🔊 이번 포스팅에서는 추천시스템의 고질적인 문제점이라고 할 수 있는 Cold Start 문제가 무엇이고 어떤 원인으로 발생하며 이에 대한 해결책들도 몇가지 소개해보려 한다. 해당 글에서는 코드로 구현되는 실용적인 내용이 아닌 주로 이론적인 내용을 소개하려고 한다.
참고로 이 글을 작성하기 위해서 Cold Start에 대한 Wikipedia 문서를 나만의 방법으로 해석하여 한국인들이 이해하기 쉽도록 하기 위해 작성되었다. 기타 참고 문헌은 글의 하단에 첨부했다. 목차는 다음과 같다.
1. Cold Start란?
2. Cold Start가 발생하는 3가지 원인
3. Cold Start를 해결하는 방법
1. Cold Start란?
Cold Start란, 추천 시스템이 새로운 또는 어떤 유저들에 대한 충분한 정보가 수집된 상태가 아니라서 해당 유저들에게 적절한 제품을 추천해주지 못하는 문제를 말한다.
추천 시스템은 보통 서비스에 가입된 유저의 프로필을 몇 가지의 래퍼런스 특성들과 비교한다. 여기서 레퍼런스 특성들이라고 한다면 아이템의 특성과 사용자의 특성으로 나눌 수 있다. 먼저 아이템의 특성인 경우, Contents-based filtering(컨텐츠 기반 필터링) 이며 사용자의 특성(사회적 환경이나 유저의 과거 행동)인 경우에는 Collaborative-based filtering(협업 기반 필터링)이라고 할 수 있다.
물론 각 기업마다 적용하고 있는 추천 시스템에 따라 다르겠지만 사용자들의 주로 제품들에 대한 평점, 북마크, 구입 이력, 좋아요 이력, 특정 사이트 방문 횟수 등과 같은 일종의 인터렉션 정보들을 이용한다.

2. Cold Start가 발생하는 3가지 원인
이 문제가 발생하는 이유는 크게 3가지가 존재한다.
2-1. New Community
여기서 새로운 커뮤니티란, 하나의 회사나 서비스가 설립되고 운영되기 시작한 것이라고 볼 수 있다. 예를 들어, 어떤 서비스가 운영되기 시작했을 때 해당 서비스를 이용하는 유저들은 단 1명도 없을 것이다. 물론 서비스에 이미 판매하는 제품들의 카탈로그와 같은 것들이 존재하더라도 이 제품들에 대한 유저들의 인터렉션 정보들이 없기 때문에 Cold Start 문제가 필연적으로 발생한다.
2-2. New item
신제품이 출시된 경우에는 사용하는 추천 시스템의 종류에 따라 Cold Start 문제 발생 경향이 달라지기도 한다. 우선 협업 필터링부터 살펴보자.
협업 필터링은 적절한 제품을 추천해주기 위해 제품에 대한 유저의 인터렉션에 주로 의존하게 된다. 그런데 신규 제품이 출시되었을 때, 신규 제품에 대한 유저들의 인터렉션 정보는 아예 없기 마련이다. 설사 정보가 조금 있더라도 이를 기반으로 협업 필터링 추천 시스템을 만들게 된다면 추천의 퀄리티가 낮아지게 된다. 따라서 협업 필터링의 추천 시스템인 경우, Cold Start 문제에 매우 민감하다. 그래서 신규제품이 나오게 되면 실제로는 정말 좋은 제품이라도 인기없는 제품들로 치부되어 사람들에게 잘 추천되지 않는 경우가 발생한다. 이러한 경우를 인기있는 아이템은 극소수라 하여 Popularity bias 또는 Long tail graph라고 하기도 한다.

반대로 컨텐츠 기반 필터링에서는 신제품이 출현했을 때 Cold Start 문제에 걸리는 경향이 상대적으로 덜하다. 왜냐하면 컨텐츠 기반 필터링은 제품에 대한 유저의 인터렉션 정보를 기반으로 하지 않고 제품 자체의 특징(feature)을 기반으로 추천해주는 시스템이기 때문이다. 그래서 신제품이 등장했을 때, 컨텐츠 기반 필터링은 신제품 자체의 특징을 파악해 기존의 제품들과 유사도를 측정해서 추천해줄 수 있다.
