이번 포스팅에서는 Scikit-learn을 이용해 데이터의 feature를 engineering 하는 간단한 방법들에 대해 알아보려고 한다. 그동안 다양한 feature engineering 방법을 이론적으로나마 배워왔다. 수많은 feature engineering 방법들이 존재하고 지금도 새롭고 놀라운 방법들이 개발되고 있지만 모든 방법을 다루지는 못한다. 따라서 이번 글에서는 간단한 몇 가지 방법들만 살펴보고 코드로 구현해보려고 한다. 소개할 feature engineering 방법들은 다음과 같다.
1. 편향된 분포를 정규분포화 시켜주기 위한 log 변환
2. 이상치(Outlier) 제거하기
3. SMOTE를 이용한 Oversampling 하기
1. 편향된 분포를 정규분포화 시켜주기 위한 log 변환
많은 통계적인 기법들은 데이터의 분포가 정규분포임을 가정한 상태에서 만들어졌다. 따라서 만약 특정 데이터의 분포가 정규분포가 아닌 편향된 분포(멱함수 분포라고도 부른다.) 모양을 띈다면 이를 정규분포화 시켜주어야 하는 사전 작업이 필수적이다.
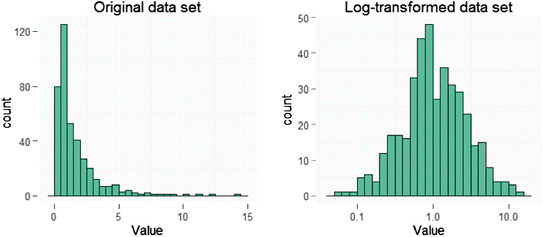
위 그림의 오른쪽 그래프처럼 원본 데이터의 분포가 편향된 분포를 띄고 있을 때, 우리는 Log 변환을 취해서 데이터의 분포를 정규분포화 시켜줄 수 있다. 또한 log뿐만 아니라 sqrt(제곱근) 변환을 주어서 편향된 분포를 정규분포로 변환시켜 줄 수도 있다.
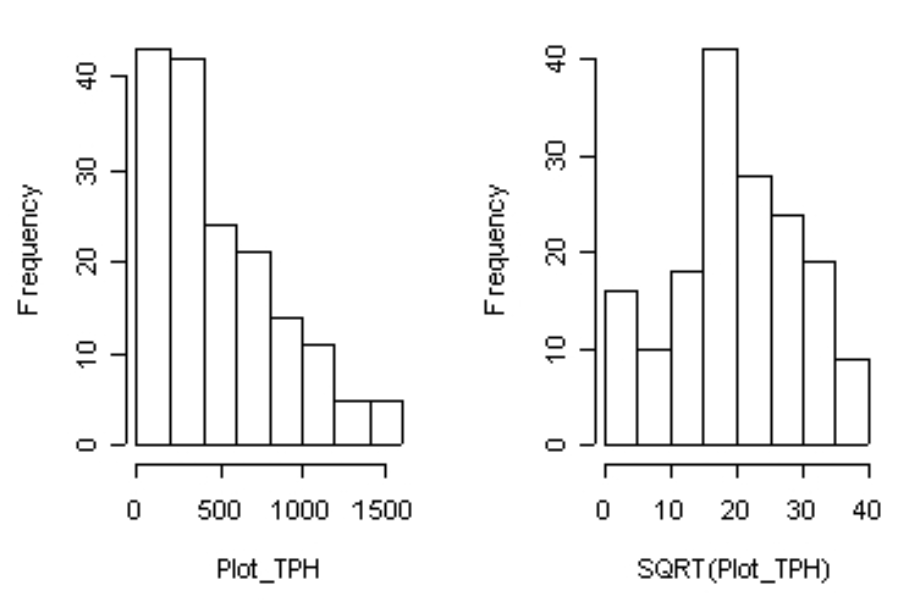
그렇다면 이를 Python으로 구현한다면 어떻게 될까? 우선 다음과 같은 원본 데이터의 Amount라는 중요한 변수의 분포를 살펴보자.(여기서 중요한 변수란, label에 큰 영향을 미칠 것으로 예상되는 변수이다. 예를 들어 카드 사기(Fraud) 거래를 분류하기 위해서 카드 거래 금액은 중요한 변수가 될 것이다. 왜냐하면 비이상적으로 엄청나게 큰 금액인 경우에 사기 거래인 경우가 많기 때문이다.)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
card_df = pd.read_csv('creditcard.csv', encoding='utf-8')
card_df.shape
plt.figure(figsize=(8,4))
plt.xticks(range(0, 30000, 1000), rotation=60)
sns.distplot(card_df['Amount'])결과값은 다음과 같다. 매우 편향된 분포를 띄는 것을 볼 수 있다.

