 후, 부모노드 다르면 사이클 발생 X으므로 union 연산 수행 -> 최소 신장 트리에 포함!
if find_parent(parent, a) != find_parent(parent, b):
union_parent(parent, a, b)
total_cost += cost
print(total_cost)'Python > 알고리즘 개념' 카테고리의 다른 글
| [Python] 알아두면 좋을 기타 알고리즘 (0) | 2021.10.02 |
|---|---|
| [Python] 노드 간의 선후 관계를 고려하는 위상(Topology) 정렬 알고리즘 (0) | 2021.09.30 |
| [Python] 그래프 알고리즘 - 서로소 집합 자료구조 (5) | 2021.09.27 |
| [Python] 모든 지점에서의 최단경로를 찾는 플로이드 워셜(Floyd-Warshall) 알고리즘 (0) | 2021.09.24 |
| [Python] 우선순위 큐를 활용한 개선된 다익스트라(Dijkstra) 알고리즘 (6) | 2021.09.23 |



