🔊 본 포스팅은 Apache Spark 3.0.1 공식 문서를 직접 해석하여 필자가 이해한 내용으로 재구성했습니다. 혹여나 컨텐츠 중 틀린 내용이 있다면 적극적인 피드백은 환영입니다! : )
이번 포스팅에서는 대용량 데이터 병렬 처리를 위한 통합 분석 엔진인 Apache Spark와 Apache Spark의 기본 자료 구조인 RDD 자료구조에 대해 소개하려 한다. Apache Spark는 구조화된 데이터를 처리하기 위한 Spark SQL과 머신러닝을 위한 ML Lib, 그래프 처리를 위한 Graph X, 실시간 처리와 방대한 연산을 위한 Structured Streaming 도구도 제공한다. 또한 Apache Spark는 본래 Scala 언어로 만들어졌지만 Java, R, Python 등과 같은 다양한 프로그래밍 언어 API를 제공한다.

1. Apache Spark는 Cluster mode 이다!
Apache Spark로 구현하는 앱(Application)은 클러스터에서 독립적인 프로세스로 운용된다. 그렇다면 구체적으로 어떻게 동작하는걸까? 우선 공식 문서에 소개되어 있는 그림부터 살펴보자.
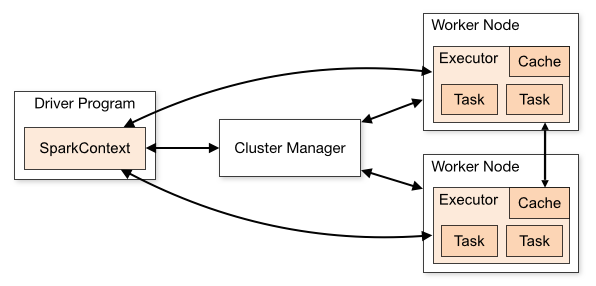
우선 Driver Program이란, 아파치 스파크를 사용해 클러스터를 생성하여 만든 SparkContext 라는 객체를 의미한다. 이 SparkContext는 몇 가지의 클러스터 매니저(세부 종류에는 스파크 자체에 내장된 가장 단순한 Standalone, 하둡 맵리듀스를 운영할 수 있는 Apache Mesos, 하둡2의 리소스 매니저인 Hadoop YARN, 앱 실행, 스케일링을 자동화하고 앱을 컨테이너화 해 관리할 수 있는 Kubernetes가 있다.)와 연결이 된다. 이 클러스터 매니저는 앱들 간에 리소스를 전달해주는 역할을 한다.
클러스터 매니저와 SparkContext가 연결된다면 각 클러스터 내부의 Worker Node에서 Executor를 얻게 된다. 이 Executor은 사용자가 만든 SparkContext(일종의 앱)를 위해 데이터를 저장하거나 연산을 실행하는 프로세스를 의미한다.
이제 Spark는 Python, R, Java와 같은 프로그래밍 언어로 코드를 작성한 파일(이 파일은 SparkContext를 이용해 만든 파일이다)을 각 클러스터 내부에 있는 Executor들에게 전달해준다. 마지막으로 코드내부의 SparkContext가 Executor들에게 작성된 코드의 task를 수행하기 위해 전달한다.
2. Pyspark 시작하고 SparkContext 생성하기
Apache Spark의 기본적인 자료구조는 RDD 자료구조이다. RDD는 Resilient Distributed Dataset으로 'Resilient'의 사전적 의미는 '탄력 있는' 이라는 의미이다. 여기서는 RDD 자료구조가 아파치 스파크의 클러스터 내부의 노드들 간에 공유되어 병렬적으로 연산될 수 있는 자료구조이기 때문에 그렇게 불린다.
RDD 자료구조를 실습해보기 전에 필자는 Python 기반인 Pyspark를 사용했으므로 Pyspark를 설치하고 실행 시 Jupyter Notebookbook으로 실행되도록 하는 방법은 여기를 참고하자.
