앞으로 전개할 내용은 Coursera 딥러닝 강의의 내용을 기반으로 필자가 직접 정리하는 내용이며 해당 컨텐츠 이외의 다른 강의에 관심이 있다면 여기를 참고해 수강해보자.
이번 포스팅에서는 CNN 모델을 좀 더 발전시킨 ResNet(Residual Network)와 Inception Network에 대해 알아보려고 한다. 참고로 두 모델들에 대한 자세한 수학적인 수식들은 배제하고 두 모델의 구조가 어떤 구조이고 어떤 프로세스를 따라서 동작하는 지에 좀 더 초점을 맞추어 설명하려고 한다.

1. ResNet(Residual Network)
우선 RestNet에 대해 이해하기 전에 Residual block에 대한 이해가 필요하다. Residual의 사전적 의미는 '잔여', 수학적으로는 '잔차'라는 의미로 사용된다. 결론부터 말하면 이 Residual block을 추가하는 이유는 딥러닝의 주요 문제인 기울기가 소실되거나 발산하는 'Vanishing / Exploding gradients' 문제를 해결하기 위함이다. 그럼 CNN에서 Residual 이란 무엇을 의미할까? 다음 그림을 살펴보자.

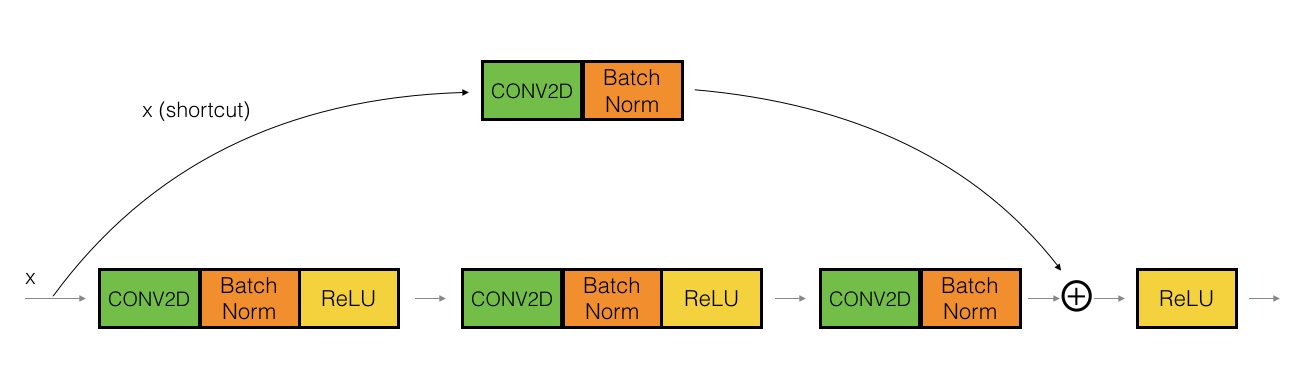
위 그림과 같은 3개의 layer가 존재하는 CNN모델의 일부가 있다고 가정하자. x에 이미지 데이터가 입력될 것이며 Convolution 연산을 거친다. 우리가 주목해야 할 부분 'shortcut'이라고 나타내는 부분과 빨간색 네모칸이다. 빨간색 네모칸은 x라는 입력 데이터가 2번의 Convolution 연산을 거치고 난 후 3번째 Convolution을 계산할 차례이다.
그런데 특이한 점이 한 가지 있다. 바로 3번째 Convolution 연산과 Batch Normalization을 거치고 난 후 도출된 결과값에 '무엇'인가를 더해주고 있다. 이 '무엇'이 어디서 왔는지 추적하기 위해 화살표를 역으로 따라가 보면 입력 데이터의 값이라는 것을 알 수 있다.
평범한 CNN의 같은 경우에는 3번째 컨볼루션을 거치고 난 결과값에 바로 Relu라는 비선형 함수로 활성함수를 취할텐데 ResNet은 활성함수를 취하기 이전에 입력 데이터의 값을 더해주고 난 후 활성함수를 취하는 것이다. 물론 위 예시 같은 경우는 더해주는 값이 입력 데이터이지만 밑의 그림과 같이 중간 layer의 활성함수를 전달해도 무방하다.

이렇게 입력 데이터 또는 이전의 layer로 나온 결과값을 그대로 이후의 layer에 전달하는 과정을 Shortcut 또는 Skip connection 이라고도 부른다.