하지만 컨텐츠 기반 필터링도 만약 유저에서 도출된 특징을 기반으로 구현되었다면 Cold Start 문제에 빠질 가능성이 높다. 예를 들면 제품에 대한 유저의 리뷰 텍스트, 태그 텍스트와 같은 특징들로 컨텐츠 기반 필터링을 구현할 경우이다.
2-3. New User
새로운 유저가 가입했을 때이다. 이 경우 신규 유저에 대한 히스토리가 없기 때문에 Cold Start 문제가 주로 발생한다. 보통은 이 문제를 막기 위해 신규 유저의 초기 프로필(Initial Profile)을 작성하도록 하면서 그 신규 유저의 기호(Preference)가 무엇인지 파악한다. 하지만 이 때 초기 프로필 작성 시 시간이 많이 소요된다거나 하는 요소로 인해 유저들의 귀찮음을 유발하게 되면 오히려 잘못된 정보가 기입되거나 유저들이 그냥 넘겨버리는 경우가 많다.
새로운 유저가 들어왔을 때 발생하는 Cold Start 문제에 대해서도 추천 시스템의 종류에 따라 약간 다르게 대응을 해야 한다.
우선 컨텐츠 기반 필터링 중 아이템 기반인 Item-Item 추천 시스템은 신규 유저가 다른 유저의 기호들과 얼마나 관련성이 있는지 파악을 해야한다. 그래서 제품들에 대한 신규 유저의 기호인 인터렉션 정보를 파악해야만 하는데 신규 유저의 경우 제품들에 대해 평가한 히스토리가 거의 없는 상태이다. 따라서 Item-Item 추천 시스템은 신규 유저가 들어왔을 때 발생하는 Cold Start 문제에 민감하다.
반면 컨텐츠 기반 필터링 중 유저 기반인 User-User 추천 시스템은 상대적으로 Cold Start 문제에 강건하다. 왜냐하면 주로 유저의 특성만을 기반으로 하기 때문이다. 따라서 신규 유저의 초기 프로필만 어느정도 잘 작성이 된다면 이 정보를 이용해 User-User 추천 시스템을 잘 구현해 Cold Start 문제를 잘 해결할 수 있다.
마지막으로 협업 필터링의 경우에는 매우 민감하다. 왜냐하면 제품에 대한 유저의 인터렉션 정보를 기반으로 구현되어야 하기 때문이다. 신규 유저가 들어왔을 때, 인터렉션 정보는 커녕 초기 프로필 정보만 잘 작성해도 성공한 셈이다. 따라서 인터렉션 정보는 절대 얻을 수 없기에 신규 유저가 발생했을 때 협업 필터링의 경우 매우 민감할 수 밖에 없다.
위 3가지 경우를 종합해보았을 때, 신규 유저가 발생했을 경우에는 초기 프로필 정보를 신규 유저가 잘 작성하느냐에 따라 추천 시스템의 퀄리티가 매우 달라지게 된다. 그래서 여러 기업들은 초기 프로필을 어떻게든 완성시키기 위해 신규 유저에게 대놓고 명시적으로 질문지를 던지거나 유저의 연동된 SNS 계정의 프로필 정보를 이용하기도 한다.
3. Cold Start를 해결하는 방법
Cold Start 문제를 해결하는 방법의 큼지막한 프레임은 하이브리드 추천 시스템을 이용하는 것이다. 즉, 기존의 제품 또는 유저(이를 Warm items or users이라고도 함)들에게는 협업 필터링을, 새로운 제품 또는 유저(Cold items or users)에는 컨텐츠 기반 필터링을 수행하는 것이다. 결국 이 유저가 서비스에 진입한지 얼마만큼 되었는지 또는 얼마나의 히스토리를 남겼는지에 따라 추천 시스템 종류를 선택적으로 구현하는 것이다.
