🔊 해당 포스팅은 고성능 파이썬 2판 책 서적을 읽고 개인적인 학습 목적 하에 작성된 글입니다. 포스팅에서 사용되는 자료들은 책의 내용을 참고하되 본인이 직접 재구성한 자료임을 알립니다.

이번 포스팅에서는 파이썬의 기본적인 자료구조에 속하는 리스트(list)와 튜플(tuple)에 대해 좀 더 깊게 이해해보도록 하자. 리스트와 튜플은 어떤 점이 같은지, 또 차이점이 무엇인지, 그에 따라 두 자료구조의 용도에 대해서도 알아보자.
1. 리스트와 튜플의 부모님: 배열
리스트와 튜플은 배열이라는 자료구조에 모두 속하는 자료구조들이다. 주의할 점은 여기서 배열이 python array 모듈로 지원하는 array 클래스도, Numpy의 array를 의미하는 것은 아니다. 말 그대로 자료구조 개념인 배열을 의미한다.
배열은 정해진 고유의 순서 예를 들면 오름차순 또는 내림차순, 문자열이라고 하면 알파벳 순서, 또는 사용자가 직접 정의한 순서 등 특정 순서에 따라 데이터를 나열해둔 것을 말한다. 배열이라는 자료구조에서는 이 '나열 순서'가 자료구조에 담긴 데이터만큼 중요하다. 왜냐하면 나열 순서를 미리 아느냐 또는 오름차순/내림차순으로 정렬되어 있느냐에 따라 자료구조의 특정 데이터를 조회하는 데 시간을 매우 단축시킬 수 있기 때문이다.
배열이 생성될 때는 시스템 메모리에 데이터가 연속적으로 저장된다. 그리고 배열의 특정 위치에서의 값을 읽어오기 위해서는 배열의 0번 인덱스에 있는 값 즉, 가장 첫번째 요소(이를 '기준 요소'라고 함)로부터 N번째 떨어져 있는 값을 가져온다. 코드로 이해를 한다고 한다면, array[3] 이라는 코드가 있다고 했을 때 이는 배열의 기준 요소로부터 3번째 떨어져 있는 값(3번 인덱스에 있는 값)을 갖고 오라는 것이다. 이런 방식 때문에 특정 위치에서의 값을 읽어올 때는 배열의 크기에 상관없이 모두 시간 복잡도가 O(1)이 된다.
실제로, 리스트 길이가 10인 것과 1천만개인 것 두 개를 미리 정의해놓고, 한 번은 길이가 10인 것에서 조회하고 한 번은 길이가 1천만개인 것에서 조회하는 시간을 측정하여 비교해보면 다음과 같이 시간이 거의 동일하게 나온다.
하지만 위와 같은 경우는 배열이 어떤 기준으로 정렬되어 있거나 또는 알고 있을 때이다. 만약 정렬되지 않은 배열에서 특정 항목을 찾으려면 어떻게 해야 할까?
가장 기본적인 탐색 방법은 배열의 모든 원소를 하나씩 탐색하는 선형 탐색(Linear Search) 알고리즘 사용할 수 있다. 이 알고리즘은 최악의 경우 시간 복잡도가 O(n)인데, 말 그대로 찾으려는 항목이 배열에 없는 경우이다. 즉, 어떤 데이터가 배열 내에 존재하는지 여부를 선형 탐색으로 알아내려면 배열의 모든 데이터를 다 탐색해봐야 한다. 실제로 파이썬 리스트 자료구조의 index() 라는 함수가 이와 같이 동작한다. index() 함수가 동작하는 과정을 파이썬으로 구현해보면 아래와 같다.
def index(array, target):
for i in range(len(array)):
if array[i] == target:
return i
else:
return -1
그래서 실제로 예전에 알고리즘 문제를 풀다보면 리스트의 특정 원소를 탐색할 때 index() 문법을 사용하면 매우 느렸던 이유가 선형 탐색 알고리즘을 이용하기 때문이다.