그런데 위와 같은 전달 방법은 한 가지 문제라고 할 수 있는 것이 있다. Convolution은 애초에 입력 데이터의 사이즈를 줄여주는 Convolution을 수행하거나 Pooling을 수행함으로써 진행을 하게 된다.(물론 1 by 1 Convolution만을 사용하면 사이즈는 줄지 않지만 보통은 사이즈를 줄이는 것이 CNN의 목적이다) 그렇게 된다면 몇 단계 이전의 layer에서 결과를 얻은 a_1(1번 layer에서 얻은 activation 값)의 차원 수는 이 a_1을 shortcut으로 전달하려는 뒤 쪽 layer의 z_3(3번 layer에서 얻는 컨볼루션 후의 값. 아직 활성함수를 취하기 이전의 상태)과 차원 수가 다를 가능성이 있어 연산이 불가능할 수 있기 때문이다.
결론적으로는 Residual Block을 만들기 위해 더하기(+)연산을 하는 데 있어서 차원의 불일치 문제가 발생할 수 있기 때문에 다음과 같은 shortcut 구조를 사용하기도 한다.
위 그림에서 보는 것처럼 shortcut으로 전달하려는 x에 Convolution을 적용해 이후 layer의 z값과 사이즈를 일치시켜주는 것이다. 그래서 만약 위와 같은 과정을 수행하고 싶지 않다면 전달하려는 a_1값이 존재하는 layer에서 이 a_1값을 전달 받을 이후의 layer로 신경망이 진행될 때는 동일한 사이즈로 Convolution을 진행해주는 것이 좋다. 그래야 차원 불일치 문제가 발생하지 않을 것이다.
2. Inception Network
인셉션 네트워크를 이해하기에 앞서 한 가지 특이한 컨볼루션 사이즈 형태를 소개한다. 바로 1 by 1 사이즈의 Convolution 연산이다. 1 by 1 Convolution은 입력 데이터 사이즈를 줄이지 않고 channel 개수(또는 filter 개수)만을 늘리거나 줄이기 또는 유지하기 위해서 자주 사용된다. 좀 더 직관적으로 이해하기 위해 다음 그림을 살펴보자.
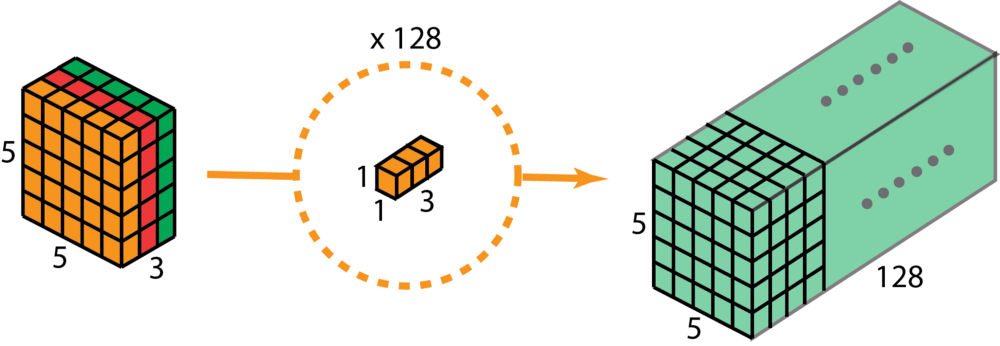
그림의 왼쪽처럼 입력 데이터 이미지가 (5, 5, 3)의 3차원 형태를 하고 있다. 즉 높이가 5, 너비가 5, (컬러이미지라 가정한 후)channel 개수가 3이다. 여기에다가 높이가 1, 너비가 1, channel은 3개 즉, (1, 1, 3) 사이즈의 커널을 적용하면 어떻게 될까? 이 때 (1, 1, 3) 커널로 만들 총 필터 개수는 128개이다.
연산 결과는 오른쪽 초록색 직육면체와 같다. 즉 사이즈가 (5, 5, 128)이 되었는데, 이는 결국 입력 데이터의 높이와 너비 사이즈를 줄이지 않고 필터의 개수만 늘려 (5, 5, 3) 에서 (5, 5, 128)이 되었음을 의미한다.
그렇다면 이 1 by 1 Convolution을 대체 왜 사용할까? 바로 정보를 손실하지 않으면서 계산해야 할 파라미터 개수를 줄여줌으로써 컴퓨팅 연산량을 줄일 수 있기 때문이다. 이러한 특성을 갖는 컨볼루션을 사용하는 것이 Inception Network이고 결국 Inception Network도 내세우는 장점은 바로 학습할 파라미터 개수를 이전에 논문에서 소개되었던 LeNet, AlexNet, VGG-16 보다 훨씬 더 줄일 수 있다는 것이다.
그러면 어떻게 1 by 1 Convolution이 파라미터 개수를 줄이는지 간단한 예시그림을 통해서 알아보자.
