🔊 해당 포스팅은 밑바닥부터 시작하는 딥러닝 3권을 개인적으로 공부하면서 배운 내용을 기록하고 해당 책을 공부하시는 다른 분들에게 조금이나마 도움이 되고자 하는 목적 하에 작성된 포스팅입니다. 포스팅 내용의 모든 근거는 책의 내용에 기반하였음을 알립니다.

저번 포스팅에서는 나만의 딥러닝 프레임워크를 만드는 첫 단계로서 수치 미분을 통해 미분을 자동으로 계산하는 방법에 대해 알아보았다. 하지만 앞서 배운 수치 미분이라는 방법은 계산 비용과 정확도 측면에서 단점이 존재한다. 그래서 이에 대한 대안책으로 오차역전파라는 방법이 등장한다. 오차역전파를 이용하면 미분 계산도 효율적으로 빠르게 할 수 있으며 결과값의 오차도 작아진다.
책에서는 역전파 이론에 대해서도 어느 정도 분량을 담아 기술하고 역전파 구현하는 단계로 넘어간다. 하지만 필자는 책 시리즈 1권을 다루면서 오차역전파에 대한 개념을 구체적으로 소개한 적이 있으므로 해당 포스팅에서는 개념에 대해서는 간단하게 다루고 곧바로 역전파를 코드로 구현하는 것에 초점을 맞춰서 기술할 예정이다. 만약 역전파에 대한 개념에 대해 잘 모른다면 이전 포스팅 2개(1편, 2편)를 꼭 참고하도록 하자.
Step5. 역전파의 핵심, 연쇄 법칙(Chian Rule)
역전파의 핵심은 연쇄 법칙을 이해하는 것이다. 연쇄 법칙이란, 여러 함수를 사슬(Chain)처럼 연결해서 사용하는 모습을 비유한 것이다. 연쇄 법칙에 따르면 여러 함수가 사슬처럼 연결된 합성함수라는 것의 미분은 그것을 구성하고 있는 개별의 함수 각각을 미분한 후 곱한 것과 같다는 것이다.
아래와 같은 계산 그래프로 표현할 수 있는 합성함수 $F(x)$가 있다고 가정하자. 그리고 $a = A(x)$, $b = B(a)$, $y = C(b)$ 이다.

위 $F(x)$라는 함성함수가 존재할 때, $y$에 대한 $x$의 미분값(${dy \over dx}$)은 아래와 같이 분해해서 계산할 수 있다.
$${dy \over dx} = {dy \over dy}{dy \over db}{db \over da}{da \over dx}$$
물론 위에서 ${dy \over dy}$는 자신에 대한 미분 값이기 때문에 항상 1이다. 그래서 생략이 가능하다. 그리고 위 수식의 순서를 왼쪽부터 오른쪽으로 읽어보면 합성함수의 진행 반대 방향(출력에서 입력 방향)으로 적힌 것을 눈치챈 사람도 있을 것이다. 이렇게 '거꾸로' 미분값을 곱한다고 해서 역전파라고 한다. 참고로 합성함수 진행 방향대로 미분 값을 곱할 수도 있다. 이러한 경우를 '포워드 모드 자동 미분'이라고 한다.
그러면 출력에서 입력방향으로 미분을 순서대로 계산하는 방식을 그림으로 살펴보자.