3. RDD 자료구조 만들기
RDD를 만들기 위해서는 parallelize 메소드를 이용해 앱(Driver program) 내부에 직접 만들어 준다.
from pyspark import SparkContext, SparkConf
sc = SparkContext.getOrCreate()
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
res = distData.reduce(lambda a, b: a + b)
print(res)
여기서 parallelize() 메소드에서 partitions(=slices) 이라는 optional 인자가 있다. 스파크의 클러스터는 각 파티션에서 하나의 작업을 수행한다. 보통은 클러스터에서 각 CPU 당 2~4개의 파티션을 가지고 수행한다. 일반적으로 스파크는 자동적으로 파티션의 개수를 적정하게 세팅해주지만 사용자가 직접 수동적으로 파라미터를 집어 넣어 파티션 개수를 커스터마이징 해줄 수 있다.
from pyspark import SparkContext, SparkConf
sc = SparkContext.getOrCreate()
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data, 10) # 10개의 파티션으로 수행!
res = distData.reduce(lambda a, b: a + b)
print(res)4. 외부 데이터셋을 가져오기
pyspark는 로컬에 있는 파일, HDFS, 카산드라 HBase, 아마존 S3 등과 같은 하둡으로 지원되는 스토리지로부터 분산 데이터셋을 불러올 수 있다. 다음은 txt 확장자 파일로 되어있는 파일을 불러오는 코드이다.
distFile = sc.textFile('./people.txt')
# map과 reduce이용해 txt파일 내부 각 라인마다 length 합산 가능
distFile.map(lambda l: len(l)).reduce(lambda a, b: a + b)
textfile() 메소드 이외에 wholeTextFiles() 도 있는데, 이는 용량이 작은 여러 텍스트 파일들을 포함하는 디렉토리를 읽어 (filename, content) 쌍으로 결과값을 반환할 수 있다. 하지만 이러한 파일을 읽는 방법은 최근에 Spark SQL의 read/write 메소드에 의해 대체되는 경향이 있다.
5. RDD Operations(RDD 연산)
RDD 연산에는 2가지 종류가 있다.
- Transformations : 기존의 데이터에서 새로운 데이터를 만들 때 사용한다. 예로는 map 함수가 있다.
- Actions : 데이터셋에서 특정한 연산을 수행 후 Driver program(앱)에 연산 결과값을 전달한다. 예로는 reduce 함수가 있다.
이 때, Transformations은 Spark 내부에서 느리다. 왜냐하면 Transformations 자체는 연산을 바로 수행하지 않기 때문이다. 하지만 어떤 Transformations을 취할지 기억(cache)한다. 반면에 Actions이 수행되어야 실제적인 연산을 시작한다. 이러한 프로세스는 효율적이다. 왜냐하면 map이라는 Transformations은 reduce 라는 Actions를 수행하기 시작할 때야 수행되며 결국 Actions의 결과값만 앱에 반환하게 된다. 그래서 Transformations이 차지하는 큰 메모리 절약이 가능하다. 즉, Transformations이 반환할 새로운 큰 데이터셋을 메모리에 올리지 않는다.
기본적으로 Transformations된 RDD는 Actions를 수행할 때마다 재 연산이 가능하다. 하지만 persist() 또는 cache() 메소드를 이용해 메모리에 RDD 자료를 저장시킬 수 있다. 이러한 메소드를 사용하는 이유는 다음에 쿼리할 시 RDD에 더 빨리 접근하기 위함이다.
# lines는 현재 메모리에 로드되지 않고 해당 파일을 가르키는 포인터임
lines = sc.textFile('people.txt')
# map이라는 변환을 취한 후의 결과값(연산되지 않은 상태)
lineLengths = lines.map(lambda s: len(s))
# reduce라는 액션을 취함으로써 병렬 처리를 하면서 작업 연산을 수행. 결과값만 driver program에게 반환!
totalLength = lineLengths.reduce(lambda a, b: a + b)
# 만약 변환을 취한 linesLengths를 추후에도 사용할 것이라면 persist로 저장
lineLengths.persist()
'Apache Spark' 카테고리의 다른 글
| [Infra] 데이터 인프라 구조와 Sources (0) | 2021.04.23 |
|---|---|
| [PySpark] 컨텐츠 기반 영화 추천 시스템 만들어보기 (18) | 2021.02.15 |
| [PySpark] PySpark로 Regression 모델 만들기 (0) | 2021.02.04 |
| [PySpark] 타이타닉 데이터로 분류 모델 만들기 (2) | 2021.02.03 |
| [PySpark] Spark SQL 튜토리얼 (0) | 2021.02.01 |