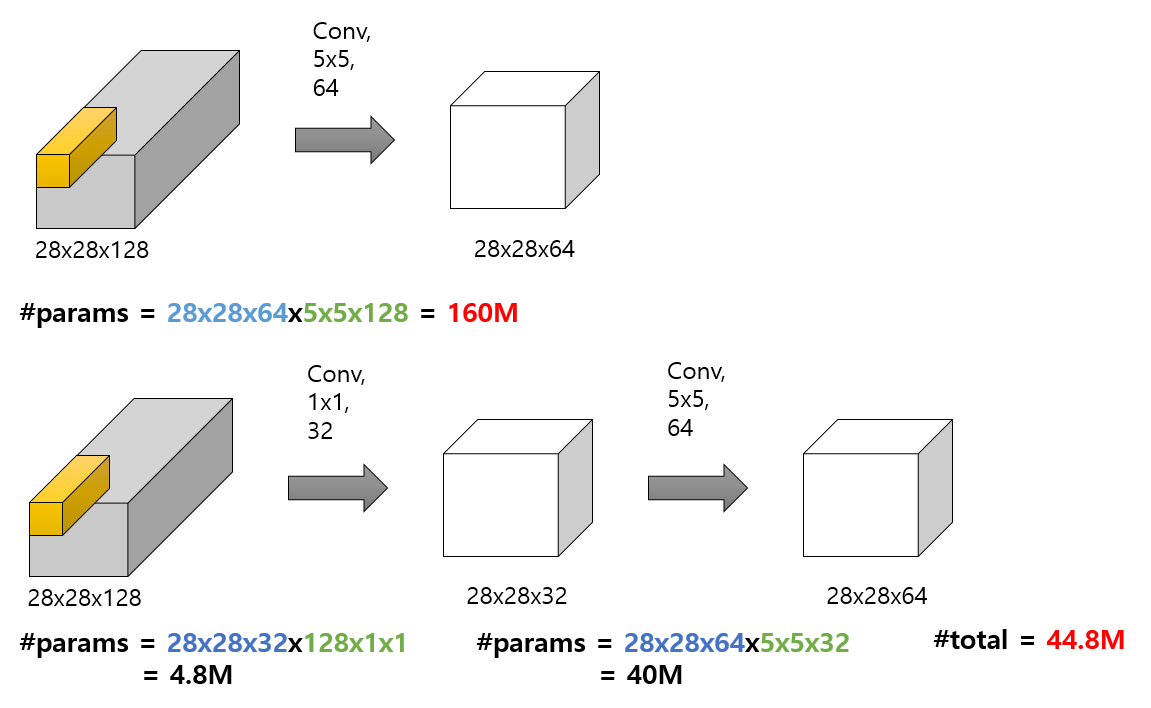
우선 첫 번째 그림은 일반적인 CNN 처럼 5 by 5 Convolution을 사용하여 64개의 필터개수를 설정해 (28, 28, 64) 사이즈의 결과값이 도출되었다. 이 컨볼루션 연산을 하는 과정에서 계산해야 할 파라미터 개수는 1억 6천만개가 된다.(160M, M은 million을 의미)
반면에 두 번째 그림은 동일한 사이즈의 입력 데이터를 1 by 1 Convolution을 먼저 사용하고 난 다음 5 by 5 Convolution을 사용한 연산 결과이다. 컨볼루션 결과 데이터의 사이즈를 첫 번째 그림과 비교해보면 (28, 28, 64) 로 동일한 사이즈이다. 그런데 두 번째 그림의 계산해야 할 파라미터 개수를 보면 4천 480만개가 된다. 결국 1 by 1 Convolution을 중간에 이용하게 되면 컴퓨팅 연산을 엄청나게 줄일 수 있다. 어떤 사람들은 1 by 1 Convolution을 사용하게 되면 정보 손실량이 발생할 거라고 생각할 수 있는데 오히려 정보 손실량을 발생시키지 않으면서 컴퓨팅 연산을 줄여서 많은 컴퓨터 비전 연구원들이 사용하고 있다고 한다. 그리고 여담이지만 1 by 1 Convolution은 위 처럼 입력 데이터와 일반 Convolution 사이에 끼어 있다고해서 bottle neck 이라고 불리기도 한다.
자 이제 이 1 by 1 Convolution이 고안되어 어떻게 Inception Network를 구성하기로 결정한 것인지 살펴보자.