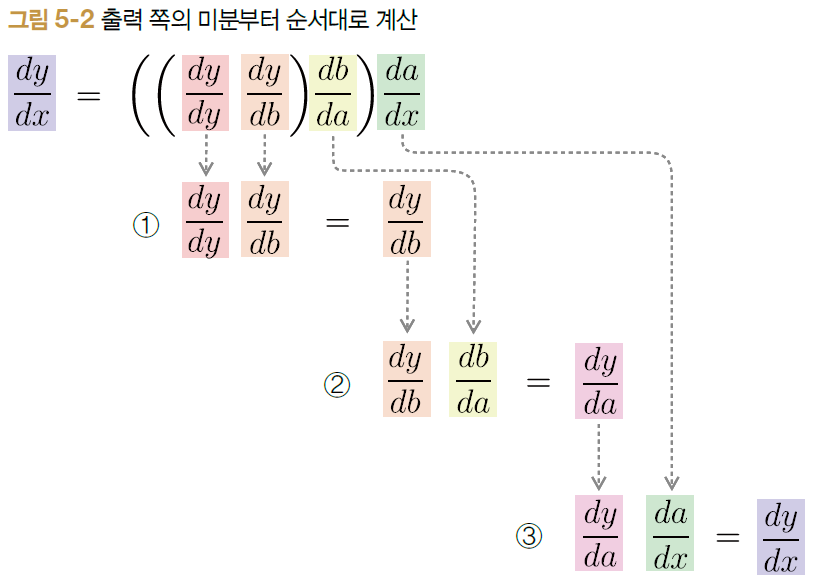
위 그림에서 1번, 2번, 3번 순서대로 각각의 미분값을 곱해준다. 이렇게 각 미분값을 '국소적인 미분값'이라고도 한다. 결국 위 그림 상으로는 총 3번의 국소적인 미분 값을 곱하는 단계를 취하면 우리가 최종적으로 구하고자 하는 $y$의 $x$에 대한 미분값인 ${dy \over dx}$를 계산할 수 있다. 계산 그래프로 나타내게 되면 아래와 같다.

역전파의 핵심은 $y$에 대한 미분값을 구하는 것이다. 그래서 계산 그래프에서 오른쪽에서 왼쪽으로 전달되는 모든 미분값들은 어쨌건 $y$에 대한 미분값이다. 단지 $y$의 $b$에 대한 미분값인지, $a$에 대한 미분값인지, $x$에 대한 미분값인지에 대한 것만 달라질 뿐이다.
위에서도 잠깐 언급했지만 잠깐 생각해볼만한 점이 있다. 왜 우리는 굳이 출력($y$)에서 입력($x$)방향으로 미분을 계산할까? 그 이유는 $y$를 중요한 요소로 간주하기 때문이다. 이는 결국 지도학습에서의 머신러닝의 본질과 함께 이해할 수 있는데, 머신러닝의 학습 방법은 출력($y$, 정답이라고도 함)을 보면서 데이터의 패턴을 파악하는 것이다. 따라서 머신러닝이 중요하게 봐야할 것은 출력인 $y$값이라는 것이다. 따라서 역전파는 출력에서 입력 방향으로 흘러가는 것이다.
만약 미분 계산이 입력에서 출력 방향으로 계산했다면 그 때의 중요 요소는 입력인 $x$가 된다. 이렇게 되면 $x$의 다른 변수들($a, b, y$)에 대한 미분값을 계산하는것이다.
이제 역전파 이론의 마무리로서 구현에 들어가기 전에 순전파와 역전파 간의 관계를 계산 그래프로 살펴볼 수 있다. 이를 통해 역전파를 코드로 구현할 때 어떤 방식으로 코드를 작성해야 할지 감이 온다.
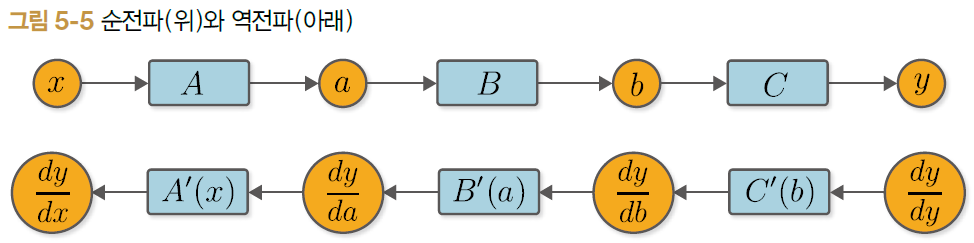
위 그림에서 순전파 시 네모칸 속에 있는 $C$ 함수와 역전파에서 대응되는 것은 $C'(b)$이다. 그런데 여기서 $C'(b)$를 구하기 위해서는 순전파 시 $C$ 함수의 입력으로 넣어주었던 $b$라는 값이 필요하게 된다. 또한 순전파 시 $B$ 함수도 마찬가지이다. 대응되는 역전파에서의 $B'(a)$를 구하기 위해서는 순전파 시 $B$ 함수의 입력으로 들어가는 $a$라는 값이 필요하다. 이것이 시사하는 바는 무엇일까?
