이번 포스팅에서는 추천 시스템 종류 중 하나인 Factorization Machine 이른바 FM이라 불리는 모델에 대해 알아보려고 한다. 참고로 이 FM 모델에 딥러닝을 적용한 모델이 Deep FM이라는 추천 시스템이고 이에 대해서는 추후에 다루어 보려고 한다. 우선 FM이라는 구조에 대해 이해가 선행되어야 나중에 배울 Deep FM에 대한 이해도 수월할 것이다. FM에 대해 처음 소개된 논문은 여기를 참고하자.

Factorization은 추천 시스템에 있어서 행렬 분해라는 것은 익히 들었을 것이다. 기존에 배웠던 협업 필터링 추천 시스템에서 잠재 요인 기반이라는 추천 시스템은 SVD, PCA같은 행렬 분해 기법을 사용했었다. 그렇다면 앞으로 소개할 FM은 어떤 것을 '분해' 한다는 것일까?
1. FM의 핵심, 데이터 포맷의 변경
FM은 기존에 배웠던 MF(Matrix Factorization) 모델처럼 User-Item 행렬의 데이터를 사용하지 않는다. FM은 데이터프레임 중 하나의 row는 User 정보, item 정보, 기타 정보를 쭉 펼치고 Target 값 하나로 구성된다. 바로 다음과 같이 말이다.


이제 FM은 위와 같이 새로운 데이터 포맷의 형태를 인풋 데이터로 받는다는 점을 인지하고 다음 목차를 읽어내려가자.
2. 선형회귀, 다항회귀의 한계
갑자기 선형회귀라는 키워드가 등장했다. 우선 우리 대부분이 익숙하게 잘 알고 있는 선형회귀식을 FM 추천시스템의 데이터 포맷과 대응시켜보자. 추천 시스템도 하나의 선형회귀식이라고 할 수 있다. User 정보, item 정보, 기타 정보 등을 Feature로 넣어준다고 생각하고 추천 시스템의 선형회귀식을 나타내면 다음과 같을 수 있다.
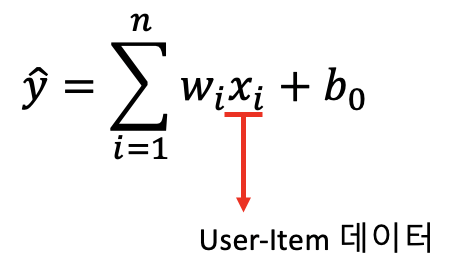
그런데 추천 시스템의 User-Item 데이터는 결측값이 많은 즉, 매우 Sparse한 행렬이여서 고차원의 데이터가 된다. 그렇기 때문에 선형함수로 데이터를 설명하는 데 한계가 존재한다. 또한 User, Item 간 잠재적인 관계를 파악하지 못한다. 그래서 우리는 선형회귀를 다항회귀식으로 다음과 같이 바꿀 수 있다.

위 수식에서 $x_i$와 $x_j$는 FM에 맞는 데이터프레임에서 하나의 row들이라고 할 수 있다. 예를 들면 다음과 같은 형태를 의미한다.

위 처럼 $x_i$ row와 $x_j$ row 간의 Weight를 곱해주어 row들 간의 관계를 파악할 수 있게 하도록 한다. 그러나 문제는 다항회귀식을 이용하면 파라미터 수가 기하급수적으로 증가해 연산량 문제가 발생한다. 이 때, 이를 해결하기 위해 드디어 FM에서 '분해' 과정을 수행한다.
3. FM, 분해하자!
위에서 보았던 다항회귀식에서 $w_{ij}x_ix_j$를 SVD와 같은 기법으로 분해한다고 해보자. 그렇게 되면 수식이 다음과 같이 변형된다.

위 수식에서 $v_i$, $v_j$를 보면 $w_{ij}$ 가 두 개의 벡터로 분해되어 내적하는 것으로 바뀐 것을 볼 수 있다. 결국 분해 기법을 사용해서 $x_i$ 와 $x_j$ 간의 잠재적인 특성을 파악하는 것이 가능해졌다. 뿐만 아니라 위와 같은 수식으로 바꾸어주면 연산 복잡도가 Linear(선형)하게 유지된다는 장점도 있는데, 이에 대해서는 참고 블로그를 보는것이 더 나을 것 같다.
이제 FM에 대해 간략하게 알아본 개념을 가지고 추후에 소개될 Deep FM에 대해 이해해보자.
'Data Science > 추천시스템과 NLP' 카테고리의 다른 글
| [추천시스템] 딥러닝과 FM, Deep FM(Factorization Machine) (0) | 2021.08.25 |
|---|---|
| [추천시스템] 딥러닝과 추천시스템, Wide & Deep Learning (0) | 2021.08.25 |
| [추천시스템] 딥러닝과 추천시스템, Neural CF(Collaborative Filtering) (0) | 2021.08.21 |
| [추천시스템] Cold Start 문제는 어떻게 해결할까? (0) | 2021.02.25 |
| [추천시스템] 추천 시스템의 성능은 어떻게 평가할까? (0) | 2020.11.20 |