그렇다면 좀 더 효율적으로 찾을 수는 없을까? 효율적으로 찾기 위해서는 어쨌건은 일단 배열의 데이터가 정렬된 상태이어야 한다. 그래야 탐색 성능이 향상된다. 리스트는 내장되어있는 효율적인 정렬 알고리즘(팀 정렬이라고 삽입 정렬과 병합 정렬을 조합한 알고리즘 이라고 함)이 있으므로 해당 알고리즘으로 우선 배열 내의 데이터를 정렬시킨다.(sorted(), sort() 함수를 사용)
다음으로 정렬된 데이터가 있을 때, 어떤 데이터를 찾고 싶은데, 그 데이터가 매번 어디에 있을지 미리 알 수가 없는 상황이라고 가정해보자. 이런 상황이라면 우리가 위에서 알아본 한 번에 조회 즉, 시간 복잡도가 O(1)이 걸리도록 할 수가 없다. 왜냐하면 어떨 때는 배열에 첫 번째 데이터가 우리가 원하는 것일 수도 있고, 어떨 때는 세 번째 데이터가 우리가 원하는 것일 수도 있기 때문이다. 이럴 경우, 우리는 어떤 탐색 알고리즘을 사용해볼 수 있을까?
바로 이진 탐색(Binary Search)이다. 이진 탐색은 시간 복잡도가 O(logn)이다. 이진 탐색을 파이썬으로 구현한 코드는 여기 있다. 그런데 누군가는 이렇게 얘기할 수 있다. "그냥 리스트를 딕셔너리(사전) 자료구조로 변경하고 딕셔너리는 조회 시 시간 복잡도가 무조건 O(1)이니까 더 효율적인 것 아니야?" 라고 할 수 있다. 시간 복잡도로 보면 그게 맞지만 2가지 단점이 있다. 첫 번째는 자료구조를 [리스트 → 딕셔너리] 로 변경하는 시간이 O(n)이 걸린다는 것이다. 두 번째는 딕셔너리에는 같은 이름의 키가 중복되는 것을 허용하지 않고 overwrite 된다. 실제로 아래와 같은 코드를 실행하면 결과는 이렇다.
따라서 리스트에서 딕셔너리로 자료구조를 바꾸는 선택지가 항상 옳은 것은 아니다. 리스트 길이가 커지면 커질수록 자료구조를 변경 시 걸리는 시간이 병목으로 작용할 가능성이 높을 것임을 예상할 수 있다.
2. 리스트와 튜플의 공통점과 차이점
리스트와 튜플의 공통점은 앞서 말한 것처럼 기본적인 자료구조가 배열에 속한다. 그리고 다른 데이터 타입을 섞어서 쓸 수 있다는 점이다. 즉, 리스트와 튜플 모두 자료구조에 문자열, 정수, 실수 등을 함께 섞어 생성하는 것이 가능하다. 그러면 이제 차이점에 대해 알아보자.
2-1. 동적(dynamic) 배열 : 리스트
리스트는 동적 배열이다. 여기서 동적이라 함은 이미 생성한 자료구조에 데이터를 첨가하거나 삭제하는 등의 수정이 가능하다는 의미다. 따라서 저장 용량을 늘리거나 줄일 수 있다. 밑에서 좀 더 자세히 배우겠지만 이렇게 용량을 늘리거나 줄일 수 있는 특징 때문에 튜플보다 상대적으로 메모리를 더 많이 사용하고 추가 연산도 필요하게 된다.
리스트의 특정 원소를 조회하는 것은 위에서 살펴보았으므로 여기에서는 튜플과의 중요한 차이점인 리스트에 새로운 데이터를 추가하는 경우를 살펴보자. 먼저 아래와 같은 코드가 있다.
tmp = [1, 2, 3, 4]
tmp.append(5)
print(tmp) # [1, 2, 3, 4, 5]
리스트에 특정 원소를 추가하는 가장 기본적인 append 기능이다. append 라는 기능은 리스트라는 동적 배열의 크기를 변경하기 때문에 내부적으로 resize 연산을 사용한다. 즉, 배열의 크기를 늘린다. 하지만 이렇게 배열의 크기를 늘릴 때 파이썬은 메모리만큼은 새롭게 추가한 데이터가 담길 크기만큼보다 더 큰 메모리를 할당한다. 예를 하나 들어보자.