바로 역전파 시에는 순전파 시 사용했던 값들이 필요하다는 것이다. 따라서 순전파가 수행된 뒤 역전파가 수행되므로 역전파를 수행할 때는 순전파를 수행하면서 사용했던 데이터들을 어딘가에 저장(캐싱)해두어야 한다는 것이다. 자, 이제 그러면 역전파를 직접 구현해보는 파트로 가보도록 하자!
Step6. 수동 역전파
먼저 '수동'적으로 작용하는 역전파를 만들어보자. 우리는 저번 첫 포스팅에서 구현해보았던 변수 역할을 하는 Variable 클래스, 함수의 공통 기능을 담고 있는 Function 클래스를 약간 더 응용해서 재정의할 필요가 있다. 추가된 부분은 주석처리한 부분과 backward() 메소드가 추가 되었다.
import numpy as np
class Variable:
def __init__(self, data):
self.data = data
self.grad = None # 해당 변수에 대응되는 미분값(Gradient) 담을 인스턴스 변수
class Function:
def __call__(self, input):
x = input.data
y = self.forward(x)
output = Variable(y)
self.input = input # 순전파 시의 통상값을 저장 for 역전파 시 사용
return output
def forward(self, x):
raise NotImplementedError("This method should be called in other function class")
def backward(self, gy):
raise NotImplementedError("This method should be called in other function class")
이번 예시에서는 제곱함수와 지수함수 2개를 만들어보도록 하자. 제곱함수의 미분은 어차피 구하기 쉬우므로 생략하겠다. 지수함수의 미분계산 방법은 예전 포스팅에서 언급한 적이 있다.
class Square:
def forward(self, x):
return x ** 2
def backward(self, gy):
x = self.input.data
gx = 2 * x * gy
return gx
class Exp:
def forward(self, x):
return np.exp(x)
def backward(self, gy):
x = self.input.data
gx = np.exp(x) * gy
return gx
자, 이제 위 정의된 클래스들을 활용해서 순전파, 역전파를 수동적으로 구현해보자. 수동적이라고 함은 아래처럼 마치 우리가 주피터 노트북에서 한 셀씩 run 시키는 것처럼 원바이원 라인으로 실행하는 것을 말한다.
import numpy as np
A = Square()
B = Exp()
C = Square()
x = Variable(np.array(0.5))
a = A(x)
b = B(a)
y = C(b)
print(type(y), y.data)
이제 수동적으로 역전파를 시켜보자. 우리가 가장 먼저 손수 정의해주어야 하는 부분은 $y$의 $y$에 대한 미분(${dy \over dy}$)이다. 이는 어차피 자신에 대한 미분값이므로 무조건 1이다. 그러므로 $y$ 변수의 미분값을 담는 인스턴스 변수에다가 1을 할당해주고 역전파를 해주면 된다.
import numpy as np
y.grad = np.array(1.0)
b.grad = C.backward(y.grad)
a.grad = B.backward(b.grad)
x.grad = A.backward(a.grad)
print(type(x), x.grad)Step7. 역전파 자동화
Step6에서는 역전파를 수동적으로 작동시켜보았다. 그런데 역전파를 함수 하나하나마다 실행시켜주다 보니 함수가 더 많아지면 어지간히 귀찮은 작업이 될 듯 하다. 그래서 이번 단계에서는 한 번의 순전파를 수행해주면 함수 종류, 함수 개수에 상관없이 역전파가 자동으로 수행되는 구조를 만드는 방법에 대해 배워보자. 이 방법이 딥러닝 프레임워크의 공통 철학이 되는 Define-by-Run의 핵심이다. Define-by-Run 이란, 동적 계산 그래프라고도 하며 딥러닝에서 수행하는 계산들을 계산 시점에 '연결'하는 방식을 의미한다.
