🔊 이번 포스팅에는 최근에 Python으로 알고리즘을 공부하기 시작하면서 알게 된 여러 알고리즘의 원리와 Python으로 구현하는 방법에 대해 소개해보려 한다. 필자는 최근 알고리즘 공부를 '나동빈'님의'이것이 취업을 위한 코딩 테스트다 with 파이썬'이라는 책과 백준 온라인 저지 사이트로 하고 있다. 이 중 '나동빈'님이 저자이신 책에서 가르쳐주는 내용을 기반으로 배운 내용을 정리해보려 한다.
이번 포스팅에서는 저번에 알아보았던 '탐색' 알고리즘의 또 다른 종류인 순차 탐색(Sequential Search)과 이진 탐색(Binary Search) 알고리즘에 대해 알아보고 Python으로 구현하는 방법에 대해 알아보려고 한다.
1. 순차 탐색(Sequential Search)
순차 탐색은 리스트 또는 배열 내에서 특정 데이터를 찾기 위해 하나씩 차례대로 확인하는 방법을 의미한다. 아마 우리가 가장 흔하게 사용하는 방법이라고 할 수 있다. 순차 탐색은 보통 정렬되지 않고 무작위로 주어진 데이터 내에서 특정 원소를 찾을 때 자주 사용된다. 예를 들어 배열 내에 특정 원소 존재 여부를 체크한다거나 특정 원소 개수를 세는, Python으로 치면 count('value')와 같은 메소드가 있다.

순차 탐색은 정렬 여부에 상관없이 사용되므로 데이터 개수가 $N$개 일때 최악의 경우에 시간 복잡도 $O(N)$이 된다. 그러면 간단하게 Python으로 순차 탐색을 구현해 보자.
import sys
# 순차 탐색 구현
def sequential_search(n, target, array):
# 하나씩 target과 비교
for i in range(n):
if array[i] == target:
return i+1 # 인덱스가 아닌 '몇'번째 데이터인지 반환
array = [i for i in range(10, 30, 2)]
n = len(array)
target = 14
res = sequential_search(n, target, array)
print(f"{target} 데이터는 array의 {res}번째에 존재합니다!")2. 이진 탐색(Binary Search)
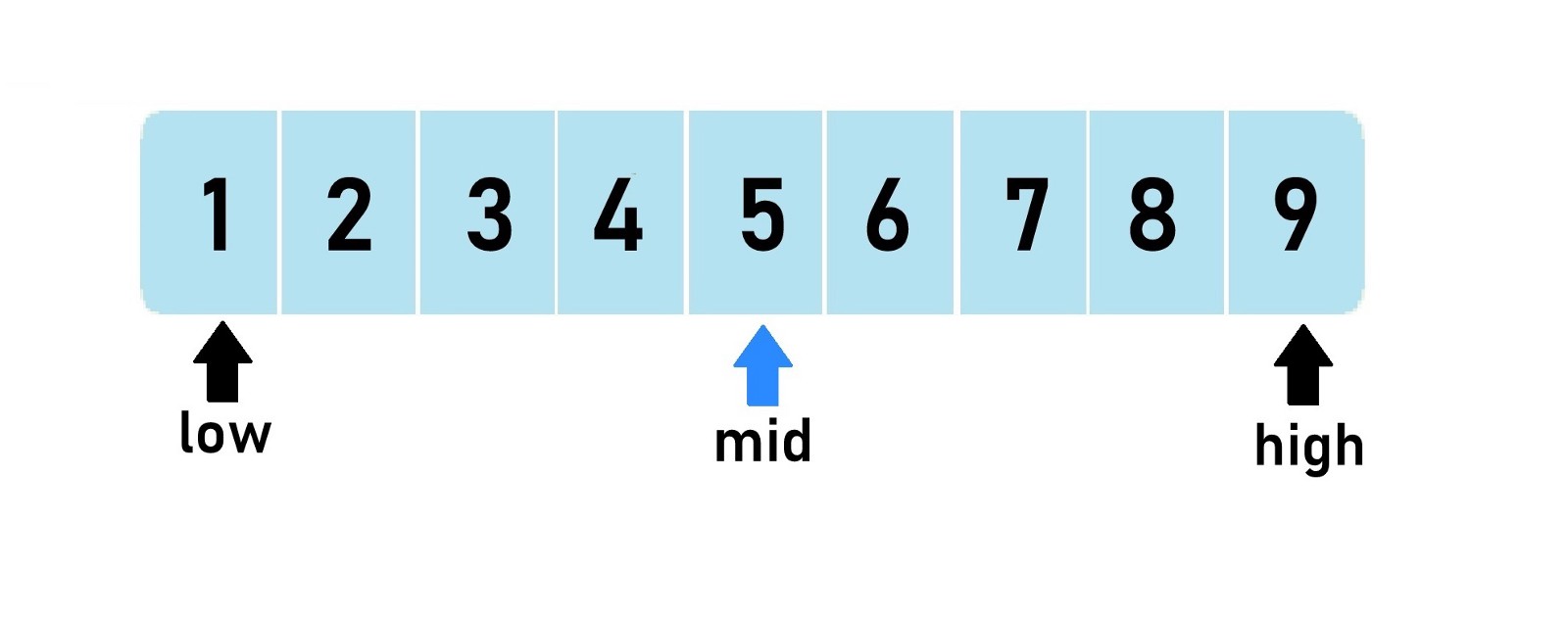
이진 탐색은 배열 데이터가 정렬 되어있을 경우에만 사용이 가능하다. 이진 탐색은 3가지의 변수를 사용해서 구현되는데, 배열의 시작점, 배열의 끝점, 배열의 중간점을 사용한다. 결국 찾으려는 데이터와 중간점에 있는 위치의 데이터와 반복적으로 비교한다. 그리고 중간점 위치를 계속 옮겨다니면서 특정 데이터를 찾아낸다.