하지만 이 방법도 단점이 존재한다. 바로 제품이나 유저의 특성에 대한 전반적인 설명을 파악하기 어려운 상황에서는 컨텐츠 기반 필터링의 추천 퀄리티가 매우 낮아진다는 점이다. 그래서 이를 예방하기 위해 만약 신규 유저의 개인적인 정보들이 입력되어 있지 않거나 제품의 전반적인 설명이 게시되어 있지 않다면 개인화된 추천이 아닌 전체적으로 인기가 많은 제품을 추천해주기도 한다.
3-1. Profile Completion
위에서도 잠깐 언급했지만 Cold Start 문제 해결책 중 하나는 유저의 초기 프로필을 완성시키는 것이다. 그래서 기업들은 유저의 프로필을 완성시키기 위해 앱 서비스 최초 진입시 관심사 키워드를 명시적(Explicit)으로 묻는다거나 앱 내부에서 활동하는 유저의 행동(Implicit)을 관찰하기도 한다. 참고로 이렇게 프로필을 완성시키기 위한 기업의 활동을 Preference Elicitation 이라고도 한다.
유저의 프로필을 완성시키기 위해 주로 던지는 질문지가 따로 있다고 한다. 바로 FFM(Five Factor Model)을 사용하는 것이다. FFM에 관하여 자세한 내용은 여기를 참고하자.
그렇다면 유저의 프로필이 아닌 신규 제품의 프로필은 어떻게 완성시킬까? 여기서 신규 제품의 프로필이란, 신규 제품에 대한 사용자들의 평가, 평점을 의미한다. 이를 자동 완성시키기 위해 신제품과 컨텐츠 특징적으로 비슷한 기존 제품들을 추려내고 해당 기존 제품들의 평점들을 기반으로 신규 제품의 평점을 자동 평가한다.(해당 내용을 보면서 문득 든 생각이지만.. 이렇게 하면 평점 조작이 아닌가? 싶기도 하다..이익을 창출하기 위해 평점을 조작하는 것이 도덕적으로 옳은 일인가에 대해서도 의구심이 드는 상황이다..)
또 다른 방법은 머신러닝의 Active Learning을 이용하는 것이다. 즉 유저가 제품을 평가하도록 하는 것이다. 이 때 유저가 평가할 제품들은 추천 시스템의 관점에서 가장 정보를 많이 담고 있을 상위의 제품들만 추출해낸 것들이다. Active Learning과 추천시스템을 어떻게 사용하지는에 관해서 한 가지 예시를 들어보자.
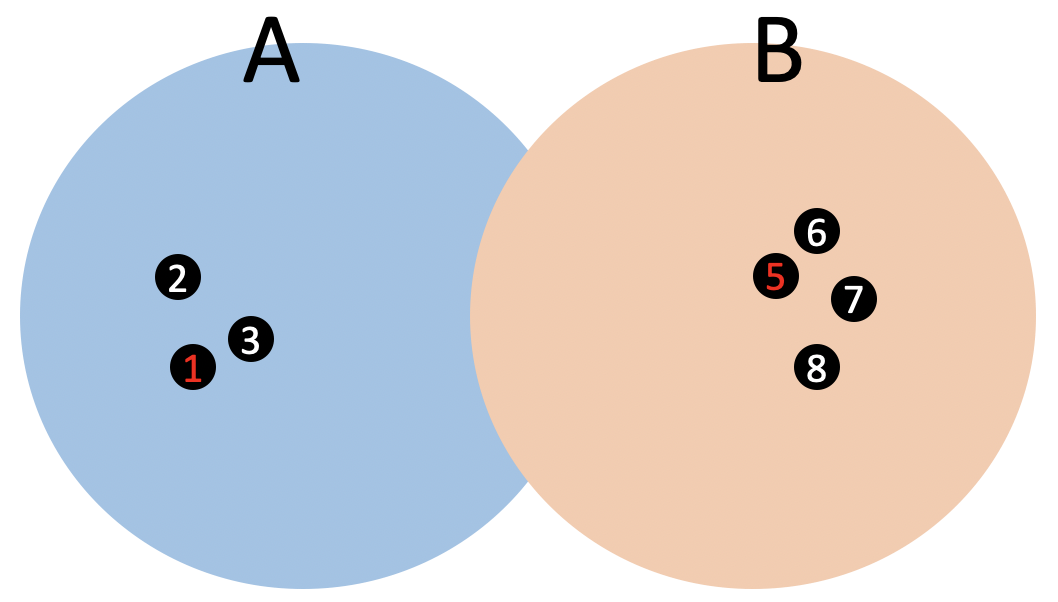
먼저 A, B 두 집단으로 분류되는 제품(또는 유저)들이 있다고 가정하자. 그리고 무수히 많은 데이터들 중 추천 시스템의 관점에서 보았을 때 정보를 가장 많이 담고 있는 제품 2개를 뽑아서 보여주었다. 그것은 A집단의 1번 제품, B집단의 5번 제품이다. 이 때 유저가 1번, 5번 제품에 대해 각각 평가를 한다. 그러면 이제 1번, 5번 제품에 대한 유저의 평가를 기준으로 다른 제품들을 추천해준다.