Step6에서는 우리가 계산 그래프를 모두 일직선으로만 늘어놓았던 구조였다. 물론 이런 비교적 간단한 합성함수에서는 일직선 모양의 계산 그래프를 통해 출력에서 입력의 한 방향으로 역추적하면서 역전파를 수행할 수 있다. 하지만 분기가 있는 그래프나 같은 변수가 여러 번 사용되는 복잡한 계산 그래프가 되면 이러한 일직선 구조의 계산 그래프로 역전파를 제대로 구현해낼 수가 없다.
Define-by-Run의 핵심은 '변수와 함수의 관계'를 이해하는 데서 출발한다. 먼저 '함수의 입장'에서 변수를 바라보는 관점을 생각해보자. 함수는 변수를 2가지로 바라본다. 바로 함수의 '입력 값'과 '출력 값'이다. 그림으로 표현하면 아래와 같다.
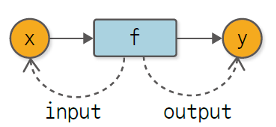
위 그림의 점선 화살표는 '참조(Reference)'를 의미한다. 그러면 이제 반대로 '변수의 입장'에서 함수를 바라보는 관점을 생각해보자. 여기서 포인트는 "변수는 함수에 의해 만들어진다" 이다. 즉, 변수가 입력 변수라는 것은 그 입력 변수로 들어갈 함수가 이미 존재해야 하고, 변수가 출력 변수라는 것은 출력 변수를 내뱉는 함수가 이미 존재해야 한다는 것을 의미한다. 결국, 변수에게서 함수는 창조자(Creator, 또는 부모)라고 할 수 있다.

여기서 만약 어떤 변수가 창조자 즉, 함수가 존재하지 않는다고 한다면, 그 변수는 외부에서 예컨대, 프로그래머 사용자가 직접 정의하거나 만든 변수로 간주한다.
자, 이제 그러면 이 변수와 함수의 관계를 구현한 코드 중 Variable, Function 클래스에 녹여내보자. 먼저 Variable 클래스에 특정 변수의 창조자는 어떤 함수인지 정의하는 메소드와 인스턴스 변수를 추가하도록 하자.
import numpy as np
class Variable:
def __init__(self, data):
self.data = data
self.grad = None
self.creator = None
def set_creator(self, func):
self.creator = func
다음은 Function 클래스에서 출력 변수의 창조자가 어떤 함수인지 정의해주도록 하자. 그리고 출력도 캐싱해두도록 하자.
import numpy as np
class Function:
def __call__(self, input):
x = input.data
y = self.forward(x)
output = Variable(y)
output.set_creator(self)
self.input = input
self.output = output
return output
def forward(self, x):
raise NotImplementedError("This method should be called in other function class")
def backward(self, gy):
raise NotImplementedError("This method should be called in other function class")
위에서 익숙하지 않은 부분이 있을 수 있다. 바로 출력의 set_creator 메소드를 사용할 때 self 를 넣어준다는 점이다. 이는 추후에 위에서 그랬던 것처럼 Function을 함수의 공통 기능으로 사용할 것이고 이를 상속 받아서 제곱함수(Square)이든 지수함수(Exp)이든 만들 것이기 때문에, 위와 같이 표현해야 추후에 Function 클래스를 상속하는 특정 종류의 함수를 창조자로 설정할 수 있다.