위 과정을 보다시피 이진 탐색은 이상적으로라면 데이터를 확인하는 연산 횟수를 매번 절반 줄어들게 하는 효과가 있다. 그래서 시간 복잡도가 $(logN)$이 되게 된다. 연산 횟수를 매번 줄어들게 하는 효과가 있기 때문에 입력 데이터가 매우 많거나 탐색 범위가 매우 넓을 때, 구체적으로는 데이터 개수가 1,000만 단위 이상 또는 탐색 범위가 1,000억 이상일 때 자주 사용된다.
이진 탐색을 Python으로 구현하는 방법에는 크게 2가지가 있다. 재귀함수를 사용하거나 while 반복문을 사용하는 방법이다. 하나씩 살펴보자.
import sys
# 1.재귀함수로 구현
def binary_search(array, target, start, end):
if start > end:
return None
middle = (start + end) // 2
if array[middle] == target:
return middle + 1
elif array[middle] < target:
return binary_search(array, target, middle+1, end)
else:
return binary_search(array, target, start, middle-1)
n, target = list(map(int, input().split()))
array = list(map(int, input().split()))
result = binary_search(array, target, 0, n-1)
if result == None:
print("존재하는 원소가 없습니다!")
else:
print(result)
import sys
# 2.while 반복문으로 구현
def binary_search(array, target, start, end):
while start <= end:
middle = (start + end) // 2
if array[middle] == target:
return middle + 1
elif array[middle] < target:
start = middle + 1
else:
end = middle - 1
n, target = list(map(int, input().split()))
array = list(map(int, input().split()))
result = binary_search(array, target, 0, n-1)
if result == None:
print("존재하는 원소가 없습니다!")
else:
print(result)
위 예시에서 입력 데이터를 받을 때 input() 메소드를 사용했지만 위에서 말했다시피 데이터 개수 또는 탐색 범위가 엄청나게 커질 때는 sys 라이브러리를 사용하는 것이 좋다. 하단은 sys 라이브러리를 사용한 예시이다.
import sys
# 2.while 반복문으로 구현
def binary_search(array, target, start, end):
while start <= end:
middle = (start + end) // 2
if array[middle] == target:
return middle + 1
elif array[middle] < target:
start = middle + 1
else:
end = middle - 1
n, target = list(map(int, sys.stdin.readline().rstrip()))
array = list(map(int, sys.stdin.readline().rstrip()))
result = binary_search(array, target, 0, n-1)
if result == None:
print("존재하는 원소가 없습니다!")
else:
print(result)
참고로 sys.stdin.readline() 메소드는 끝에 Enter 공백 문자 \n을 포함하기 때문에 꼭 rstrip() 을 붙여주는 것을 잊지말자.
'Python > 알고리즘 개념' 카테고리의 다른 글
| [Python] 우선순위 큐를 활용한 개선된 다익스트라(Dijkstra) 알고리즘 (6) | 2021.09.23 |
|---|---|
| [Python] 최단경로를 위한 다익스트라(Dijkstra) 알고리즘 (0) | 2021.09.22 |
| [Python] 알고리즘을 위한 주요 라이브러리와 유의점 (0) | 2021.09.14 |
| [Python] Dynamic Programming(동적계획법) 알고리즘 (0) | 2021.04.14 |
| [Python] DFS/BFS 탐색 알고리즘과 다양한 정렬 알고리즘 (2) | 2021.04.03 |