이제 Amount값에 log를 취한 다음 분포를 그래프로 그려보자.
import seaborn as sns
import matplotlib.pyplot as plt
# Amount에 log변환을 취해서 분포도 변환시킨후 학습시키기
def get_preprocessed_df(df):
df_copy = df.copy()
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_log', amount_n)
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
return df_copy
card_df = get_preprocessed_df(card_df)
plt.figure(figsize=(8,4))
plt.xticks(range(0, 30000, 1000), rotation=60)
sns.distplot(card_df['Amount_log'])결과값은 다음과 같다. 이전보다 좀 더 정규분포 형태로 변환된 것을 볼 수 있다.

2. 이상치(Outlier) 제거하기
이상치란, 자연스럽거나 기계적으로 발생하는 극단적인 값을 의미한다. 물론 이상치를 섣불리 무조건적으로 제거하는 것은 바람직하지 않지만 불필요한 데이터로 판단된다면 이상치에 포함하는 범위를 설정해주고 이 범위를 벗어나는 값들을 모두 제거해준다. 보통 범위를 설정하기 위해서는 IQR(사분위수)을 사용하는데 사분위수란, 제3사분위수에서 제1사분위수를 뺀 값을 의미한다.
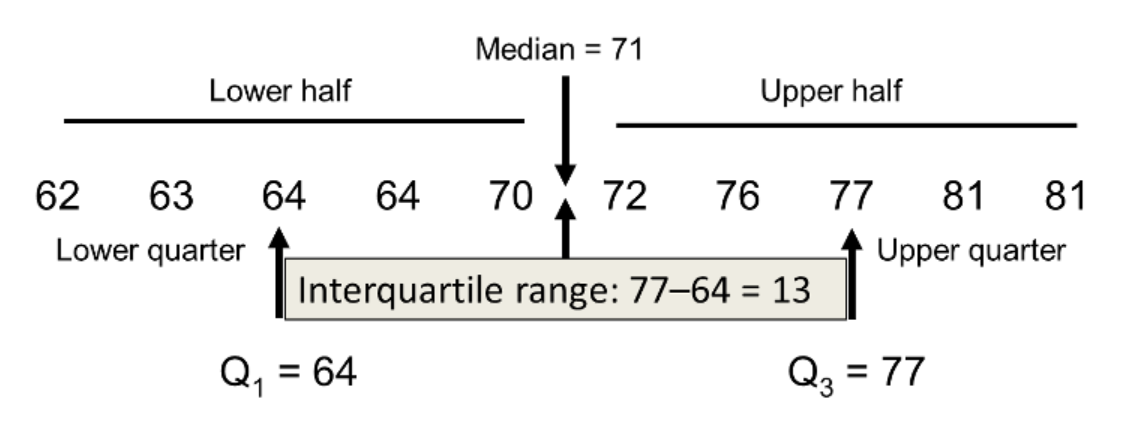
우선 주어진 데이터의 여러가지 변수(feature)들 중에서 이상치를 제거할만한 변수를 선정하기 위해 독립변수들과 종속변수간의 상관관계를 고려한 후 상관관계가 높은 데이터에 이상치가 존재하면 핸들링해줄 필요가 있다. 먼저 코드상으로 상관관계를 살펴보자.
# 이상치 제거후 모델 학습 평가해보기
# 우선 class와 상관관계가 높은 변수를 기준으로 이상치를 제거하자
# 그러기 위해서 상관관계 살펴보기
plt.figure(figsize=(10,8))
corr = card_df.corr()
sns.heatmap(corr, cmap='Blues')결과값을 heatmap으로 표현해보았다. Class와 가장 상관관계가 높은 데이터로는 V4, V11 feature정도 되겠다. 이번 예시에서는 V11 feature에 대한 이상치를 제거해보는 작업을 해보자.