크기가 N인 리스트가 있다. 우리는 이 리스트에다가 새로 데이터 1개를 추가하기 위해 append 기능을 사용했다. 이 때, 파이썬은 내부적으로 할당하는 메모리는 N+1 만큼이 아닌 여유분까지 포함해서 N+M 만큼의 메모리를 할당한다. 이렇게 여유분까지 생각하여 메모리를 할당하는 것을 '초과 할당'이라고 한다. 이렇게 초과할당이 이루어진 후 이전 리스트의 데이터를 새로운 리스트로 복사한 후, 이전 리스트는 삭제한다.
그러면 파이썬은 왜 메모리를 여유분까지 감안해서 확보할까? 이유는 간단하다. 리스트에 데이터를 한 번 추가하다보면 그 뒤로도 여러 번 더 추가할 확률이 높으니 메모리 할당과 복사 요청 횟수를 줄이기 위함이다. 특히, 메모리 복사는 비용이 많이 들기 때문에 리스트 크기가 커지게 되면 문제가 될 소지가 높다.
리스트에 원소를 추가함에 따라 메모리가 추가로 할당되는 과정을 도식화해보면 아래와 같다. 다음과 같이 리스트에 원소를 추가하는 코드가 있다고 해보자.
lst = [1, 2]
for i in range(3, 7):
lst.append(i)
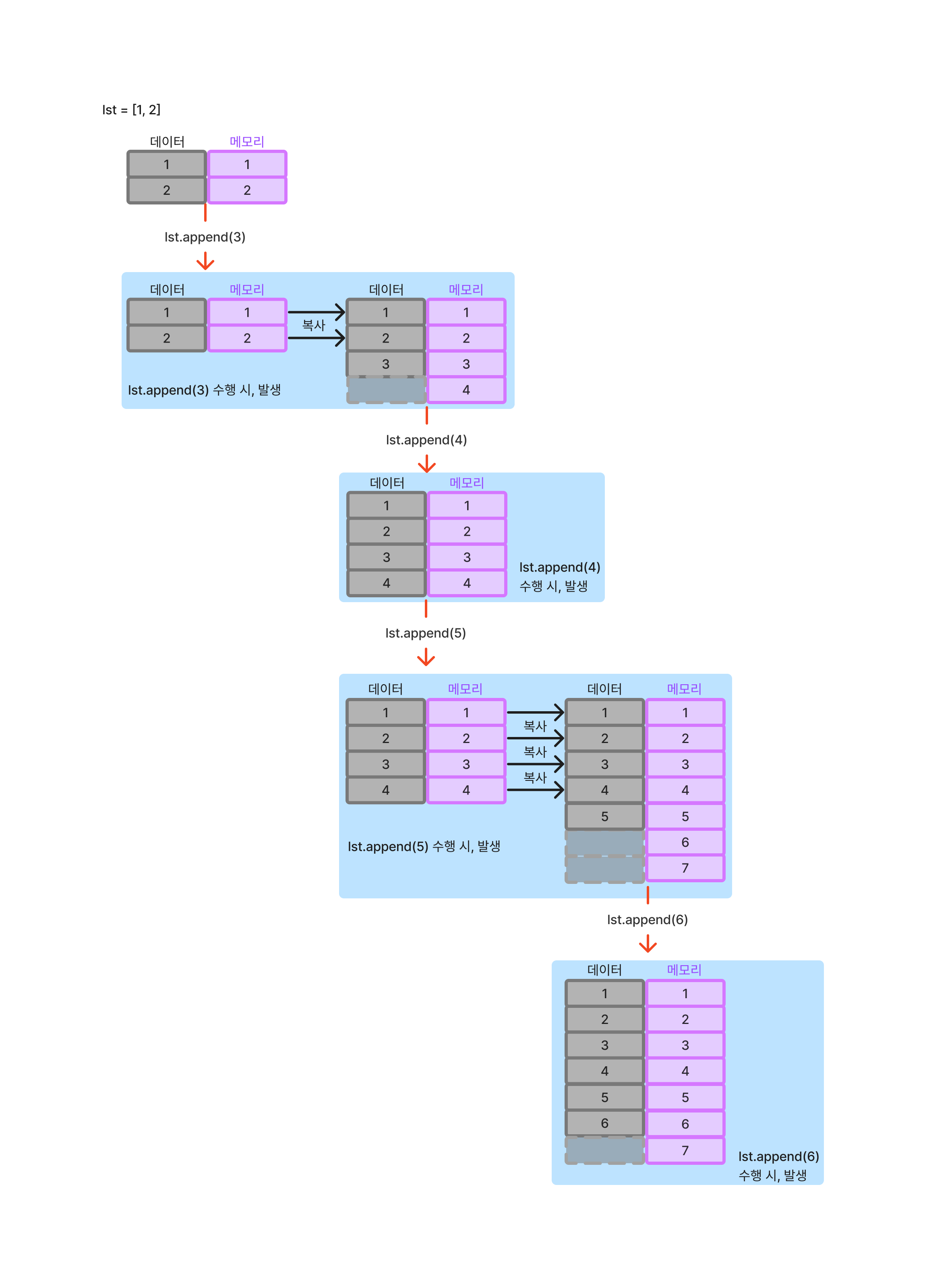
위처럼 리스트 길이가 커지게 됨에 따라 실질적으로 할당된 메모리 중 실질적으로 사용되지 않는 메모리 영역은 점점 많아지게 된다. 실제로 append 기능을 사용해서 데이터를 추가하는 연산과 list comprehension을 사용해서 데이터를 추가하는 연산 간에는 메모리 사용량 측면에서 append 기능이 메모리를 덜 사용한다. 왜냐하면 append 기능이 메모리를 초과 할당하기 때문이고 또 list comprehension이 보다 메모리를 효율적으로 사용하기 때문이다. 또한 실행 시간 속도에서도 차이가 나는데, 이번에는 list comprehension이 실행 속도가 더 빠르다. 이유는 append를 사용할 때 추가로 실행해야 할 파이썬 문장이 더 많기 때문이다.
# using `append`
lst = []
for i in range(100_000):
lst.append(i)