예를 들어, 유저가 A집단에 속한 1번 데이터에 좋은 평가를 주었다고 해보자. 그렇다면 추천 시스템은 이 평가만을 기반으로 1번과 가까운 거리에 있는 2번, 3번 제품들도 유사한 성격의 제품으로 판단하여 2번, 3번 제품을 유저에게 추천해준다. 설사 동시에 B집단의 5번 제품에도 좋은 평가를 주었다 하더라도 추천 시스템은 좋은 평가를 해준 1번과 비슷한 제품들, 5번과 비슷한 제품들 모두 유저에게 추천해줄 것이다.
마지막으로 인터페이스 에이전트를 이용하는 방법이 있다. 인터페이스 에이전트란, 네트워크나 OS같은 환경 내부에서 동작하는 에이전트가 각 사용자들의 implicit 한 행동 패턴을 관찰하는 것을 말한다. 그런데 인터페이스 에이전트는 자기가 관찰하는 사용자에게 개인화가 되는 데 시간이 걸릴 뿐더러 사용자가 해당 인터페이스 안에서 참여한 활동들만 관찰하는 제약이 있다. 그래서 보통은 다수의 인터페이스 에이전트를 활용해 이들 간에 정보를 교환하여 Cold Start 문제를 해결한다.
3-2. Feature Mapping
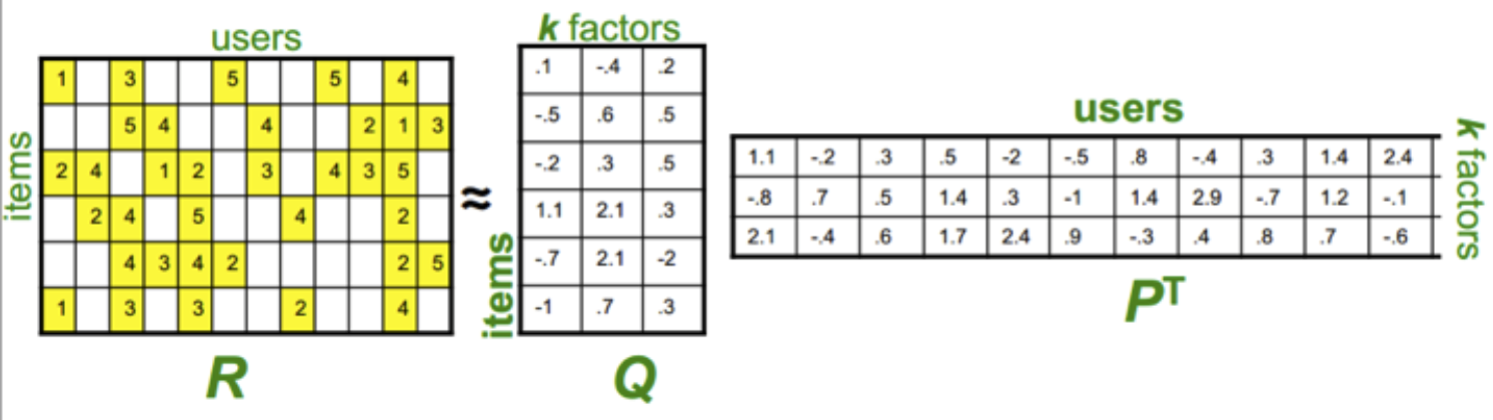
Feature Mapping은 협업 기반 필터링의 잠재 요인 기반 필터링과 연관이 있다. 간단하게 말하면 컨텐츠 정보와 협업 필터링 시 사용되는 인터렉션 정보를 결합하고 이를 머신러닝 기술을 활용해 해결하는 방법 중 하나이다. 이에 대해서는 개념과 코드로 간단하게 구현한 포스팅이 있기에 여기를 참고하면 훨씬 더 명확하게 이해가 가능할 것이다.