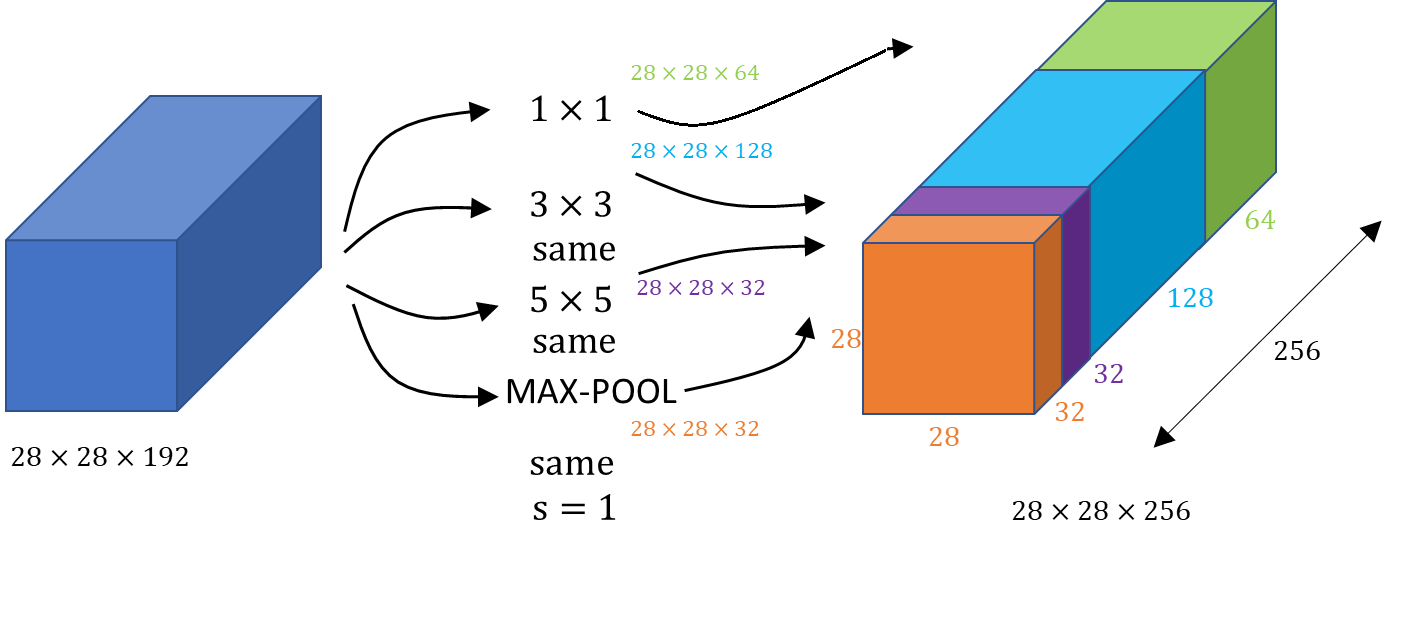
위 그림과 같이 (28, 28, 192) 사이즈를 갖는 입력 데이터가 있다고 가정하자. 이 입력 데이터를 높이와 너비 사이즈는 유지한 채 총 3번의 컨볼루션과 1번의 Max-pooling 연산을 수행해준다. 그리고 연산을 수행해준 각 결과값들은 높이와 너비가 모두 28 by 28로 같이 때문에 오른쪽 그림처럼 channel 축 방향으로 모두 합쳐준다. 이러한 아이디어로부터 Inception Network가 개발되기 시작했다. 그렇다면 실제 자주 사용되는 Inception Module을 예시로 하나 살펴보자.

위 그림에서 보는 것처럼 일반 Convolution들 사이에 1 by 1 Convolution을 사이에 사용하고 Max pooling을 적절히 활용해 위와 같이 Inception Module을 만들 수 있다. 이러한 Inception Module이 여러개 합쳐져 매우 거대한 신경망인 Inception Network를 만들 수 있다.

위와 같이 거대한 Inception Network를 만들 수 있는데, 중간에 Auxillary Classifiers에 대해서 언급하고 이야기를 마무리 하려 한다. Auxillary Classifiers는 일명 '곁가지 분류기'로 Inception Network는 매우 깊은 신경망이기 때문에 중간에 Vanishing Gradient 문제를 방지하기 위해서 설치된 모델들이다. 즉, 각 Auxillary Classifiers 내부 역전파로 인한 기울기값이 Inception Network의 역전파 수행시 기울기 값에 더해져 기울기 소실 문제를 예방한다는 것이다. 이 Auxillary Classifiers에 대한 자세한 내용은 여기를 참고해보자.
'Data Science > Computer Vision' 카테고리의 다른 글
| [ML] Fast RCNN Object Detection 모델 (0) | 2021.04.13 |
|---|---|
| [ML] SPP(Spatial Pyramid Pooling) Object Detection 모델 (2) | 2021.04.11 |
| [ML] RCNN(Regions with CNN) Object Detection 모델 (0) | 2021.04.10 |
| [ML] Object Detection 기초 개념과 성능 측정 방법 (3) | 2021.04.08 |
| [ML] Convolutional Neural Network(CNN) (0) | 2020.10.07 |