# using `list comprehension`
lst = [i for i in range(100_000)]2-2. 정적(static) 배열 : 튜플
다음으로 튜플에 대해 알아보자. 튜플은 리스트와 달리 정적 배열이다. 즉, 한 번 생성되면 배열의 크기 뿐만 아니라 배열 안의 데이터도 변경할 수 없다. 물론 약간의 트릭(?)을 사용해서 튜플도 데이터를 하나로 합칠 수는 있다. 예를 들어, 아래와 같다.
a = (1, 2, 3, 4)
b = (5, 6, 7)
res = a + b
print(res) # (1, 2, 3, 4, 5, 6, 7)
물론 튜플을 + 연산자로 합치는 것이 리스트의 append 기능이 수행되면서 내부적으로 실행되는 resize 연산이 수행되는 것은 아니다. resize 연산과는 비슷하지만 리스트의 append 기능과는 달리 메모리의 여유 공간을 더 할당하는 '초과 할당'을 수행하지는 않는다. 그래서 데이터가 변하지 않을 가능성이 높은 즉, 정적인 데이터에는 튜플이 더 가볍고 좋다.
하지만 + 연산자는 리스트의 append 와는 달리 시간 복잡도가 튜플에서는 O(n)이 걸린다. 왜냐하면 메모리의 공간이 꽉 찼을 때만 메모리 할당과 복사가 이루어지는 리스트와는 달리 튜플에서는 새로운 데이터를 추가할 때마다 메모리 할당과 복사가 매번 발생하기 때문이다. 그래서 리스트에서 append 기능은 데이터가 추가된 리스트의 새로운 메모리 주소를 할당하지 않지만 튜플에서 + 연산자는 새로운 메모리 주소를 할당한다.(물론 리스트에서도 + 연산자가 가능한데, 이 때도 튜플에서의 + 연산자 처럼 새로운 메모리 주소를 할당한다) 결국 정리하면 데이터를 합치는 상황에서는 리스트가 월등히 유리하다.
그러면 여기서 리스트에서 append 를 사용하지 않는 list comprehension을 사용한다고 해도 튜플보다 메모리를 더 점유한다. 왜냐하면 리스트라는 것 자체가 배열의 크기 변경을 효율적으로 하려고 상태 정보를 관리하기 때문이다. 물론 배열의 크기가 작을 때는 이 관리하는 상태 정보가 크지 않지만 크기가 수백만이 되는 등 점점 커지면 이 또한 무시할 수 없는 수치가 된다.