보통은 SVD와 같은 행렬 분해 알고리즘을 사용하고 SGD, ALS와 같은 최적화 머신러닝 알고리즘을 이용한다.
3-3. Hybrid Feature Weighting
하이브리드 컨텐츠 기반 필터링을 이용하는 것이다. 이는 사용자 또는 제품들의 특징을 사용자가 중요하다고 인식하는 기준에 따라 가중치를 부여하는 것이다.
예를 들어, 영화 스트리밍 서비스의 이용자 A는 나홀로 집에 1편의 주인공인 맥컬리 컬킨 배우가 나오는 영화를 주로 선호한다. 그래서 나홀로 집에 1편을 보았다. 영화를 보고난 후 스트리밍 서비스가 A에게 영화를 추천해준다. 이 때 일반적인 컨텐츠 기반 필터링이라면 단순히 나홀로 집에 2, 3, 4편을 추천해줄 것이다. 하지만 하이브리드 컨텐츠 기반 필터링이라면 나홀로 집에 2편과 맥컬리 컬킨 배우가 나온 다른 영화들을 추천해줄 것이다.(모두들 아시겠지만 맥컬리 컬킨 배우는 나홀로 집에 1, 2편까지만 출현했다.)
즉, 하이브리드 컨텐츠 기반 필터링은 사용자가 중요하다고 생각되는 요소, 영화라고 한다면 출연 배우, 영화 감독에 더 가중치를 두어 동일한 배우가 출현한 영화, 동일한 감독이 만든 영화를 추천해주는 것이다.
3-4. Differentiating Regularization Weights
Hybrid Feature Weighting과 반대되는 개념이다. 이는 오히려 제품 또는 유저들과 연관된다고 도출된 잠재 요인에 대해 제약을 두어 즉 Regularization을 적용해 Cold Start 문제를 해결하는 방법이다.
예를 들어, 인기 있는 제품 또는 매우 활성화된 유저들과 관련된 정보에는 가중치를 조금 주고 인기 없는 제품이나 자주 활동하지 않는 유저들과 관련된 정보에는 가중치를 많이 주어 Regularization 효과를 주는 것이다. 마치 머신러닝 예측 모델에서 학습 데이터에만 너무 치중되어 테스트 데이터에는 예측 정확도가 오히려 떨어지는 오버피팅을 예방하기 위한 즉, 모델의 일반화를 위한 조치와 매우 비슷하다.
지금까지 추천시스템의 Cold Start 문제의 원인들과 해결하는 방법들에 대해 알아보았다. 결론적으로 어떤 하나의 방법을 고수하기 보다는 소개된 방법들을 이리저리 결합하여 만든 추천 시스템 모델이 Cold Start 문제를 가장 잘 해결한다고 한다.
끝으로 필자가 레퍼런스를 읽어보고 좀 예전이지만 몇 기업들의 기술 블로그에서 포스팅한 추천 시스템 글 링크를 소개하고 글을 마치려 한다.
# Reference
'Data Science > 추천시스템과 NLP' 카테고리의 다른 글
| [추천시스템] FM(Factorization Machine) (0) | 2021.08.24 |
|---|---|
| [추천시스템] 딥러닝과 추천시스템, Neural CF(Collaborative Filtering) (0) | 2021.08.21 |
| [추천시스템] 추천 시스템의 성능은 어떻게 평가할까? (0) | 2020.11.20 |
| [NLP] Surprise library를 활용한 추천시스템 구현하기 (1) | 2020.08.28 |
| [NLP] Collaborative Filtering(Recommendation) (0) | 2020.08.26 |