위처럼 출력변수의 창조자가 어떤 함수인지 연결시켜주는 것이 동적 연결 기법인 Define-by-Run의 핵심이다. 이제 정의한 클래스들을 활용하면 합성함수에서 출력에서 입력 방향으로 변수와 함수를 거쳐 거슬러올라갈 수 있다. 아래 예시 코드를 보도록 하자.
import numpy as np
A = Square()
B = Exp()
C = Square()
# 순전파 수행
x = Variable(np.array(10))
a = A(x)
b = B(a)
y = C(b)
# 순전파로 연결된 변수와 함수 간의 관계를 통해 거슬러 올라가기
assert y.creator == C
assert y.creator.input == b
assert y.creator.input.creator == B
assert y.creator.input.creator.input == a
assert y.creator.input.creator.input.creator == A
assert y.creator.input.creator.input.creator.input == x
위 코드는 특정 변수와 창조자가 맞는지 조건을 충족하는지 여부를 확인하는 assert 선언문들이다. 위 코드로 검증하려는 관계는 아래와 같다.
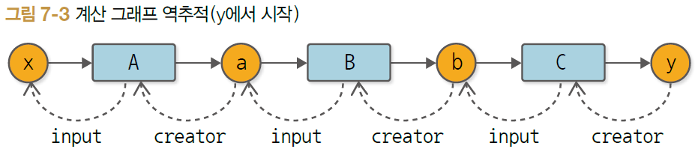
위처럼 함수와 변수간의 관계가 만들어지는 것은 바로 순전파를 수행할 때 일어난다는 것이 핵심이다. 즉, 순전파 계산을 실질적으로 수행하는 시점(Run: 순전파로 데이터를 흘려보내는 시점)에 연결이 규정된다(Define)는 것 때문에 핵심 철학의 이름이 'Define-by-Run'이다. 참고로 위와 같은 구조는 노드들의 연결(링크)로 이루어진 데이터 구조로 자료구조를 공부하면 한 번쯤 들어봤을 법한 링크드 리스트 구조이다.
이제 그러면 실실적으로 역전파를 수행시켜보자. 역전파를 수행하는 단계는 다음과 같다.
- 함수를 가져오기
- 가져온 함수의 입력 변수를 가져오기
- 가져온 함수의 역전파 메소드를 호출하기
위 단계를 머리에 넣고 다음 코드를 살펴보자.
import numpy as np
A = Square()
B = Exp()
C = Square()
# 순전파 수행
x = Variable(np.array(10))
a = A(x)
b = B(a)
y = C(b)
# 역전파 수행
y.grad = np.array(1.0)
C = y.creator # 1.출력변수의 창조자 함수 가져오기
b = C.input # 2.가져온 함수의 입력변수 가져오기
b.grad = C.backward(y.grad) # 3.가져온 함수의 역전파 메소드 호출
B = b.creator
a = B.input
a.grad = B.backward(b.grad)
A = a.creator
x = A.input
x.grad = A.backward(a.grad)
print(y.grad, b.grad, a.grad, x.grad)
자, 이제 Define-by-Run 방식으로 동작하는 순전파, 역전파 과정이 무엇이지 알아보았다. 그런데 아직 우리는 반복적으로 역전파 메서드를 호출하는 귀찮은 과정을 줄일 필요가 있다. 이를 자동화시키기 위해서는 Variable 클래스에 역전파 메소드를 추가해야 한다.(Function 클래스에 있는 backward 메소드와 이름이 같지만 기능은 다름!을 헷갈리지 말자)
class Variable:
def __init__(self, data):
self.data = data
self.grad = None
self.creator = None
def set_creator(self, func):
self.creator = func
def backward(self):
f = self.creator # 1.출력 변수의 창조자 함수 가져오기
if f is not None: # 2.가져온 함수의 입력변수 가져오기
x = f.input
x.grad = f.backward(self.grad) # 3.가져온 함수의 역전파 호출
x.backward() # 4.재귀적으로 수행! for 자동화
A = Square()
B = Exp()
C = Square()
# 순전파 수행
x = Variable(np.array(0.5))
a = A(x)
b = B(a)
y = C(b)
# 역전파 수행
y.grad = np.array(1.0)
y.backward()
# 역전파 후 최종 미분값 출력
print(x.grad)
위에서 자동화하기 위해서 사용한 방법은 바로 재귀적인 호출 방법이다. Variable 클래스에 새롭게 추가된 backward() 메소드를 보면 f 라는 변수로 해당 변수의 창조자 함수를 가져온다. 그리고 이 창조자 함수가 None 값이 아닐 때까지 역전파를 재귀적으로 호출하는 것인데, 이 창조자 함수가 None 이라는 말은 곧 입력 변수까지 도달했다는 것을 의미한다.