아까 위에서 튜플이 정적이기 때문에 리스트보다 가볍고 좋다라고 했다. 그런데 왜 가볍고 좋을까? 이유는 파이썬이 내부적으로 튜플을 리소스 캐싱해두기 때문이다. 즉, 튜플은 파이썬 런타임에서 캐시해놓기 때문에 사용할 때마다 OS의 커널에 메모리를 요청해서 받아오지 않아도 된다.
좀 더 구체적으로 알아보자. 파이썬은 기본적으로 자동화되어 있는 GC(Garbage Collector)을 내부적으로 사용하여 더 이상 사용되지 않는 변수에 할당된 메모리를 거둬들인다. 하지만 이 때, 크기가 20 이하인 튜플은 크기 별로 최대 2만 개까지 더 이상 사용되지 않는 변수로 취급된다고 하더라도 GC가 즉시 회수하지 않고 나중에 다시 사용할 것을 대비해 잠시 저장(캐싱)해둔다. 예를 들어, 크기가 2인(ex. (1,2)와 같은 튜플 2만개), 크기가 3인(ex. (1,2,3)와 같은 튜플 2만개)) , .... , 크기가 20인(ex. (1,2,3,...)와 같은 튜플 2만개까지 캐싱해둔다는 것이다. 그리고 나중에 같은 크기의 튜플이 다시 필요해지면 OS에서 메모리를 새로 할당받지 않고 기존에 할당해둔 메모리를 재사용한다. 물론 이렇게 캐싱해두면 당연히 파이썬 프로세스가 딱 필요한 양보다는 메모리를 좀 더 사용하게 된다는 점은 있다.
어쨌건 이와 같은 배열의 특정 크기에 한하여 튜플의 캐싱 기능 덕분에 리스트보다 가볍다라는 것이다. 캐싱 기능으로 인해 가볍다는 것은 곧 OS까지 가지 않아도 되는 것을 의미하므로 튜플을 쉽고 빠르게 생성할 수 있다는 것이다. 실제로 데이터는 같되 리스트와 튜플로 각각 배열을 생성하기까지의 속도를 측정해보자.

첫 번째 줄에 리스트로 배열을 생성했을 경우는 37.9 나노초가 걸린 반면, 튜플의 경우 6.67 나노초가 걸린 것을 볼 수가 있다. 즉, 튜플 생성 시 걸리는 속도가 훨씬 빠르다는 뜻이다.
이렇게 해서 파이썬의 기본 자료구조인 리스트와 튜플에 대해서 내부적으로 좀 깊게 알아보았다. 리스트와 튜플에 대해 정리하면 다음과 같다.
[리스트와 튜플에 대한 비교 내용 Wrap-Up]
- 리스트와 튜플은 배열이라는 자료구조에 속하며, 정렬된 데이터에 적합한 자료구조이다.
- 리스트와 튜플은 연속적인 메모리에 데이터가 위치하므로 특정 항목을 바로 읽어 탐색 문제를 빠르게 해결할 수 있다.
- 리스트는 동적 배열이며, 수정을 할 수 있다. 그리고 데이터 추가 시, append()는 초과할당을 수행하여 여유로운 메모리를 확보한다.
- 튜플은 정적 배열이며, 수정을 할 수 없다. 하지만 파이썬이 리소스 캐싱을 하기 때문에 튜플 생성 시 리스트보다 빠르게 생성할 수 있어 가볍고 메모리 부담이 적다.
- 튜플도 + 연산자를 사용해서 데이터를 합칠 수 있다. 하지만 메모리 초과할당을 수행하지 않기 때문에 데이터 합칠 시 합치는 데이터 개수 N개 만큼의 시간 복잡도가 걸려 리스트보다 비효율적이다.
다음 장에서는 정렬되지 않은 데이터를 탐색하는 문제에 적합한 사전 즉, 딕셔너리 자료구조에 대해서 알아보도록 하자.
'Python > 고성능파이썬' 카테고리의 다른 글
| [고성능파이썬] 이터레이터(iterator)와 제네레이터(generator) (0) | 2024.03.30 |
|---|---|
| [고성능파이썬] 사전(dictionary) 과 셋(set) (0) | 2024.03.25 |
| [고성능파이썬] 프로파일링으로 병목 지점 찾기 (2) | 2023.12.26 |
| [고성능파이썬] 고성능 파이썬을 어떻게 실현시킬 수 있을까? (0) | 2023.12.14 |