이상치의 범위를 설정하고 이 범위를 벗어나는 값들의 index를 반환받아 원본 데이터에서 해당 index의 데이터들을 삭제해주자.
# V11이 가장 상관관계가 높으므로 해당 변수의 이상치를 제거해보자.
# weight값은 이상치에 포함되는 범위 결정할 때 곱해주는 계수값
def get_outlier(df, column, weight=1.5):
# 사기에 해당하는 데이터들 중 해당 변수에 해당하는 값들만 출력
fraud = df[df['Class'] ==1][column]
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
# IQR을 구하고 1.5를 곱해서 이상치 포함시킬 범위 정의
iqr = quantile_75 - quantile_25
iqr_w = iqr * weight
lowest = quantile_25 - iqr_w
highest = quantile_75 + iqr_w
outlier_idx = fraud[(fraud < lowest) | (fraud > highest)].index
return outlier_idx
outlier_idx = get_outlier(card_df, 'V11')
df_copy.drop(outlier_idx, axis=0, inplace=True)3. SMOTE를 이용한 Oversampling 하기
다음은 오버샘플링을 하는 방법이다. 오버샘플링이란, Class imbalance가 존재할 때, 전체 Class개수 중 비율이 매우 적은 Class의 데이터들을 Class 개수가 많은 데이터의 개수만큼 이른바, '뻥튀기'하는 작업이다. 오버샘플링은 Up-sampling 이라고도 불리운다. 이 두개의 용어에 대한 차이점이 무엇인지 또 Under, Down-sampling이 무엇인지 궁금하다면 여기를 참고하자.
우리는 오버샘플링을 적용하기 위해 Scikit-learn에서 제공하는 SMOTE(Synthetic Minority Over-sampling Technique)를 사용하려 한다. SMOTE는 원본 데이터에 KNN(최근접 이웃 방식)으로 비슷한 Class의 데이터들을 임의로 증식시키는 방법이다.

SMOTE는 친절하게도 Scikit-learn에서 라이브러리를 제공하고 있으며 간단한 구현 코드는 다음과 같다.
# SMOTE(KNN에 기반한 오버샘플링) 적용 후 모델 학습
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
# train 데이터에서 오버샘플링 시키기
x_train_over, y_train_over = smote.fit_sample(x_train, y_train)
# 오버샘플링 적용 후 데이터 레이블 개수 살펴보기
print('오버샘플링 전 :', x_train.shape, y_train.shape)
print()
print('오버샘플링 후 :', x_train_over.shape, y_train_over.shape)
print()
print('오버샘플링 전 레이블 분포 :\n', pd.Series(y_train).value_counts())
print()
print('오버샘플링 후 레이블 분포 :\n', pd.Series(y_train_over).value_counts())과연 오버샘플링 전, 후 Class 분포가 어떻게 변화했는지 결과물을 살펴보자. 0이라는 label 개수가 label 1의 개수만큼 증식되었음을 확인할 수 있다.

'Data Science > Machine Learning 구현' 카테고리의 다른 글
| [ML] Scikit-learn을 이용한 PCA 구현하기 (2) | 2020.08.09 |
|---|---|
| [ML] Regression metric과 Polynominal Regression 구현하기 (2) | 2020.08.05 |
| [ML] Scikit-learn을 이용한 Stacking 구현하기 (4) | 2020.08.03 |
| [ML] Scikit-learn을 이용해 Ensemble 모델들 구현하기 (0) | 2020.07.30 |
| [ML] Precision 과 Recall의 Trade-off, 그리고 ROC Curve (0) | 2020.07.27 |