Step8. 재귀를 반복문으로!
Step7 마지막 부분에서 역전파를 자동화(반복)시키기 위해 재귀 호출문을 사용했었다. 하지만 이러한 재귀 호출문은 재귀적으로 함수를 호출할 때마다 함수의 중간 출력값을 스택 메모리에 매번 추가하게 된다. 그래서 상대적으로 일반적인 반복문이 재귀 호출문 보다 더 효율적이다. 따라서 우리는 방금 위에서 재귀호출문으로 작업했던 부분을 일반 반복문으로 변경해보도록 하자.
class Variable:
def __init__(self, data):
self.data = data
self.grad = None
self.creator = None
def set_creator(self, func):
self.creator = func
def backward(self):
funcs = [self.creator]
while funcs:
f = funcs.pop()
x, y = f.input, f.output
x.grad = f.backward(y.grad)
if x.creator is not None:
funcs.append(x.creator)
backward 메소드를 보면 리스트를 하나 새롭게 정의하고 이를 while 무한 루프로 처리한 것을 볼 수 있다. 그리고 추가적으로 순전파 시 창조자 함수에서 캐싱해두었던 해당 함수의 입력/출력 값을 가져와서 역전파 시 편리하게 사용하는 부분도 추가되었다.(잘 모르겠다면 바로 Step7의 마지막 코드블록이랑 코드를 비교해보자)
추가적으로 일반 반복문이 재귀 호출문보다 선호하는 또 다른 이유는 복잡한 계산 그래프를 다룰 때 확장성이 보다 뛰어나다는 점이다. 이에 대한 구체적인 이유는 다음 고지에서 배울 예정이다.
Step9. 함수를 좀 더 User-Friendly 하게 바꾸기
이번 스텝은 핵심보다는 약간 부가적인 배움일 수 있다. 지금까지 우리가 설계한 함수들의 사용자 편의성을 증가시키는 것이다. 크게 3가지를 개선할 예정인데, 첫 번째는 Functional API 형태에서 Python API 형태로 변경하는 것이다.
이전까지는 우리가 만든 제곱함수 클래스는 아래처럼 사용되었다.
import numpy as np
x = Variable(np.array(5.0))
# 함수 클래스 정의
A = Square()
a = A(x) # a = Square()(x)로 정의 가능 = Functional API
print(a.data)
위와 같은 방식은 Functional API 형태와 매우 유사하다. 따라서 우리는 아래처럼 새로운 함수를 하나 정의해서 Python API 형태로 바꾸어 주려고 한다.
def square(x):
return Square()(x)
x = Variable(np.array(0.5))
a = square(x)
print(a.data)
다음은 역전파를 수행할 때, 최초의 미분값 즉, $y$의 $y$에 대한 미분값으로서 1을 정의하는 부분을 생략해주려고 한다. Variable 클래스에 아래의 부분을 추가해주어 미분 초기값을 설정해주도록 하자.
class Variable:
def __init__(self, data):
self.data = data
self.grad = None
self.creator = None
def set_creator(self, func):
self.creator = func
def backward(self):
# 미분 초기값 설정
if self.grad is None:
self.grad = np.ones_like(self.data)
funcs = [self.creator]
while funcs:
f = funcs.pop()
x, y = f.input, f.output
x.grad = f.backward(y.grad)
if x.creator is not None:
funcs.append(x.creator)
마지막으로는 입력의 유효성 검증하는 코드를 추가하는 것이다. 현재 우리가 공부하고 있는 DeZero라는 프레임워크는 넘파이의 nd-array 형태만을 취급하는 것을 가정한다. 따라서 Variable 클래스에 변수의 유효성 검증 코드를 추가해주도록 하자.
class Variable:
def __init__(self, data):
if data is not None:
if not isinstance(data, np.ndarray):
raise TypeError(f"{type(data)} 타입은 지원하지 않습니다.")
self.data = data
self.grad = None
self.creator = None
def set_creator(self, func):
self.creator = func
def backward(self):
if self.grad is None:
self.grad = np.ones_like(self.data)
funcs = [self.creator]
while funcs:
f = funcs.pop()
x, y = f.input, f.output
x.grad = f.backward(y.grad)
if x.creator is not None:
funcs.append(x.creator)
그런데 여기서 한 가지 또 추가해주어야 하는 부분이 있다. 바로 넘파이의 독특한 관례 때문인데, 넘파이는 0차원의 array일 경우, 특정 연산을 수행하게 되면 넘파이의 nd-array에서 스칼라 값 형태로 바뀐다. 아래 코드를 수행해서 타입 체크를 한 번 해보자.
import numpy as np
a = np.array(10.0)
b = a ** 2
print(a, type(a)) # numpy.ndarray
print(b, type(b)) # numpy.float64
따라서 이러한 연산 결과로 dtype이 변경되는 것을 막기 위해 별도의 함수를 하나 새롭게 정의해주자. 그 함수는 단지 넘파이 스칼라 값을 nd-array 형태로 변환해주는 단순 기능 함수이다. 그리고 이를 Functions 공통 클래스에다가 추가해주어 특정 함수가 적용된 연산 결과값(output)에 적용해주어 혹시라도 넘파이 스칼라 값이 되었으면 nd-array로 변환될 수 있도록 해주자.
def as_array(x):
if np.isscalar(x):
return np.array(x)
return x
class Function:
def __call__(self, input):
x = input.data
y = self.forward(x)
output = Variable(as_array(y)) # 함수의 출력에 적용!
output.set_creator(self)
self.input = input
self.output = output
return output
def forward(self, x):
raise NotImplementedError("This method should be called in other function class")
def backward(self, gy):
raise NotImplementedError("This method should be called in other function class")
참고로 위 함수에서 사용되는 np.isscalar() 함수는 넘파이 스칼라 뿐만 아니라 파이썬의 float, int 형 값이 들어가도 True를 내뱉는다는 점도 알아두자.
Step10. 파이썬 단위 테스트(Unit Test)
SW개발에 있어서 단위 테스트는 필수적이다. 이는 딥러닝 프레임워크에도 동일하게 적용된다. 파이썬에서는 표준 라이브러리에 포함된 unittest 라이브러리를 사용해 유닛 테스트를 진행할 수 있다. 먼저 unittest 라이브러리의 TestCase라는 클래스를 상속받아야 한다. 또 특이한 점은 유닛 테스트 클래스를 정의할 때 메소드의 이름 prefix는 항상 'test'로 명시해주어야 한다.
그러면 먼저 간단하게 제곱 함수의 출력값이 잘 나왔는지 유닛테스트로 검증해보자.
import unittest
class SquareTest(unittest.TestCase):
def test_forward(self):
x = Variable(np.array(3.0))
y = square(x)
expected = np.array(4.0)
self.assertEqual(y.data, expected)
그리고 이 파일을 터미널에서 아래 명령어로 수행해보자.(파일 이름은 test.py라고 가정)
python -m unittest ./test.py
물론 이렇게 터미널에 추가 인자로 붙여주는 것 말고 유닛테스트 코드 맨 마지막 라인에 하단의 코드를 추가한 후 파이썬 파일을 실행하는 명령어로 수행도 가능하다.
import unittest
class SquareTest(unittest.TestCase):
def test_forward(self):
x = Variable(np.array(3.0))
y = square(x)
expected = np.array(4.0)
self.assertEqual(y.data, expected)
unittest.main()
# 이후 터미널에서 python ./test.py 로 실행 가능!
다음은 좀 더 발전적인 테스트 방법으로 기울기 확인을 해보는 테스트를 해보자. 앞서서 우리는 오차역전파로 계산한 기울기를 검증하기 위해서 동일한 미분 계산을 수치 미분으로 계산했을 때의 결과값과 비교한 후 차이가 적다면 오차역전파가 제대로 이루어진 것이라고 판단할 수 있다고 했다.(물론 차이가 얼마나 나야 적합한지에 대한 기준은 상황마다 다를 것이지만, 미세한 차이여야 할 것이다)
우리는 이미 저번 포스팅에서 수치 미분을 코드로 구현하는 방법에 대해 배웠다. 따라서 이미 구현한 수치 미분 함수를 가져와서 역전파를 사용해 계산한 결과와 수치 미분을 활용해 계산한 결과 간에 차이만 검증하면 된다.
def numerical_diff(f, x, eps=1e-4):
x0 = Variable(x.data - eps)
x1 = Variable(x.data + eps)
y0 = f(x0)
y1 = f(x1)
return (y1.data - y0.data) / (2*eps)
class SquareTest(unittest.TestCase):
def test_gradient_check(self):
x = Variable(np.random.rand(1))
y = square(x)
y.backward()
num_grad = numerical_diff(square, x)
flg = np.allclose(x.grad, num_grad)
self.assertTrue(flg)
위 함수에서 사용된 넘파이의 np.allclose 라는 함수는 두 배열의 차이가 얼마나 나는지 비교하고 허용 범위 이내면 True, 아니면 False를 내뱉는 함수다. 따라서 해당 함수의 인자로 허용 범위를 지정할 수 있다.
추가적으로 코드가 길어지고 서비스가 거대해짐에 따라 파트별로 여러가지 테스트 케이스를 한 번에 진행해야 할 수 있다. 그러면 일일이 파이썬 명령어를 실행하기가 매우 귀찮을텐데, 이를 한 번에 실행시켜주는 명령어도 존재한다.
python -m unittest discover [your directory]
위 명령어를 수행하면 되는데, 대괄호 안에 여러분이 유닛테스트를 진행할 코드가 들어있는 py 파일이 들어있으면 된다. 기본적으로는 지정한 디렉토리에서 이름이 'test'로 시작하는 모든 py 파일을 실행시킨다.(이 디폴트로 적용되는 값 'test' 도 변경할 수도 있다고 함)
이렇게까지 해서 3권의 첫 번째 고지가 끝이났다. 예전에 공부한 1,2권을 복습하는 느낌이 들면서도 내가 몰랐던 내용을 추가적으로 배우는 것 같아 알찼던 것 같다. 무엇보다 오픈소스로 공개되어 널리 사용되고 있는 딥러닝 프레임워크의 철학을 점점 이해할 수 있게 되는 게 신기하다. 이제 다음 고지를 정복해보도록 하자!
'Data Science > 밑바닥부터시작하는딥러닝(3)' 카테고리의 다른 글
| [밑시딥] 나만의 딥러닝 프레임워크 만들기, 고차 미분 계산(2) (0) | 2022.07.09 |
|---|---|
| [밑시딥] 나만의 딥러닝 프레임워크 만들기, 고차 미분 계산(1) (0) | 2022.06.11 |
| [밑시딥] 나만의 딥러닝 프레임워크 만들기, 더 복잡한 미분 자동 계산(2) (0) | 2022.05.22 |
| [밑시딥] 나만의 딥러닝 프레임워크 만들기, 더 복잡한 미분 자동 계산(1) (0) | 2022.04.24 |
| [밑시딥] 나만의 딥러닝 프레임워크 만들기, 미분 자동 계산(1) (2) | 2022.04.03 |



